

Лабораторные работы (2008) / Лабраторная работа 2 / Сортировка Бэтчэра (Ясенков)
.docМосковский Энергетический Институт
(Технический Университет)
Кафедра Прикладной Математики
Отчет по лабораторной работе 2
«MPI»
Выполнил: Ясенков Е.М.
Группа: А-13-03
Москва 2008
Задание
Реализовать параллельный алгоритм сортировки Бэтчэра. Элементами массива являются структуры, для которых определены отношения «>» и «<». Предполагается, что необъодимо сортировать большой массив данных.
Алгоритм
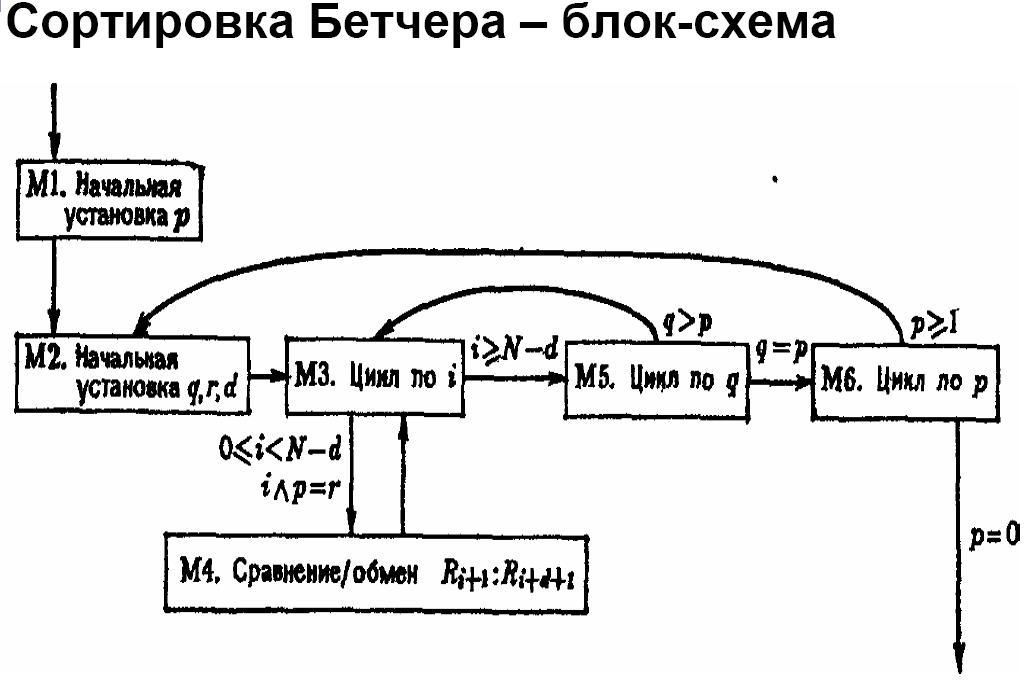
Данная задача крайне не эффективно решается в системах с разделенной памятью, потому что требуется очень большое количество обменов сообщениями. (3*log(n)). Работает это следующим образом: в начале каждого прохода по вектору главный процесс рассылает всем матрицу, потом в каждом процессе объявляется структура, в которой мы передаем количество элементов, требующих перестановку и номера этих элементов. При проходе по циклу (своей части) эта структура заполняется, и потом отсылается главному процессу. Там непосредственно меняются элементы, указанные в структуре.
