

Курсовые работы / Разработка Web API для организации поиска в базах данных MySQL
.pdfЧасть III.
Библиотека для поиска в базах данных MySQL.
Полнотекстовый поиск в MySQL.
Каждый PHP программист в своё время сталкивается с организацией поиска на сайте по какому-то набору информации или по всему сайту. Данные как правило хранятся в базе данных, следовательно, и поиск осуществляется по таблицам базы данных.
У некоторых других СУБД существуют технологии поиска производительнее и мощнее, чем в MySQL. К тому же в MySQL FULLTEXTпоиск есть только в таблицах MyISAM и отсутствует в более скоростном и надёжном InnoDB. И это конечно играет не в пользу MySQL. Но малые и средние системы вполне под силу обслужить и MySQL. Причём, если поиск на малых сайтах можно реализовать даже на базе оператора LIKE, то для сайтов среднего уровня этот подход не подойдёт из-за медленности выполнения запросов. В этом случае используется так называемый полнотекстовый поиск, то есть поиск на базе индексов FULLTEXT.
Основное преимущество полнотекстового поиска – скорость выполнения. Так как он базируется на индексации, скорость выполнения запросов может в 10 раз превышать скорость выполнения запросов на базе LIKE. Важное преимущество так же в том, что результаты автоматически сортируются по релевантности, а с помощью ORDER BY можно указать другую сортировку.
Основная проблема полнотекстового поиска в MySQL – отсутствие поддержки морфологии русского языка. Он был «заточен» для поиска на англоязычных ресурсах.
Создадим тестовую таблицу, определив в ней поля для поиска и полнотекстовый индекс.
CREATE TABLE test_table
(
field1 VARCHAR (255), field2 TEXT,
FULLTEXT (field1, field2)
)
Теперь, что бы осуществить поиск в таблице, нужно выполнить запрос. Например:
SELECT * FROM table
WHERE MATCH field1, field2
AGAINST ('строка для поиска');
10
По этому запросу будут возвращены строки, где встречаются слова «строка» и «поиска» (слово «для» будет опущено из-за его длины).
При организации поиска на сайте всегда пишется, сколько элементов найдено всего, а сами результаты разбиты на страницы. Кстати, для того, чтобы подсчитать число страниц, так же надо знать общее количество найденных элементов. Решений у этой задачи как минимум три:
1.Просто получить все найденные строки от MySQL целиком.
2.Выполнить два запроса. В первом получить только ID записей, которые были найдены. Затем в PHP высчитать, какие записи нам нужны (учитывая, какая страница запрошена и сколько записей на одной странице). Затем, выполнить второй запрос и получить именно эти записи. Такой подход исключает нехватку памяти (если количество записей на странице в пределах разумного) и работает быстрее первого при большом количестве объёмных записей.
3.Использовать SQL_CALC_FOUND_ROWS. В этом случае так же выполняется два запроса, но от MySQL принимается меньшее количество записей.
Сравнение FULLTEXT поиска и LIKE поиска.
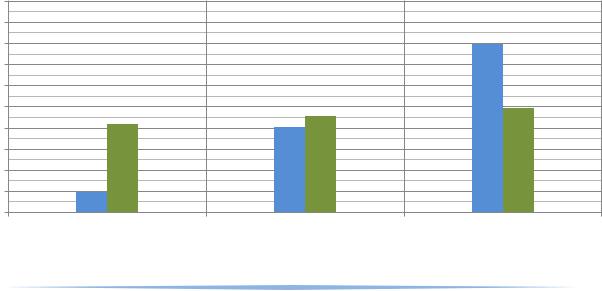
Для сравнения двух механизмов поиска был проведём следующий опыт. Создадим таблицу с четырьмя полями, два из которых были проиндексированы, содержащую 5000 строк. Поля, по которым производился поиск содержали, по 255 символов, случайно выбранных из одного большого текста. Поиск производился так же по случайным словам не короче 4-х символов.
На первом этапе искалось одно слово в одном поле. На втором этапе в одном поле искалось одно из двух слов. На третьем этапе искалось одно из двух слов в обоих полях.
На диаграмме ниже показано среднее время выполнения поисковых запросов (секунд) на каждом из 3-х этапов.
0,2
0,18
0,16
0,14
0,12
0,1
0,08
0,06
0,04
0,02
0
I |
II |
|
III |
||
|
|
FULLTEXT |
|
|
LIKE |
|
|
|
|
||
|
|
|
|
||
11

