

МИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра биотехнических систем
отчет
по практическому занятию №3
по дисциплине «Моделирование биологических процессов и систем»
Тема: Кластеризация
Вариант 7
Студент гр. 7501 |
|
Исаков А.О. |
Преподаватель |
|
Скоробогатова А.И. |
Санкт-Петербург
2020
Цель работы: осуществить кластеризацию данных с помощью различных иерархических методов.
Основные теоретические положения
Кластеризация (кластерный анализ) – задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты различных групп должны быть как можно более отличны.
Главное отличие кластеризации от классификации состоит в том, что перечень групп не задан четко и определяется в процессе работы алгоритма.
Цели кластеризации:
Понимание данных путем выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа.
Сжатие данных. Если исходная выборка избыточно большая, то ее можно сократить, оставив по одному наиболее типичному представителю от каждого кластера;
Обнаружение новизны. Выделяются нетипичные объекты, которые не удается присоединить ни к одному из кластеров.
Этапы кластеризации:
Отбор выборки объектов кластеризации.
Определение множества переменных, по которым будут оцениваться объекты в выборке. При необходимости – нормализация значений переменянных.
Вычисление значений меры сходства между объектами (например, расстояний).
Применение метода кластерного анализа для создания групп сходных объектов (кластеров).
Выбор числа кластеров.
Представление результатов анализа.
Среди множества существующих методов кластеризации, в данной работе наиболее подробно рассмотрен иерархический.
Чтобы подготовить данные к кластеризации, необходимо предварительно нормализовать по формуле стандартного z-распределения со средним, равным 0, и стандартным отклонением, равным 1:

где r – исходные данные; m – среднее значение по признаку; s – стандартное отклонение по признаку.
Затем построим скатерограмму пронормированных данных относительно параметра idz, рассчитанного функцией MATLAB kmean(), которая разделяет данные на количество кластеров, заданное пользователем (в нашем случае 3), с помощью k++ алгоритма (means++ algorithm k). Алгоритм работы реализуется следующим образом:
Из выборки данных X выбирается случайное однородное значение, которое принимается за центральное (центроид) и обозначается c1.
Вычисляется расстояние от каждого объекта до c1. Расстояние между cj и наблюдением m обозначается как d(xm,cj).
Следующий центроид c2 выбирается наугад с вероятностью

ОБРАБОТКА РЕЗУЛЬТАТОВ МОДЕЛИРОВАНИЯ
clc
clear
close all
%% Загрузили данные
k=7;
P1 = xlsread('clust.xlsx','Лист1','M1:M300');
P2 = xlsread('clust.xlsx','Лист1','N1:N300');
%% Нормировали
P1 = P1';
P2 = P2';
m = mean(P1);
sko = std(P1);
P11 = zeros(1,300);
for i = 1:300
P11(1,i) = (P1(1,i)-m)/sko;
end
m = mean(P2);
sko = std(P2);
P22 = zeros(1,300);
for i = 1:300
P22(1,i) = (P2(1,i)-m)/sko;
end
%% Создание общей матрицы
P=[P11' P22'];
%% Иерархический метод
tree = linkage(P,'average');
figure()
dendrogram(tree,'Orientation','left','ColorThreshold','default')
title('Average')
%% Скаттерограмма на основе в ручную полученных меток классов
c = cluster(tree,'maxclust', 2);
figure()
gscatter(P(:,1),P(:,2),c);
% ну либо scatter(P(:,1),P(:,2),2,c);
title('Скаттерограмма на основе в ручную полученных меток классов')
%% Скаттерограмма на основе автоматического алгоритма кластеризации
figure()
idx = kmeans(P,3);
gscatter(P11,P22,idx,'bgm');
title('Скаттерограмма на основе автоматического алгоритма кластеризации')
clear i idx k m P1 P11 P2 P22 sko

Рисунок 1 – Скаттерограмма, полученная с помощью kmeans функции
Метод средней связи Average

