

611
.pdfТребуется провести очистку результатов натурных наблюдений процесса покрытия полов линолеумом с помощью програм-
мы «Natura» (табл. 1.4).
Таблица 1.4
Покрытие полов линолеумом
|
|
Продолжительность выполнения |
|
|||||||
Наименование операции |
|
|
|
операции, мин |
|
|
|
|||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
Очистка основания от пыли |
5,7 |
4,7 |
4,0 |
4,0 |
4,0 |
4,8 |
4,5 |
4,2 |
4,0 |
4,0 |
Огрунтовка (при надобности) |
6,5 |
3,5 |
3,0 |
4,0 |
3,0 |
3,6 |
3,6 |
4,1 |
3,5 |
4,0 |
Раскрутка рулонов, разметка и нарезка |
5,2 |
5,4 |
6,0 |
5,8 |
5,8 |
5,8 |
6,0 |
6,0 |
5,6 |
5,6 |
полотнищ линолеума вручную |
|
|
|
|
|
|
|
|
|
|
Пригонка и наклейка полотнищ к |
4,5 |
3,7 |
4,0 |
4,0 |
4,0 |
4,0 |
3,7 |
3,7 |
4,5 |
4,5 |
выступающим частям помещения |
|
|
|
|
|
|
|
|
|
|
Приготовление клея и клеевой мастики |
2,6 |
2,7 |
2,0 |
2,5 |
2,5 |
2,5 |
3,0 |
2,0 |
2,4 |
2,2 |
Для расчета необходимо выполнить следующую последова-
тельность команд: Пуск Программы Натурные испытания Натурные испытания – и нажать клавишу Enter. Исход-
ные данные для работы программы должны быть подготовлены в форме табл. 1.5 и 1.6.
Таблица 1.5
Исходные данные программы «Natura»
|
|
Показатель |
|
|
|
Обозначение |
|
||
|
Наименование задачи |
|
|
|
|
Задача |
|
||
|
Количество факторов |
|
|
|
|
M |
|
||
|
Количество испытаний |
|
|
|
|
N |
|
||
|
|
Матрица натурных испытаний |
Таблица 1.6 |
||||||
|
|
|
|||||||
|
Номер испытания |
|
|
|
Фактор |
|
|||
|
1 |
… |
i |
|
… |
N |
|||
|
|
|
|
||||||
|
1 |
|
X11 |
… |
X1i |
|
… |
X1N |
|
|
… |
|
… |
… |
… |
|
… |
… |
|
|
i |
|
Xi1 |
… |
Xii |
|
… |
XiN |
|
|
… |
|
… |
… |
… |
|
… |
… |
|
|
M |
|
XM1 |
… |
XMi |
|
… |
XMN |
|
Далее в меню программы выполните следующие операции:
Расчет Исходные данные – и нажмите клавишу Enter.
Задайтеколичествофакторов МичислоиспытанийN.Щелкните два раза левой клавишей мыши на позиции меню Таблица испытаний и откройте таблицу (по умолчанию указан файл
11
Испытания.db). Внесите подготовленные данные в таблицу, приэтомиспользуйтеописанныенижекоманды,закрепленныеза клавишами.
Для удаления любой строки необходимоустановить курсор в этустроку таблицы и нажать клавиши Ctrl – Delete. Для вставки дополнительной строки щелкните клавишей Insert. Для полной очистки таблицы нажмите клавиши Ctrl – D. При наборе таблицы перейти в другуюячейку можнос помощью клавиши Tabили мыши. Добавить новую запись в таблицу можно также, используя клавишу .
Послевводазначенийматрица натурныхиспытанийсохраня-
ется в базе данных нажатием кнопки  в меню программы.
в меню программы.
При выходе из таблицы галочка не должна быть выделена черным цветом.
