

Лб4 Віка
.docМІНІСТЕРСТВО ОСВІТИ ТА НАУКИ УКРАЇНИ
ХАРКІВСЬКИЙ НАЦІОНАЛЬНИЙ УНІВЕРСИТЕТ РАДІОЕЛЕКТРОНІКИ
Кафедра СТ
Звіт
про виконання лабораторної роботи № 4
з дисципліни Інтелектуальна обробка даних в розподілених інформаційних середовищах
на тему “Закріплення навичок інтелектуального аналізу даних”
Виконала: ст. гр. СПРм-19-1 Шемчук В. Н. |
Перевірила: Перова І. Г. |
Харків 2020
Закріплення навичок інтелектуального аналізу даних
Цель работы: Демонстрация и закрепление навыков интеллектуального анализа данных
Ход работы:
1. Завантажити інформацію з файлу 'breast-cancer-wisconsin.xlsx'.
file =
pd.ExcelFile('breast-cancer-wisconsin.xlsx')
df_lab_4 =
pd.read_excel(file, header=None)
2. Провести візуалізацію даних за допомогою методу головних компонентів та TSNE. Налаштувати параметри обох методів для найкращої візуалізації обох класів в даних.


Рисунок 1 — Визуализация исходных данных при помощи TSNE


Рисунок 2 — Визуализация исходных данных при помощи PCA
3. Провести кластеризацію даних з використанням відомих вам алгоритмів кластеризації – обрати найкращій метод. При виборі найкращого методу слід зважати не тільки на вірний розподіл даних по кластерах, але і враховувати метрики, що застосовуються для кластерного аналізу.
Для кластеризации были выбраны методы KMeans и DBSCAN.
kmeans
= KMeans(n_clusters = 2, init = 'k-means++', max_iter=300, n_init=10,
random_state = 41)
y_kmeans
= kmeans.fit_predict(df_stan_4)
y_k
= copy.copy(y)
y_k[y
== 2] = 0
y_k[y
== 4] = 1
expected
= y_k
predicted
= y_kmeans
print('Adjusted
rand score:',metrics.adjusted_rand_score(expected[:,0], predicted))
print('Adjusted
mutual info score:',metrics.adjusted_mutual_info_score(expected[:,0],
predicted))
print('\n\nClassification
report:')
target_names
= ['доброкачественная',
'злокачественная']
print(metrics.classification_report(expected,
predicted, target_names=target_names))
confusionMatrics
= metrics.confusion_matrix(expected, predicted)
print('\n\nConfusion
Matrix')
#visualizing
confusion matrix
sn.set(font_scale=1.4)
# for label size
sn.heatmap(confusionMatrics,
annot=True, annot_kws={"size": 16}) # font size
plt.show()


Рисунок
3 — Метрики результатов метода Kmeans

Рисунок
4 — Визуализация результатов работы
Kmeans
Далее
рассмотрим кластеризацию методом DBSCAN
dbscan
= DBSCAN(eps=1, min_samples=3)
dbscan.fit(df_stan_4)
predicted
= dbscan.labels_
print('Adjusted
rand score:',metrics.adjusted_rand_score(expected[:,0], predicted))
print('Adjusted
mutual info score:',metrics.adjusted_mutual_info_score(expected[:,0],
predicted))
print('\n\nClassification
report:')
print(metrics.classification_report(expected,
predicted, zero_division =1))
print('\n\nConfusion
Matrix')
#visualizing
confusion matrix
confusionMatrics
= metrics.confusion_matrix(expected, predicted)
sn.set(font_scale=1.4)
# for label size
sn.heatmap(confusionMatrics,
annot=True, annot_kws={"size": 16}) # font size
plt.show()


Рисунок
5 — Метрики результатов DBSCAN

Рисунок
6 — Визуализация результатов работы
DBSCAN
Были
выбраны 3 метода классификации:
DecisionTreeClassifier,
KNeighborsClassifier
и
MLPClassifier.
X_train,
X_test, Y_train, Y_test = train_test_split(df_stan_4, y,
test_size=0.35, random_state=22)
K_neigh_4
= KNeighborsClassifier(n_neighbors=3)
K_neigh_4.fit(X_train,
Y_train.flatten())
Y_K_neigh_predict
= K_neigh_4.predict(X_test)
K_neigh_conf_matrix
= metrics.confusion_matrix(Y_test.flatten(),
Y_K_neigh_predict.flatten());
#show
classification report
showCR(Y_K_neigh_predict,
'KNeighborsClassifier')
getErrorScores(Y_K_neigh_predict,
'KNeighborsClassifier')
#visualizing
confusion matrix
showMatrix(K_neigh_conf_matrix)
K_neigh_all_predicted
= K_neigh_4.predict(df_stan_4)
showPCA(K_neigh_all_predicted.ravel(),
"KNeighborsClassifier")