|
|


Рисунок 2 – Дендрограмма и скаттерограмма, полученные на основе метода средней связи Average
В этом методе и далее оптимальное число кластеров выбиралось визуально с помощью дендограммы. Для наглядности выбора в функции dendogram() использовался параметр 'ColorThreshold', помогающий определить оптимальное число кластеров по цветам (в данном случае 2). Затем с помощью cluster() были получены метки кластеров, относительно которых и строились конечные скаттерограммы.
Метод взвешенной средней связи Weighted
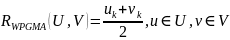
|
|
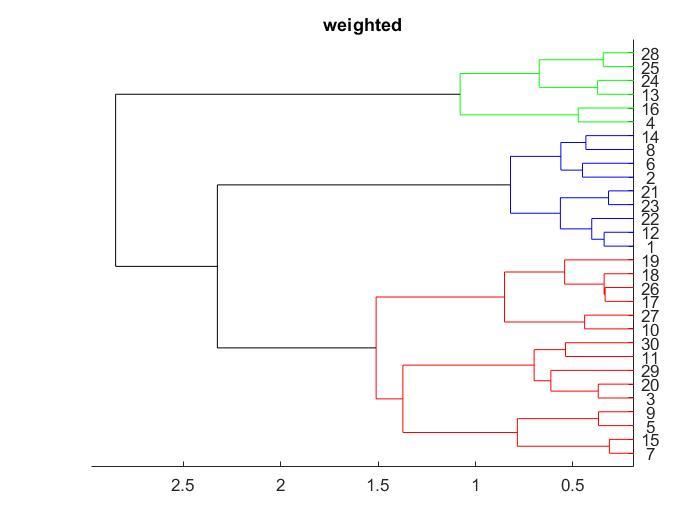

Рисунок 3 – Дендрограмма и скаттерограмма, полученные на основе метода взвешенной средней связи Weighted
Метод полной связи Complete
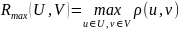
|
|


Рисунок 4 – Дендрограмма и скаттерограмма, полученные на основе метода полной связи Complete
По рисункам 2 – 4 видно, что для имеющегося набора данных использование метода средней связи наименее удачно, а чаще всего данные разделяются на 3 кластера. Можно предположить, что деление на три кластера является оптимальным.
Количество кластеров подбирается в зависимости от поставленной задачи, а методы позволяют выбирать не только качественно, но и количественно, оценивая расстояния между объектами, вычисляемое в каждом методе по-своему.
ПРАКТИЧЕСКОЕ ЗАДАНИЕ №4
selectedButton = app.KmeansButtonGroup.SelectedObject;
K = app.EditField.Value;
%Valid values are: 'sqeuclidean', 'cityblock', 'cosine', 'correlation', 'hamming'
if strcmpi(selectedButton.Text,'sqeuclidean')
cla(app.UIAxes2)
cla(app.UIAxes)
idx = kmeans(app.P,K,'Distance',"sqeuclidean");
gscatter(app.UIAxes2,app.P(:,1),app.P(:,2),idx);
elseif strcmpi(selectedButton.Text,'cityblock')
cla(app.UIAxes2)
cla(app.UIAxes)
idx = kmeans(app.P,K,'Distance',"cityblock");
gscatter(app.UIAxes2,app.P(:,1),app.P(:,2),idx);
elseif strcmpi(selectedButton.Text,'cosine')
cla(app.UIAxes2)
cla(app.UIAxes)
idx = kmeans(app.P,K,'Distance',"cosine");
gscatter(app.UIAxes2,app.P(:,1),app.P(:,2),idx);
elseif strcmpi(selectedButton.Text,'correlation')
cla(app.UIAxes2)
cla(app.UIAxes)
idx = kmeans(app.P,K,'Distance',"correlation");
gscatter(app.UIAxes2,app.P(:,1),app.P(:,2),idx);
end

Рисунок 5 – Выбор оптимального числа кластеров
klist=2:n;% число кластеров, которое надо испытать
myfunc = @(X,K)(kmeans(X, K));
eva = evalclusters(net.IW{1},myfunc,'CalinskiHarabasz','klist',klist)
classes=kmeans(net.IW{1},eva.OptimalK);
Также kmeans кластеризацию можно провести, используя метрику расстояния Distance, разновидности которой представлены на рисунке 5.

Рисунок 6 – Виды метрики расстояний Distance, предлагаемые документацией MATLAB
На рисунках 6-9 можно видеть результат реализации данной функции.

Рисунок 7 – Скаттерограмма, полученная с помощью “Sqeuclidian”

Рисунок 8 – Скаттерограмма, полученная с помощью “Cityblock”

Рисунок 9 – Скаттерограмма, полученная с помощью “Cosine”

Рисунок 10 – Скаттерограмма, полученная с помощью “Correlation”
Можно сделать вывод о том, что использование метрики расстояния Distance удобно в том случае, когда мы предположительно определяем число кластеров или выбираем его на наше усмотрение.
Результаты кластеризации Distance не совпадают с вариантами иерархической кластеризации.
ВЫВОД
В ходе данной практической работы было рассмотрено понятие кластеризации, ее цели и задачи, осуществлена кластеризация данных иерархическим методом, подобрано оптимальное количество кластеров (предположительно 3). Изучены наглядные методы определения числа кластеров: построение дендрограмм и скатерограмм относительно расстояний между объектами, вычисленных различными способами.
Оптимальное число кластеров можно определить методом локтя используя соответствующую библиотеку или соответствующий код: https://www.mathworks.com/matlabcentral/fileexchange/65823- kmeans_opt?focused=8772533&tab=function