Реализация
#include <stdio.h>
#include "stdlib.h"
#include <math.h>
#include "iostream"
#include "mpi.h"
#ifdef SEEK_SET
#undef SEEK_SET
#endif
#ifdef SEEK_CUR
#undef SEEK_CUR
#endif
#ifdef SEEK_END
#undef SEEK_END
#endif
struct elem
{
elem () { x = 0; };
elem(double arg) { x = arg; };
double x;
bool operator > (elem el2) { return x > el2.x; }
};
void swap(elem& p1, elem& p2)
{
elem temp = p1;
p1 = p2;
p2 = temp;
};
int main(int argc, char** argv)
{
if(argc < 2)
{
std::cout<<"Wrong number of arguments"<<std::endl;
return 0;
}
// Готовим матрицу для сортировки
int n = atoi(argv[1]);
elem* pA = new elem[n];
for(int i=0; i<n; i++) pA[i].x = rand() / 100;
int nCurrRank; // ранг текущего процесса
int nProcCount; // Количество процессов
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &nCurrRank);
MPI_Comm_size(MPI_COMM_WORLD, &nProcCount);
double start_time = 0;
if (!nCurrRank) start_time=MPI_Wtime();
// отправим всем процессам вектор для сортировки
int nResult = MPI_Bcast(pA, n*sizeof(elem), MPI_BYTE, 0, MPI_COMM_WORLD);
if(nResult != MPI_SUCCESS) std::cout<<nResult<<"rank - "<<nCurrRank<<" Proc -<<MPI_Bcast failed"<<std::endl;
// Устанавливаем начальные значения
int t = log((double)n)/log(2.0);
int p = pow(2.0, (double)(t-1));
int nCurrSize = (n - p)/nProcCount;
while(p > 0)
{
int q = pow(2.0, (double)(t-1));
int r = 0;
int d = p;
while(q >= p)
{
nCurrSize = (n - d)/nProcCount;
for(int i=nCurrRank*nCurrSize; i<(nCurrRank+1)*nCurrSize; i++)
if((i&p) == r) if(pA[i] > pA[d + i]) swap(pA[i], pA[d + i]);
nResult = MPI_Bcast(&pA[nCurrRank*nCurrSize], nCurrSize*sizeof(elem), MPI_BYTE, nCurrRank, MPI_COMM_WORLD);
nResult = MPI_Bcast(&pA[nCurrRank*nCurrSize + d], nCurrSize*sizeof(elem), MPI_BYTE, nCurrRank, MPI_COMM_WORLD);
d = q-p;
q = q/2;
r=p;
}
p = p/2;
}
if(!nCurrRank) std::cout<<MPI_Wtime() - start_time<<std::endl;
MPI_Finalize();
return 0;
}
Тестирование
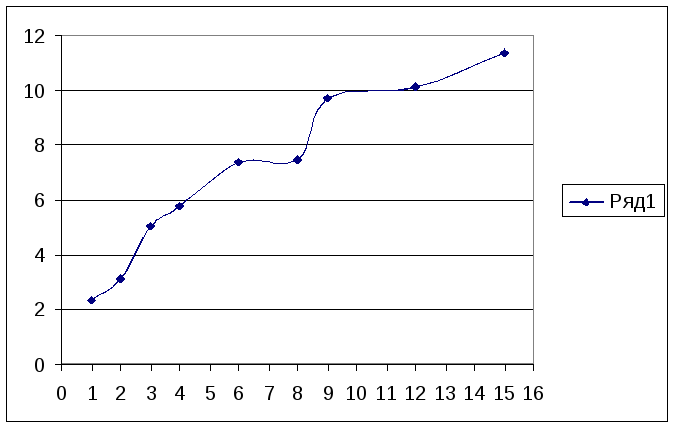
Зависимость времени вычислений от количества процессов
|
1 |
2 |
3 |
4 |
6 |
8 |
9 |
12 |
15 |
|
2,34 |
3,12 |
5,05 |
5,79 |
7,38 |
7,45 |
9,72 |
10,14 |
11,36 |
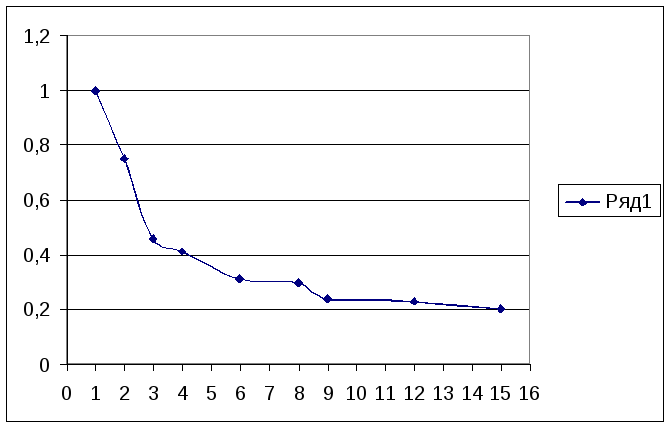
Зависимость ускорения вычислений от количества процессов
|
1 |
2 |
3 |
4 |
6 |
8 |
9 |
12 |
15 |
|
1 |
0,75 |
0,46 |
0,41 |
0,31 |
0,3 |
0,24 |
0,23 |
0,2 |
Вывод
Применение MPI для распараллеливания циклов в данной задаче крайне неэффективно, ввиду большого количества обменов сообщениями и необходимостью различать работу главного процесса и дополнительных процессов.