Преимущества поиска с помощью оператора LIKE:
незначительное увеличение времени обработки запроса при увеличении его сложности;
возможность сортировки результатов;
универсальность: можно использовать для поиска практически по любым типам полей, в отличие от полнотекстового.
Недостатки LIKE:
отсутствие поддержки морфологии;
отсутствие модификаторов;
поиск по всем строкам.
Преимущества полнотекстового поиска:
поддержка морфологии;
выдача результатов по релевантности;
наличие модификаторов;
возможность настройки.
Недостатки:
отсутствие возможности сортировки;
поддержка только VARCHAR и TEXT полей с индексами FULLTEXT;
ресурсоёмкий процесс;
изначальная поддержка только MyISAM таблиц;
при установленном ключе FULLTEXT добавление данных в таблицу происходи дольше.
Описание библиотеки.
Реализация API для осуществления полнотекстового поиска будет реализовано на базе библиотеки морфологического анализа phpMorhy с использованием ранее написанного класса DB.
phpMorphy позволяет решать следующие задачи:
Лемматизация (получение нормальной формы слова);
Получение всех форм слова;
Получение грамматической информации для слова (часть речи, падеж, спряжение и т. д.);
Изменение формы слова в соответствии с заданными грамматическими характеристиками;
Изменение формы слова по заданному образцу.
Поддерживаемые в phpMorphy языки: Русский, Английский, Немецкий, Украинский, Эстонский. Есть возможность добавить поддержку других языков.
Поддерживаются в phpMorphy кодировки:
12

все однобайтовые (windows-1251, iso-8859-* и т.п.)
Unicode кодировки (utf-8, utf-16le/be, utf-32, ucs2, ucs4).
phpMorphy использует для работы словарь. Поддерживаются словари
проектов AOT и myspell. Словари представлены в двух видах: в исходном и бинарном. Исходный словарь представлен в виде XML файла и содержит основы слов, правила изменения и грамматическую информацию.
Для работы библиотеки требуется скомпилировать бинарный словарь. При компиляции используется словарь в исходном виде. Бинарный словарь обладает следующими особенностями:
совместим c различными платформами;
все данные представлены в заданной кодировке, в верхнем (по умолчанию) или нижнем регистре.
Последний пункт позволяет не тратить время на преобразование
кодировки и регистра в реальном времени, а сделать это один раз на этапе компиляции.
Физически словарь представлен в виде нескольких файлов: common_aut.ru – хранилище всех словоформ;
morph_data.bin – хранилище грамматической информации; predict_aut.bin – хранилище окончаний для предсказания;
Именование файлов словаря сделано следующим образом: <имя файла>.<язык>.bin,
где <язык> – условный код языка, в виде ISO3166 кода страны и ISO639 кода языка, то есть ru_ru, en_en и т. п. Данный метод позволяет размещать в одном каталоге словари для нескольких языков.
Методы вспомогательного класса phpMorphy. |
|
Метод |
Описание |
__constuct($dir, $lang, $opts) |
Инициализация объекта класса. |
|
string $dir – директория словарей; |
|
string $lang – язык; |
|
array $opt – параметры поиска. |
getEncoding() |
Возвращает кодировку загруженного словаря. |
getLocale() |
Возвращает код языка: в виде ISO3166 код страны и ISO639 |
|
кода языка. |
isLastPredicted() |
Возвращает true, если при анализе последнего слова |
|
выяснилось, что слово отсутствует в словаре, и было |
|
предсказано; false – в противном случае. |
findWord($word) |
Детальный анализ слов. |
|
string|array $word – слово (слова) для анализа; |
getBaseForm($word) |
Получение базовой формы слова. |
getAllForms($word) |
Получение всех форм слова. |
getPseudoRoot($word) |
Получение общей части для всех словоформ заданного слова. |
|
13 |