Рисунок
7 — Метрики метода KNeighborsClassifier

Рисунок
8
— Визуализация результатов
KNeighborsClassifier
MLP
= MLPClassifier()
MLP.fit(X_train,
Y_train.flatten())
MLP_predict
= MLP.predict(X_test)
MLP_conf_matrix
= metrics.confusion_matrix(Y_test.flatten(), MLP_predict.flatten());
#show
classification report
showCR(MLP_predict,
'MLPClassifier')
getErrorScores(MLP_predict,
'KNeighborsClassifier')
#visualizing
confusion matrix
showMatrix(MLP_conf_matrix)
MLP_all_predicted
= MLP.predict(df_stan_4)
showPCA(MLP_all_predicted.ravel(),
"MLPClassifier")


Рисунок
8 — Метрики
метода
MLPClassifier

Рисунок
9 — Визуализация
результатов
MLPClassifier
DTC = DecisionTreeClassifier(max_depth=5)
DTC.fit(X_train, Y_train.flatten())
DTC_predict = DTC.predict(X_test)
DTC_conf_matrix = metrics.confusion_matrix(Y_test.flatten(), DTC_predict.flatten());
#show classification report
showCR(DTC_predict, 'DecisionTreeClassifier')
getErrorScores(DTC_predict, 'DecisionTreeClassifier')
#visualizing confusion matrix
showMatrix(DTC_conf_matrix)
DTC_all_predicted = DTC.predict(df_stan_4)
showPCA(DTC_all_predicted.ravel(), "DecisionTreeClassifier")
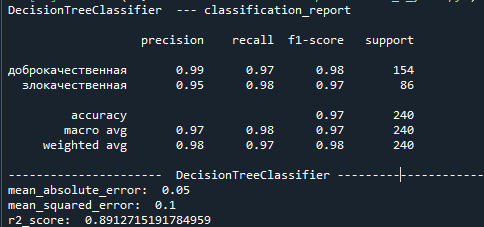

Рисунок
10 — Метрики
метода
DecisionTreeClassifier
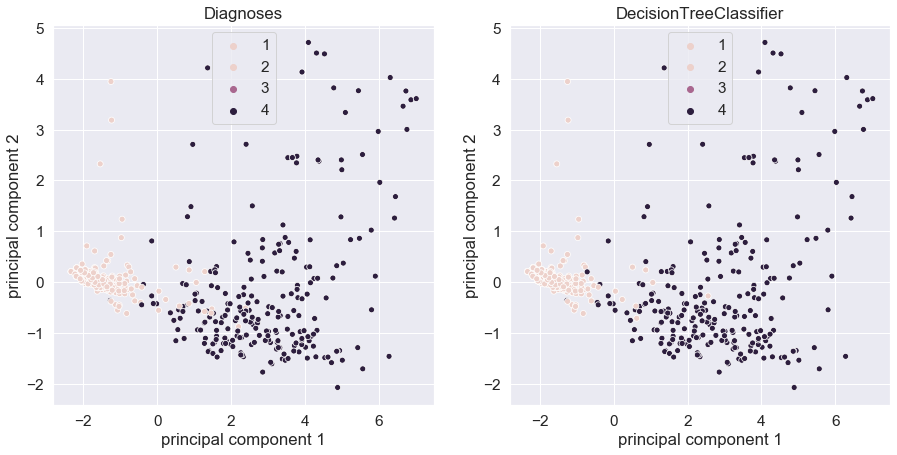
Рисунок
1 — Визуализация
результатов
DecisionTreeClassifier
Выводы:
в ходе лабораторной работы, при выполнении
первого задания была проведена
кластеризация данных с помощью методов
Kmeans
и DBSCAN.
При
анализе результатов Kmeans
получилось
получить
четких 2 кластера как для PCA
так и для TSNE.
DBSCAN
смог
выделить 1 кластер с доброкачественными,
но не смог определить 2 кластер и выбросил
его в шум.
Во
втором задании необходимо была проведена
классификация данных с помощью методов
DecisionTreeClassifier,
KNeighborsClassifier
и
MLPClassifier.
Все из исплозованных методов справились
отлично, лучший из них выбрать сложно.