Для выполнения расчета установите курсор на элемент меню Выполнить расчет и нажмите левую клавишу мыши. На экране появится новое окно Открытие файла. Укажите имя файла, куда поместятся результаты (по умолчанию указан файл Результаты.txt), и нажмите кнопку Открыть. Программа выполнитрасчет, и наэкранепоявятсярезультаты. Длясохранения результатов в Word с помощью пункта меню Правка выделите данные, скопируйте их в буфер, откройте документ Word и вставьте результаты расчета в нужное вам место.
В прил. А приводится распечатка промежуточных этапов очистки рядов и окончательных результатов натурных испытаний, помещенных в документ Word. Результатами работы программы являются: N – число членов ряда; Xmin – минимальное значение ряда; Xmax – максимальноезначение ряда; Xср – среднее арифметическое значение ряда; E – средняя квадратическая ошибка; Кр – коэффициент разброса значений ряда.
1.3. Определение основных характеристик рядов наблюдений. Программа«Sample»
Проверка обоснованности значений ряда является первым шагом обработки натурных наблюдений. Полученный на этом этапе очищенный от случайных ошибок наблюдения статистический ряд можно отнести к одному из двух видов: простой ряд данных и вариационный ряд данных. Ввариационном рядудан-
12

ныесгруппированыпоколичественномупризнаку,например,по повторяемости значений данного ряда.
Следующим шагом в анализе рядов является определение основных обобщающих показателей, именуемых характеристиками ряда [2–4].
Наиболее часто встречающимся в статистике видом средних величин является средняя арифметическая величина, представляющая собой частное от деления суммы значений всех вариантов на общее число единиц, т.е. если отдельные варианты (значения признаков) обозначить через х, а среднюю из них – через x, то для несгруппированных данных она рассчитывается по формуле
x x n
и именуется простой средней арифметической.
Для вариационного ряда (сгруппированных данных) каждое значение признака (варианта) суммируется с учетом его частот, т.е. «взвешивается». Отсюда и название этой средней – средняя арифметическая взвешенная. Она вычисляется по формуле
|
|
хf |
|
х |
, |
(1.10) |
|
|
|
f |
|
где f – вес вариантов.
Среднее линейное отклонение представляет собой среднюю арифметическую из абсолютных значений отклонений отдельныхвариантовотсредней.(Знакиотклоненийигнорируются,так как в противном случае сумма всех отклонений будет равна нулю.)
Если обозначить среднее линейное отклонение буквой d, то длянесгруппированныхданных
|
|
|
|
|
|
|
|
|
|
||
|
|
|
x x |
|
|
(1.11) |
|||||
d |
, |
||||||||||
|
|
|
|
|
|
||||||
а для вариационного ряда |
|
|
n |
|
|||||||
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
x |
|
|
f |
|
||
|
|
|
|
x |
|
|
|||||
d |
|
||||||||||
|
|
|
|
. |
(1.12) |
||||||
|
|
||||||||||
|
|
|
f |
|
|||||||
13
Вторым показателем, измеряющим вариацию всех значений признаков вокруг своей средней, является среднее квадратическоеотклонение,или, как егочастоназывают, стандартноеотклонение, обозначаемое буквой (сигма). Среднее квадратическое отклонение для несгруппированных данных определяется поформуле
|
x |
x |
2 |
(1.13) |
, |
||||
|
n |
|
||
а для вариационного ряда – по формуле
|
x |
x |
2 f |
(1.14) |
. |
||||
|
f |
|
||
Среднее квадратическое отклонение является наиболее распространеннымиобщепринятымпоказателемдлявариации.Оно несколькобольшесреднеголинейногоотклонения.Дляумеренно ассиметричных распределений установлено следующее соотношение между ними:
= 1,25d. |
(1.15) |
Средняя арифметическаяиз квадратов отклонений, т.е. выра-
жение под корнем |
x |
x |
2 |
x |
x |
2 f |
|
|
|
|
или |
|
|
, носит название |
|
|
n |
|
f |
||||
дисперсии. Дисперсия ( 2) |
имеет самостоятельное значение в |
||||||
статистике и относится к числу важнейших показателей вариациизначенийряда.