Основной класс библиотеки (DB_Search) осуществляет полнотекстовый поиск в таблицах базы данных MySQL. Данный класс является наследником класса phpMorphy, что позволит использовать весь его функционал. Ниже приведены описания основных методов и вспомогательных констант данного библиотеки.
Открытые методы класса DB_Search.
|
Метод |
|
|
Описание |
|
|
|
|
|
|
|
|
__constructor() |
|
Инициализация объекта класса с установкой всех |
|
|
|
|
|
необходимых параметров phpMorphy для эффективного |
|
|
|
|
|
осуществления поиска. |
|
|
|
search($str, $params) |
|
Выполнение запроса к базе данных. |
|
|
|
|
|
string $str – искомая строка; |
|
|
|
|
|
array $params – ассоциативный массив параметров поиска: |
|
|
|
|
|
select – выбираемые поля (по умолчанию - все); |
|
|
|
|
|
from – источник данных; |
|
|
|
|
|
join – присоединённые таблицы; |
|
|
|
|
|
index – проиндексированные поля для поиска; |
|
|
|
|
|
limit – ограничение числа результатов; |
|
|
|
|
|
offset – номер первой записи для поиска. |
|
|
|
get_base_forms($data) |
|
Получение базовых словоформ всех слов. |
|
|
|
|
|
array|string $data – текст или массив слов. |
|
|
|
get_all_forms($data) |
|
Получение всех словоформ всех слов. |
|
|
|
|
|
array|string $data – текст или массив слов. |
|
|
|
highlight($text, $search) |
|
Подсветка искомых слов в тексте. |
|
|
|
|
|
string $text – текст; |
|
|
|
|
|
string $search – строка поиска. |
|
|
|
|
Предопределённые константы. |
|||
|
|
|
|||
|
Код состояния (константа) |
Описание |
|
||
|
|
|
|
|
|
|
DB_SEARCH_OK |
|
|
Ошибок нет |
|
|
DB_SEARCH_NO_RESULTS |
|
|
Не найдено записей, удовлетворяющих запросу. |
|
|
DB_SEARCH_ERROR_MIN_LENGTH |
Запрос меньше минимально допустимой длины. |
|
||
|
DB_SEARCH_ERROR_MAX_LENGTH |
Запрос превышает максимально допустимую длину. |
|
||
|
DB_SEARCH_ERROR_FORMS |
|
|
Ошибка в процессе формирования словоформ. |
|
|
DB_SEARCH_ERROR_BAD_WORDS |
Ни одно из слов в словаре не найдено. |
|
||
Формирование поисковых запросов.
Весь механизм работы класса DB_Search состоит из двух этапов:
1)Формирование SQL запроса.
2)Исполнение сформированного SQL запроса.
14

Если второй этап целиком осуществляется описанной ранее библиотекой для работы с базой данных MySQL, то на реализации первого этапа остановимся подробнее.
Непосредственно формирование запроса осуществляется внутри метода search(), принимающего на вход два параметра: строку для поиска и массив данных, отвечающих на вопросы:
Что искать?
Где искать?
В какой форме возвращать результат? Приведём код основным методов класса DB_Search:
1class DB_Search extends phpMorphy
2{
3public function __construct()
4{
5$dir = $_SERVER['DOCUMENT_ROOT'] . '/../include/phpMorphy/dicts';
6$lang = 'ru_RU';
7$options = array(
8 |
'storage' => PHPMORPHY_STORAGE_MEM, |
9 |
'with_gramtab' => false, |
10 |
'predict_by_suffix' => true, |
11 |
'predict_by_db' => true |
12 |
); |
13 |
|
14parent::__construct($dir, $lang, $options);
15}
16
17public function search($str, $params)
18{
19$select = '*'; $join = $limit = '';
21// Формирование списка выбираемых полей
22if(isset($params['select']) && is_string($params['select']))
23 |
$select = '`' . $params['select'] . '`'; |
24elseif(isset($params['select']) && is_array($params['select']))
25{
26 |
$fields = array(); |
27 |
foreach($params['select'] as $as => $field) |
28 |
$fields[] = (is_numeric($as)) ? "`$field`" : " `$field` AS |
29 |
`$as`"; |
30 |
$select = implode(', ', $fields); |
31 |
} |
32 |
|
33// Определение источника данных
34if(!isset($params['from'])) return;
35if(is_string($params['from']))
36 |
$from = '`' . $params['from'] . '`'; |
|
|
37elseif(is_array($params['from']))
38{
39 |
$tables |
= array(); |
40 |
foreach($params['from'] as $table) |
|
41 |
$tables[] = "`$table`"; |
|
42 |
$from = |
implode(', ', $tables); |
43}
44if(isset($params['join']) && is_array($params['join']))
45{
46 |
foreach($params['select'] as $table => |
$where) |
47 |
$join .= "LEFT JOIN `$table` WHERE |
($where)"; |
15

