

1_КОЭД_Алексеева
.docxУфимский Государственный Авиационный Технический
Университет
Кафедра вычислительной математики и кибернетики
Отчет по лабораторной работе №1
по дисциплине
«Компьютерная обработка экспериментальных данных»
Статистическая обработка результатов эксперимента
Выполнила: студентка гр. ПРО-323 Алексеева Анна
Проверила: Абдрахманова Римма Петровна
Уфа - 2022
Задача
Изучив теоретический материал и разобрав пример статистической обработки результатов эксперимента, выполнить статистическую обработку для выборки значений некоторого непрерывного количественного признака, объем выборки n = 50.
Ход работы
Денежные доходы на душу населения в мес., руб.
Всего обследовано 50 регионов:
Самый информативный столбец -15
882, 1264, 1317, 1356, 1366, 1508, 1525, 1538, 1616, 1626, 1646, 1654, 1662, 1668, 1685, 1685, 1699, 1742, 1785, 1807, 1836, 1838, 1863, 1885, 1922, 1930, 1947, 1974, 2000, 2013, 2023, 2109, 2131, 2247, 2256, 2300, 2329, 2371, 2383, 2405, 2482, 2503, 2684, 2798, 2879, 3256, 3468, 3666, 4377, 4501
Применяя формулу Стеджерса, находим приближенную ширину интервала
По
формуле (5) имеем
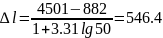
Принимаем ∆l = 546
Принимаем x’max = 4505, x’min = 683
Определяем число интервалов группирования экспериментальных данных
По
формуле (7)
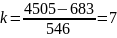
параметр |
обозначение |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
Границы интервалов |
(ci-1,ci) |
882; 1428 |
1428; 1974 |
1974; 2520 |
2520; 3066 |
3066; 3612 |
3612; 4158 |
4158;4704 |
Середина интервала |
|
1155 |
1701 |
2247 |
2793 |
3339 |
3885 |
4431 |
Частота |
|
5 |
23 |
14 |
3 |
2 |
2 |
1 |
Частотность |
|
0.1 |
0.46 |
0.28 |
0.06 |
0.04 |
0.04 |
0.02 |
Накопленная частота |
|
5 |
28 |
42 |
45 |
47 |
49 |
50 |
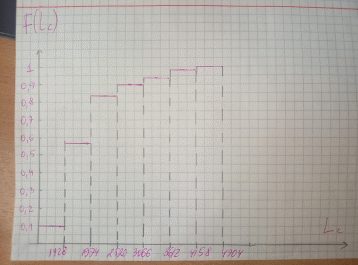
Оценка интегральной функции |
|
0.1 |
0.56 |
0.84 |
0.9 |
0.94 |
0.98 |
1 |
Оценка дифференциальной функции |
|
0.0002 |
0.0008 |
0.0005 |
0.0001 |
0.00007 |
0.0007 |
0.00003 |