Коэффициент вариации используют для сравнения рассеиваниядвухи болеепризнаков, имеющихразличныеединицыизмерения. Коэффициент вариации представляет собой относительнуюмерурассеивания, выраженную впроцентах, и вычисляется
поформуле |
|
||||
V |
|
|
100%. |
(1.16) |
|
|
х |
|
|||
|
|
|
|
|
|
Стандартное отклонение используют при расчете стандартной ошибки среднегоарифметического, при построении доверительных интервалов, статистической проверке гипотез, измерениилинейнойвзаимосвязимеждуслучайнымивеличинами:
14

|
i n |
|
|
|
|
|
|
|
|
||
|
xi |
x |
2 |
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
2 |
|
(1.17) |
|||
s |
i 1 |
|
|
, |
|||||||
n 1 |
n 1 |
|
|
||||||||
|
|
|
|
|
|
|
|||||
где s – стандарт, стандартное отклонение, несмещенная оценка среднеквадратическогоотклонения случайной величины xотносительно ее математического ожидания; – среднеквадратическое отклонение; 2 – дисперсия; xi – i-й элемент ряда; x – среднее арифметическое выборки; n – объем ряда.
Следует отметить отличие стандарта (в знаменателе n – 1) от корня из дисперсии (в знаменателе n): при малом объеме выборки оценка дисперсии через последнюю величину является несколько смещенной, при бесконечно большом объеме выборки разница между указанными величинами исчезает.
Правило трех сигм (3 ) гласит: практически все значения нормально распределенной случайной величины лежат в интервале 3 . Более строго: не менее чем с 99,7 % достоверностью значениенормальнораспределеннойслучайнойвеличинылежит вуказанном интервалепри условии, чтовеличина x истинная, а не полученная в результате обработки выборки.
Если же истинная величина неизвестна, то следует пользоваться не , а s. Таким образом, правило 3 преобразуется в правило3s.
Вид (закон) теоретического распределения подбирается исходя из вида гистограммы. Поэтому перейдем к ее построению. Сначала весь интервал изменения данных [xmin, xmax] нужно разбить на участки одинаковой длины. Естьнесколькоподходов к определению числа участков разбиения l. Один из них – это использование формулы Стэрджесса
l Round 1 3,322lg(n) , |
(1.18) |
где Round – округление чисел с плавающей запятой до целого числа.
Другой подход состоитвследующем. Содной стороны, число участков разбиения должно быть как можно больше, а с другой – в каждый из этих участков должно попадать как можно больше значений xi.Компромиссмеждуэтими требованиямиприводитк
15

тому, что обычно выбирают число участков l для построения гистограммы как ближайшее целое к корню квадратному из n:
l Round |
|
. |
(1.19) |
n |
Проверка гипотезы строится на основе сопоставления частот эмпирического и теоретического распределений и суждения о случайности или существенности их расхождений. При этом исходят из того, что если расхождения между эмпирическими и теоретическими частотами можно считать случайными, то гипотеза о том, что принятое теоретическое распределение соответствует данному эмпирическому, не отвергается.
Для оценки случайности или существенности расхождений между частотами эмпирического и теоретического распределений в статистике используют ряд показателей, именуемых критериями согласия. Один из основныхи наиболеераспространенный показатель – критерий 2 (хи-квадрат), предложенный английским статистиком К. Пирсоном:
2 |
|
m m' 2 |
, |
(1.20) |
|
m' |
|||||
|
|
|
где m и m' – эмпирические и теоретические частоты соответственно.