48 |
} |
49 |
|
50// Ограничение числа выводимых записей
51if(isset($params['limit']) && is_numeric($params['limit']))
52{
53 |
$limit = $params['limit']; |
54 |
if(isset($params['offset']) && is_numeric($params['offset'])) |
55 |
$limit = $params['offset'] . ',' . $limit; |
56 |
$limit = 'LIMIT ' . $limit; |
57 |
} |
58 |
|
59// Индексы
60$index_str = $this->get_base_forms($str);
61if(!isset($params['index']))
62 |
return; |
63 |
if(is_array($params['index'])) |
64 |
$match = '`' . implode('`, `', $params['index']) . '`'; |
65 |
elseif(is_string($params['index'])) |
66 |
$match = '`' . $params['index'] . '`'; |
67 |
|
68 |
$sql_query = "SELECT SQL_CALC_FOUND_ROWS {$select} |
69 |
FROM {$from} {$join} |
70 |
WHERE MATCH({$match}) AGAINST(?) {$limit}"; |
71 |
|
|
|
72return DB::query($sql_query, $index_str);
73}
74
75public function get_base_forms($data)
76{
77$return_array = true;
78
79// Преобразование текста в массив слов
80if(is_string($data))
81{
82 |
$return_array = false; |
83 |
$data = preg_replace('#\[.*\]#isU', '', $data); |
84 |
$data = preg_split('#\s|[,.:;!?"\'()]#', $data, -1); |
85 |
$data = array_map('str_to_upper', $data); |
86 |
} |
87 |
|
88// Отбрасывание слов, длина которых меньше минимально допустимой
89foreach($data as $i => $word)
90{
91 |
if(strlen($word) < DB_Search::MIN_LENGTH) |
92 |
unset($data[$i]); |
93 |
} |
94 |
|
95 |
$base_form = $this->getBaseForm($data); |
96 |
|
97$words_list = array();
98if (is_array($base_form))
99 |
foreach ($base_form as $i => $w) |
100 |
{ |
101 |
if(is_array($w)) |
102 |
foreach($w as $w1) |
103 |
{ |
104 |
if(strlen($w1) >= DB_Search::MIN_LENGTH) |
105 |
$words_list[$w1] = 1; |
106 |
} |
107}
108$words = array_keys($words_list);
110return ($return_array) ? $words : join(' ', $words);
16

111 |
} |
112 |
|
113public function get_all_forms($data)
114{
115$return_array = true;
116
117// Преобразование текста в массив слов
118if(is_string($data))
119{
120 |
$return_array = false; |
121 |
$data = preg_split('#\s|[,.:;!?"\'()]#', $data, -1); |
122 |
$data = array_map('str_to_upper', $data); |
123 |
} |
124 |
|
|
|
125// Отбрасывание слов, длина которых меньше минимально допустимой
126foreach($data as $i => $word)
127{
128 |
if(strlen($word) < DB_Search::MIN_LENGTH) |
129 |
unset($data[$i]); |
130 |
} |
131 |
|
132 |
$words = $this->getAllForms($data); |
133 |
|
|
|
134$words_list = array();
135foreach($words as $forms)
136 |
foreach($forms as |
$form) |
137 |
$words_list[] |
= $form; |
138 |
|
|
139return ($return_array) ? $words : implode(' ', $words_list);
140}
141}
Врезультате работы метода search() осуществляется определение базовых словоформ слов, входящих в строку поиска. Полученные словоформы используются в запросе к базе данных.
Например, в результате поиска по слову «Решение квадратных уравнений» в тестовой базе данных (см. далее) формируется запрос вида:
SELECT SQL_CALC_FOUND_ROWS `lesson_id` FROM `lesson_search`
WHERE MATCH(`lesson_words`) AGAINST(‘РЕШЕНИЕ КВАДРАТНЫЙ УРАВНЕНИЕ’)
17

Пример использования.
Для тестирования работы функционала созданного Web API была использована уже готовая база данных веб-приложения, осуществляющего обучение и контроль знаний студентов в режиме online. Дадим краткое описание таблиц данной базы данных:
users – пользователи (учащиеся);
teachers – преподаватели;
sections – учебные разделы;
courses – учебные курсы;
lessons – тексты уроков и домашних заданий;
homeworks – домашние работы учащихся;
messages – личные сообщения пользователей;
teachers_courses – связывающая таблица для курсов и преподавателей;
courses_taken – связывающая таблица для пользователей и курсов. Для осуществления полнотекстового поиска дополнительно в базу
данных была добавлена таблица lesson_search (MyISAM), с проиндексированным полем lesson_words. В данную таблицу заносятся базовые словоформы всех слов каждого урока из таблицы lessons. В результате такого перехода к базовым словоформам текст «сжимается» в 5 – 20 раз и становится оптимизированным для осуществления поиска.
Основной код использования библиотеки для осуществления поиска:
1 $search = trim($_POST['search']); 2
3$db = new DB_Search();
4$result = $db->search($search, array(
5'select' => array('id' => 'lesson_id'),
6'from' => 'lesson_search',
7'limit' => '10',
8'index' => array('lesson_words')
9));
Далее представлены графическая ER-модель базы данных, скриншот результата работы простейшего веб-приложения, использующего API, и скриншот результата подсветки искомых слов в тексте.
18
