

Лабораторные работы (2008) / Лабраторная работа 3 / Вычисление интеграла функции на отрезке по методу Симпсона (Ясенков)
.docМосковский Энергетический Институт
(Технический Университет)
Кафедра Прикладной Математики
Отчет по лабораторной работе 3
«WinThreads»
Выполнил: Ясенков Е.М.
Группа: А-13-03
Москва 2008
Задание
Задана некоторая произвольная функция f, непрерывная на отрезке [a, b]. Написать программу параллельного вычисления интеграла функции f на [a, b] по методу Симпсона с точностью eps.
Алгоритм
З![]() начение
определенного интеграла
начение
определенного интеграла
н![]()
![]() аходится
методом Симпсона (парабол). Отрезок [a,
b] разбивается на n=2m частей x0 =a,
x1 =a+h,
..., xn =b
с шагом h=(b-a)/n. Вычисляются значения
yi
= F(xi )
функции в точках xi
и находится значение интеграла по
формуле Симпсона:
аходится
методом Симпсона (парабол). Отрезок [a,
b] разбивается на n=2m частей x0 =a,
x1 =a+h,
..., xn =b
с шагом h=(b-a)/n. Вычисляются значения
yi
= F(xi )
функции в точках xi
и находится значение интеграла по
формуле Симпсона:
S = Sn +Rn , где
Затем количество точек разбиения удваивается и производится оценка точности вычислений:
Rn = |S2n -Sn |/15
Если Rn > e, то количество точек разбиения удваивается. Значение суммы 2(y1 +y2 +...+y2m-1 ) сохраняется, поэтому для вычисления интеграла при удвоении количества точек разбиения требуется вычислять значения yi лишь в новых точках разбиения.
Реализация
#include "stdafx.h"
#include "windows.h"
#include "math.h"
#include "conio.h"
#include "time.h"
#define THREADS 4 // определим количество потоков
#define eps 0.00000000001 //точность
#define a 0.0 //границы отрезка
#define b 10.0
int intervals; //начальное число точек разбиения
HANDLE hThreads[THREADS];//потоки
double PartIntegrals[THREADS]; //частичные суммы для каждого потока вычисления
DWORD dwThreadsIDs[THREADS];//идентификаторы потоков
double res1 = 0, res2 = 0, fPart = 0, nPart = 0, h; //целые и дробные индексы, шаг
double f(double x) { return (x*x*x*x*x*sin(x))+x; } //функция
DWORD WINAPI fPartCount(LPVOID num)
{ //вычисление значения функции в точках с дробными индексами
int i, thread = (int) num;
double x;
PartIntegrals[thread] = 0;
for(i = thread+1; i <= intervals; i += THREADS)
{
x = a + h * ((double)i - 0.5);
PartIntegrals[thread]+=f(x);
}
return 0;
}
DWORD WINAPI nPartCount(LPVOID num)
{ //вычисление значения функции в точках с целыми индексами
int i, thread = (int) num;
double x;
PartIntegrals[thread] = 0;
for(i = thread+1; i < intervals; i += THREADS)
{
x = a + h * i;
PartIntegrals[thread]+=f(x);
}
return 0;
}
void Solve(double & res)
{ //вычисление интеграла
int i; //считаем часть интеграла c дробными индексами
for(i=0; i<THREADS; i++) PartIntegrals[i] = 0;
for(i=0; i<THREADS; i++) //создаем потоки
{
hThreads[i] = CreateThread(NULL, 0, fPartCount, (void *)i, 0, &dwThreadsIDs[i]);
if(hThreads[i] == NULL) printf("Error while creating thread");
}
WaitForMultipleObjects(THREADS, hThreads, TRUE, INFINITE);
for(i=0; i<THREADS; i++) CloseHandle(hThreads[i]);
fPart = 0; //частичная сумма
for(i=0; i<THREADS; i++) fPart+=PartIntegrals[i];
for(i=0; i<THREADS; i++) PartIntegrals[i] = 0;
for(i=0; i<THREADS; i++) //считаем часть интеграла с целыми индексами
{ //создаем потоки
hThreads[i] = CreateThread(NULL, 0, nPartCount, (void *)i, 0, &dwThreadsIDs[i]);
if(hThreads[i] == NULL) printf("Error while creating thread");
}
WaitForMultipleObjects(THREADS, hThreads, TRUE, INFINITE); //ждем завершения
for(i=0; i<THREADS; i++) CloseHandle(hThreads[i]); //завершаем потоки
nPart = 0; //частичная сумма
for(i=0; i<THREADS; i++) nPart+=PartIntegrals[i];
res = (f(a) + fPart * 4 + nPart * 2 + f(b)) * h / 6.0; //считаем весь интеграл
}
int _tmain(int argc, _TCHAR* argv[])
{
int steps = 0;
double time;
clock_t start, finish;
start = clock(); //время начала
intervals = THREADS;
h = (b-a)/(double)(intervals);
Solve(res1);
do
{
if(steps != 0) res1 = res2;
steps++;
intervals = intervals * 2;
h = h / 2.0;
Solve(res2);
printf("Integral = %.15f\n", res2);
}
while (fabs(res1 - res2)/15.0 > eps);
finish = clock(); //время окончания подсчета
time = (double)(finish - start) / CLOCKS_PER_SEC;
FILE * f = fopen(".\\Result.txt", "w");
printf( "\nResult = %.15f\nSteps = %d\nThreads number = %d \nTime = %f\n", res2, steps, THREADS, time);
fprintf(f, "\nResult = %.15f\nSteps = %d\nThreads number = %d \nTime = %f\n", res2, steps, THREADS, time);
fclose(f);
getch();
return 0;
}
Тестирование
Процессор: AMD Athlon XP Barton 2500+ 1.83 Ghz
Памать: 2x1024 DDR3200
ОС: Windows XP SP3 rc1
Зависимость времени вычисления интеграла от количества процессов
|
0,297 |
0,266 |
0,235 |
0,172 |
0,250 |
0,281 |
0,282 |
0,329 |
0,359 |
0,547 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
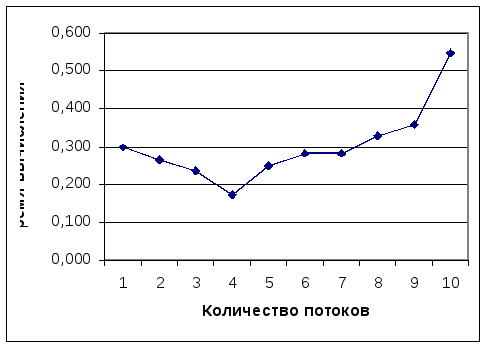
Вывод
Как видно из графика, с увеличением числа потоков от 1 до 4, время вычисления интеграла уменьшается. Если продолжить вычисления увеличивая число потоков, то время вычисления начинает сильно повышаться, и при количестве потоков больше 7, использование WinThreads не приносит увеличения производительности. Наибольшая производительность (40%) получена на 4 потоках. Результаты тестирования могу существенно отличаться на машине с другим процессором (например двуядерным).