Величину 2 можно рассчитать и по другой формуле, непосредственно вытекающей из предыдущей:
|
|
|
|
2 |
|
|
|
m |
2 |
|
|
2 |
|
2 |
|
|
m m |
|
|
|
|
2mm |
(m ) |
|
|
||
|
m |
|
|
|
m |
|
|
||||||
|
|
|
|
|
|
|
|
(1.21) |
|||||
|
|
|
|
m2 |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
2 m |
m. |
|
|
||||
|
|
|
m' |
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Если учесть, |
что m m , |
т.е. сумма эмпирических и |
|||||||||||
теоретических частот равна, то из записанного выше следует:
2 |
m2 |
m, |
(1.22) |
|
m |
||||
|
|
|
или, приняв m N (объем совокупности), запишем в оконча-
тельном виде:
16
2 |
m2 |
N. |
(1.23) |
|
m |
||||
|
|
|
Очевидно, что 2 зависит как от расхождений между m и m', так и от числа групп (классов) в ряду, поскольку 2 вычисляется как сумма слагаемых. Одно и то же значение 2 для рядов с неодинаковым числом групп будет иметь различную надежность.
К. Пирсоном найденораспределение величины 2 и составлены таблицы, позволяющие определять вероятность наступления определенногозначения 2 дляразногочислагруппввариационных рядах. Если вероятность Р( 2) значительно отличается от нуля, то расхождения между частотами теоретического и эмпирического распределения можно считать случайными, а гипотезу, выдвинутую при расчете теоретических частот, – не опровергнутой дляданногонаблюдения.
При этом определяемая по таблицам вероятность наблюденногозначения 2 принимаетсявзависимости оттакназываемого числа степеней свободы, под которым понимается число групп, частоты которых могут принимать значения, не связанные друг с другом. Практически для вариационного ряда число степеней свободы определяется как разность между числом групп в рассматриваемом ряду и числом ограничивающих эти два ряда связей. Число ограничивающих связей, в свою очередь, определяется числом сведений эмпирическогоряда, используемых при исчислении теоретических частот. Так, например, в случае выравнивания ряда по кривой нормального распределения между эмпирическим и теоретическим распределением есть три связи: одинаковая сумма частот, средняя арифметическая и среднее квадратическоеотклонение. Поэтомупри выравнивании покривой нормального распределения число степеней свободы k определяется как l – 3, где l – число групп в ряду. При выравнивании по кривой Пуассона k = l – 2, так как в этом случае для нахождения теоретических частотучитывались двеограничивающие связи: средняя арифметическая и сумма частот.
Для оценки существенности наблюденного значения 2 при данном числе степеней свободы k могут использоваться таблицы двух типов.
17

Потаблицам первоготипа отыскивается вероятность наступления наблюденного значения 2 при данном числе степеней свободы k. Если вероятность близка к нулю (как правило, меньше 0,05), расхождения между эмпирическими и теоретическими частотами считают существенными, а гипотезу – не приемлемой для данного распределения.
По таблицам второго типа определяется предельное верхнее значение (критическое) 2 при данном числе степеней свободы и заданном уровне значимости. Затем наблюденное значение 2 сравнивают с табличным (критическим). Если фактическое 2
меньше табличного ф2 2табл , то при заданном уровне значи-
мости расхождения между эмпирическими и теоретическими частотами считают случайными, а гипотезу о принятом законе распределения – приемлемой.
Следуетостановитьсянапонятииуровнязначимости,используемогов таблицахвтороговида. Уровень значимости применительно к проверке статистических гипотез – это вероятность, с которой может быть опровергнута гипотеза о том или ином законе распределения. Чем меньше уровень значимости, тем меньше вероятность не принять гипотезу. Обычно уровень значимости P( 2) = принимают равным 0,05 или 0,01, а отвечающая данной вероятности (уровню значимости) величина 2 при определенном числе степеней свободы считается критической.
Если наблюденное значение ф2 превышает критическое, от-
вечающее принятомууровню значимости, то гипотеза о том или ином законе распределения не принимается.
Нормальное распределение описывается следующим выражением плотности вероятности:
|
|
1 |
|
|
(x |
x |
)2 |
|
|
|
|
|
|
|
|
|
|
|
|||
y |
|
|
e 2 2 |
, |
(1.24) |
|||||
|
|
|
|
|||||||
|
|
2 |
|
|
|
|
|
|||
где y – ордината кривой распределения; x – значение изучаемого признака; x – средняя арифметическая ряда; – среднее квадратическое отклонение изучаемого признака; – постоянное число (отношениедлины окружности к еедиаметру); e – основаниенатуральногологарифма.