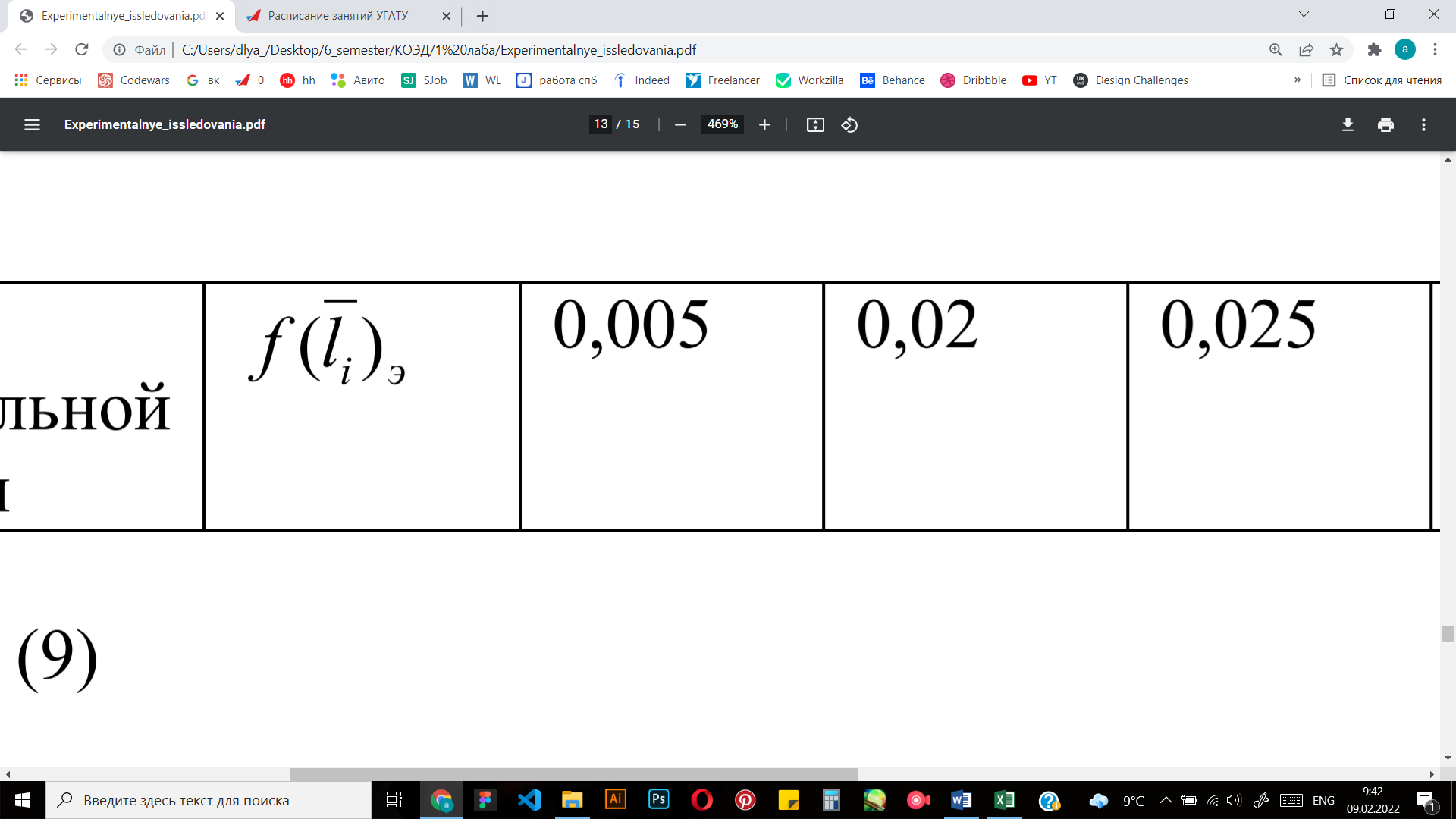
Среднее значение экспериментального распределения рассчитываем следующим образом:
По формуле (9) = 1155*0.1 + 1701*0.46 + 2247*0.28 + 2793*0.06 + 3339*0.04 + 3885*0.04 + 4431*0.02 = 2072.28
Принимаем


Найдем дисперсию вариационного ряда по формуле (16)
D(l)= 1/50 [(1155-2072,28) ^2 ×1+…+(4431–2027.28)2 × 7]=1429402.8
Эмпирическое среднее квадратическое отклонение:
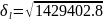 = 1195.5
= 1195.5
Оценка:
По формуле (12)
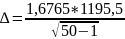 = 286,3
= 286,3
Доверительный интервал:
по формуле (10) (2072,28–286,3) <M(l) <(2072,28+286,3),
т.е. 1785,98 <M(l) <2358,58 рублей. Таким образом,
с вероятностью
 =1-0,05=0,95
математическое ожидание дохода будет
находиться в интервале от 1785,98 руб. до
2358,58 руб. и только 5% значений генеральной
=1-0,05=0,95
математическое ожидание дохода будет
находиться в интервале от 1785,98 руб. до
2358,58 руб. и только 5% значений генеральной
совокупности будут иметь математическое ожидание вне этого интервала.
Относительная точность оценки математического ожидания
По формуле (13)

Это значит, что половина ширины доверительного интервала составляет 13% от величины среднего значения, и характеризует, таким образом, относительную точность оценки математического ожидания. Другими словами, с доверительной вероятностью =0,95. Относительная ошибка при оценке среднего значения не превысит ±13%
Размах вариации результатов
эксперимента составляет w=4501–882=3619
рублей, а коэффициент вариации

Из этого следует, что размах колебаний выборки вокруг среднего значения составляет 60%.
Нормативное значение доходов, скорректированное к уровням зарплат составляет 2358 рублей. Из анализа результатов расчета следует, что нормативное значение ресурса соответствует интервалу k=3 с границами [1974; 2520] рублей.
Для данного интервала m3 =0.28, это значит, что уровень дохода 28% из числа обследованных, соответствует нормативному ресурсу.
Значение оценки интегральной функции в интервале k=2 с границами [1428; 1974] рублей равно 0,46. Из этого следует, что 46% доходов имеют размер менее нормативного, из них 10% (m1 =0,1) имеют доход в интервале [882; 1428] рублей;
6% – в интервале [2520; 3066] рублей (m4=0,06); 4% – в интервале [3066; 3612] рублей (m5 =0,04), 4% – в интервале [3612; 4158] рублей (m6 =0,04) и 2% дохода – в интервале [4158; 4704] рублей (m7= 0,02).

Выводы
Изучив теоретический материал и разобрав пример статистической обработки результатов эксперимента, выполнила статистическую обработку для выборки значений некоторого непрерывного количественного признака, объем выборки n = 50.