

Лекции 2011
.pdfСистема индексации в MS SQL Server
7.5
Структура отдельной страницы данных(data page)

Система индексации в MS SQL Server
7.6
Некластерный индекс (Non-clustered Index)
Некластерный индекс - объект БД, привязанный к одной и только одной таблиц, хранящий часть полей исходной таблицы и ссылки на соответствующие полные строки.
Для ссылки используется RID( row identificator), состоящий из : номера файла номера страницы номера строки

Система индексации в MS SQL Server
7.7
Кластерный индекс (Сlustered Index)
Кластерный индекс - объект БД, привязанный к одной и только одной таблицы, задающий порядок записи строк в страницы данных.
Использование кластерного индекса преобразует хранение данных в таблице к B tree (B+ tree, B* tree)

Система индексации в MS SQL Server
7.8
Совместное использование кластерного и некластерного индекса
Таблица без кластерного индекса называется Heap таблицей

Система индексации в MS SQL Server
7.9
Сравнение кластерного и некластерного индекса
|
Кластерный |
Некластерный |
|
индекс |
индекс |
|
|
|
Преимущества |
Быстрая работа по поиску значений |
Длина некластерного индекса не |
индекса |
влияет на другие индексы |
|
|
Хорошая производительность в |
Может быть расположен в объекте |
|
случае запросов возвращающих |
FileGroup отличном от FileGroup |
|
большой набор записей |
таблицы |
|
|
Колчиество некластерных индексов |
|
|
неограниченно c |
|
|
|
Недостатки |
Длинный кластерный ключ |
Как правило работает медленней |
увеличивает размер всех |
чем кластерный . |
|
|
некластерных индексов |
Плохая производительность для |
|
Только один кластерный ключ может |
запросов возвращающих большой |
|
быть создан для таблицы |
объем записей. |
|
|
|

Система индексации в MS SQL Server
7.10
Алгоритм работы оптимизатора запросов в отношении использования индексов
Анализ |
Поиск |
Выбор индекса |
|
возможных |
|||
атрибутов в |
на основе |
||
индексов для |
|||
WHERE и JOIN |
статистики |
||
атрибутов |
|||
|
|

Система индексации в MS SQL Server
7.11
Структура статистической информации
Стастическая информация представляет собой гистограмму
не более чем из 200 ячеек. (DBCC SHOW_STATISTICS WITH HISTOGRAM)
Для каждой ячейки хранится следующая информация:
 RANGE_HI_KEY: максимальное значение
RANGE_HI_KEY: максимальное значение
 EQ_ROWS: количество строк со значением равным RANGE_HI_KEY
EQ_ROWS: количество строк со значением равным RANGE_HI_KEY
 RANGE_ROWS: количество строк от предыдущего RANGE_HI_KEY до
RANGE_ROWS: количество строк от предыдущего RANGE_HI_KEY до
RANGE_HI_KEY
 AVG_RANGE_ROWS: Среднее количество строк для различных значений внутри RANGE_ROWS
AVG_RANGE_ROWS: Среднее количество строк для различных значений внутри RANGE_ROWS
 DISTINCT_RANGE_ROWS: Количество различных значений в RANGE_ROWS
DISTINCT_RANGE_ROWS: Количество различных значений в RANGE_ROWS

Система индексации в MS SQL Server
7.12
Общие рекомендации
 Используйте статистику по нескольким полям, когда запросы имеют условия по нескольким полям.
Используйте статистику по нескольким полям, когда запросы имеют условия по нескольким полям.
 Избегайте использования локальных переменных в запросах
Избегайте использования локальных переменных в запросах
 Используйте автоматическое создания и обновление статистики
Используйте автоматическое создания и обновление статистики
 Если необходимо используйте сбор статистики с полным сканированием таблицы
Если необходимо используйте сбор статистики с полным сканированием таблицы
CREATE STATISTICS … WITH FULLSCAN, NORECOMPUTE UPDATE STATISTICS … WITH FULLSCAN, NORECOMPUTE
 Чаще собирайте статистику для IDENTITY ключей
Чаще собирайте статистику для IDENTITY ключей