18
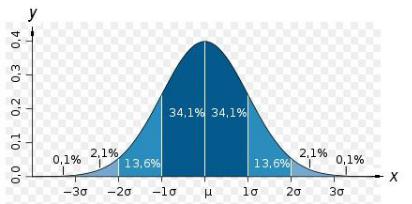
На рис. 1.1 показан график, который представляет собой симметричную куполообразную кривую, имеющую максимум в точке, соответствующей средней арифметической ряда . Точки перегиба у нормальной кривой находятся на расстоянии от средней арифметической.
Рис. 1.1. График плотности вероятности нормального распределения
На рисунке указаны доли, %, которые составляют участки площади под кривой на интервале . Площадь под кривой равна единице (100 %).
Нахождение основных характеристик статистического вариационного ряда, описанных выше, реализовано в программе «Sample». Программа позволяет:
–рассчитать показатели ряда (элемент меню Выборка);
–построить гистограмму распределения, теоретическую кривую распределения (элемент меню Распределение);
–рассчитать теоретическую вероятность в заданном диапазоне (элемент меню Диапазон);
–сформировать выборку из ряда по заданным среднему значению и стандартному отклонению фактора (элемент меню
Имитация);
–рассчитать надежность и риск при ограничении фактора справа (элемент меню Надежность);
–определить расчетноезначениефактора при заданномуровне надежности (элемент меню Фактор).
19
В рассматриваемом ниже примере производится статистическаяобработкарезультатовнатурныхиспытанийкоэффициента использованиярабочеговремени земснарядоввстроительной фирме за 2009 г. (табл. 1.7).
Таблица 1.7
Коэффициент использования рабочего времени земснаряда
Фактор |
|
|
|
|
|
Земснаряд |
|
|
|
|
|
|
||
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
8 |
9 |
0 |
11 |
12 |
13 |
|
|
|
|||||||||||||
Kв |
0,56 |
0,45 |
0,52 |
0,49 |
0,62 |
0,34 |
0,80 |
0,69 |
0,63 |
0,64 |
0,66 |
0,67 |
0,76 |
|
После запуска программы необходимо выбрать вид расчета. Затем открываем таблицу Исходные данные.db. Далее вводим коэффициентыиспользованияповременивтаблицуВыборка.db. Для этого в таблице Исходные данные.db устанавливаем курсор в ячейку Выборка и два раза нажимаем левую клавишу мыши. Потом вводим исходные данные(см. табл. 1.7) в таблицу Выборка.db и отсылаем отредактированный вариант таблицы в базу данных. После этого указываем наименование задачи, заносим величину объема выборки, которую можно определить автоматически, установив курсор в ячейку Объем выборки и два раза щелкнув левой клавишей мыши. Далее наводим курсор на ячейку Фактор, два раза щелкаем левой клавишей мыши и выбираем название нужного фактора (в рассматриваемом примере ничего выбирать не надо). Фактор в ячейке должен соответствовать фактору в таблице Выборка.db.
После заполнения таблицы Исходные данные.db отсылаем ее отредактированный вариант в базу данных и выполняем расчет. Затем вводим имяфайла с исходными данными и нажимаем Enter. Результаты расчета выводятся на экран.
Дляпостроения гистограммы, кривой нормальногораспреде- ления,организационно-технологическойнадежностиирискавы- бираем элемент меню Распределение. Затем заполняем ячейку Наименование оси X и выполняем расчет. Далее выполняем следующие операции: Расчет Построить график. Построенныеграфики можносохранить поодномувфайл или скопировать в буфер и перенести в Word. Рисунки графиков можно сохранить в формате bmp, emf или wmf. Рекомендуется использовать формат emf.
20