Выбор аппаратного обеспечения
7.13
Transaction Processing Performance Council (www.tpc.org)
Состав: Oracle, Microsoft, Intel, AMD, Sun, IBM, HP, Dell, Sybase и т.д.
Набор тестов и результаты измерений для существующих систем:
ТPC-C: производительность on-line transaction processing (OLTP) систем.
TPC-E: обновленная версия TPC-C
TPC-H: производительность систем поддержки принятия решений (decision support system)
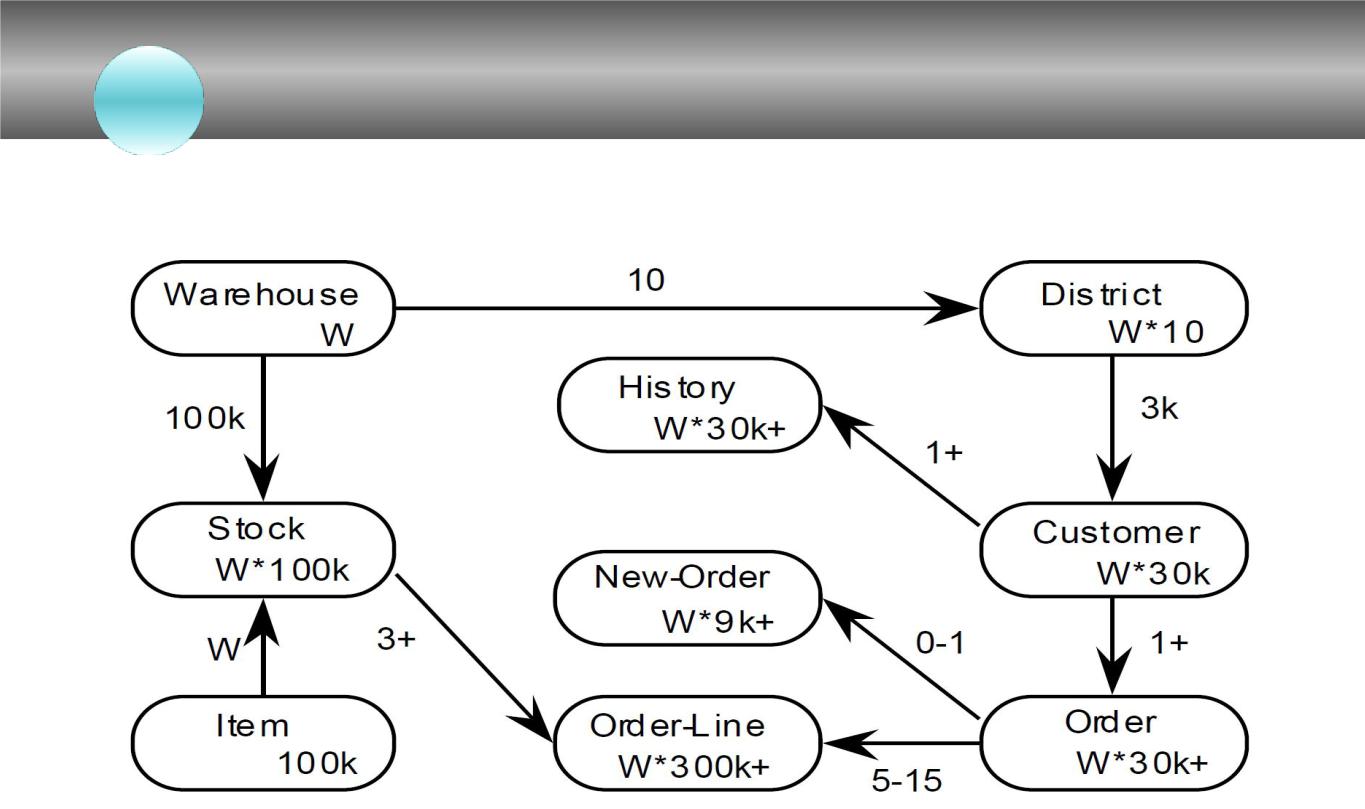
Системы управления базами данных
7.14
Схема базы данных TPC-C