

5 / ИИиМО_ЛР5_decisiontree
.pdfЛабораторная работа № 5
Методы классификации (Деревья решений)
Основная цель
Обучающийся должен получить следующие знания, умения и навыки:
изучить понятие и метод классификации деревья решений; научиться реализовывать деревья решений с помощью ПП «Deductor Studio» и в среде программирования Python.
Задание:
Реализовать классификацию с помощью деревьев решений.
Исходные данные должны иметь не менее 300 наблюдений.
Проанализировать изменения в классификации в зависимости от способа разделения исходного множества на тестовое и обучающее и параметров метода, параметров обучения дерева решений, способ построения.
Реализация метода в ПП «Deductor Studio» обязательна и представлена в методических указаниях.
Реализация с помощью среды программирования обязательна, при этом обучающийся может реализовать метод в R или Python.
Пример реализации в Python представлен в файле decisiontree.py
Данные можно найти в следующих источниках:
https://www.kaggle.com/datasets
http://www.gks.ru/
Результатом выполнения задания в ПП «Deductor Studio» являются проект в формате *.ded, исходный файл с данными и отчет, содержащий следующую информацию: ход выполнения работы с описанием и скриншотами выполнения, результаты выполнения (интерпретация полученных результатов,
выводы по анализу изменения классификации в зависимости от различных параметров).
Результатом выполнения задания в R или Python являются рабочие файлы реализации, исходный файл с данными и отчет, содержащий следующую информацию: ход выполнения работы с описанием и скриншотами выполнения, результаты выполнения (интерпретация полученных результатов,
выводы по анализу изменения классификации в зависимости от различных параметров).
В отчете необходимо указать ссылку на исходные данные.
Для успешной защиты лабораторной работы студенты должны предоставить проект (папка с рабочими файлами Deductor, программа с моделью, исходные данные к модели в формате *.txt или *.csv) и отчет к нему,
ответить на заданные вопросы преподавателя.
Требования к оформлению отчета:
Способ выполнения текста должен быть единым для всей работы. Шрифт –
Times New Roman, кегль 14, межстрочный интервал – 1,5, размеры полей:
левое – 30 мм; правое – 10 мм, верхнее – 20 мм; нижнее – 20 мм. Сокращения слов в тексте допускаются только общепринятые.
Абзацный отступ (1,25) должен быть одинаковым во всей работе.
Нумерация страниц основного текста должна быть сквозной. Номер страницы на титульном листе не указывается. Сам номер располагается внизу по центру страницы или справа.

Методические указания к выполнению
Для выполнения данного задания необходимо скачать программный продукт с сайта https://basegroup.ru/deductor/download. С методическими рекомендациями по работе в приложении (Руководство аналитика Deductor 5.3) можно ознакомиться на сайте https://basegroup.ru/deductor/manual/guide- analyst-530.
Классификация с помощью деревьев решений
Для классификации с помощью деревьев решений используем исходные данные «Seed_Data» (https://archive.ics.uci.edu/ml/datasets/seeds).
Исходные данные представляют собой измерения геометрических свойств зерен пшеницы, принадлежащих к трем различным сортам. Каждое зерно характеризуется следующими параметрами: площадь (A), периметр (P),
компактность (C), длина зерна (LK), ширина зерна (WK), коэффициент асимметрии (A_Coef), длина углубления зерна (LKG). Целевая переменная
(target) показывает принадлежность к одному из трех классов – сортов пшеницы.
Импортируем файл (рис.1-6).
Рисунок 1 – Импорт данных (шаг 1)
Далее перейдем к настройке параметров импорта. В качестве разделителя

целой и дробной части – точка (рис. 2). Символом-разделителем является запятая (рис. 3).
Рисунок 2 – Импорт данных (шаг 3)
Рисунок 3 – Импорт данных (шаг 4)
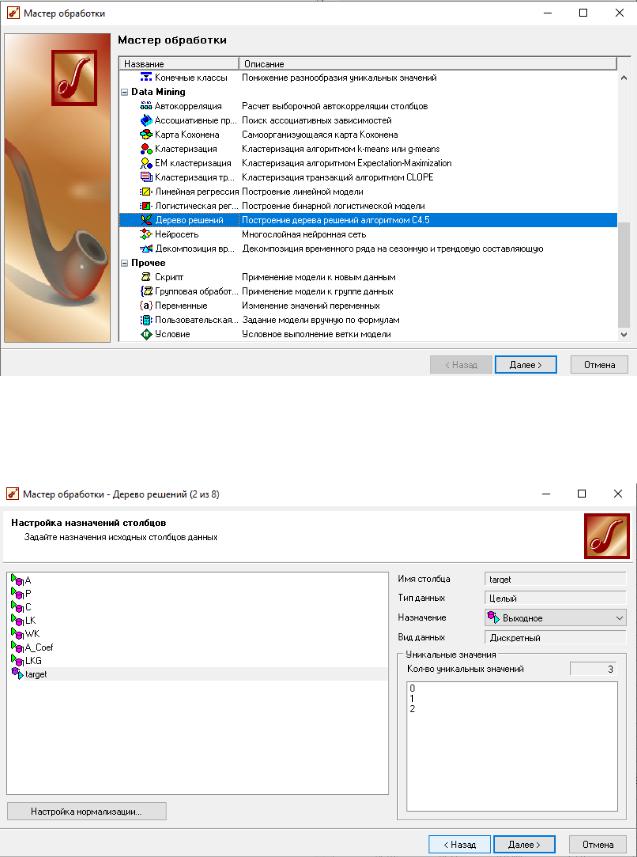
Назначение целевой переменное – выходное, тип данных – целый,
дискретный. Для остальных переменных зададим тип данных – вещественный,
непрерывный, назначение – входное (рис. 4).

Рисунок 4 – Импорт данных (шаг 6)
Рисунок 5 – Импорт данных (шаг 7)
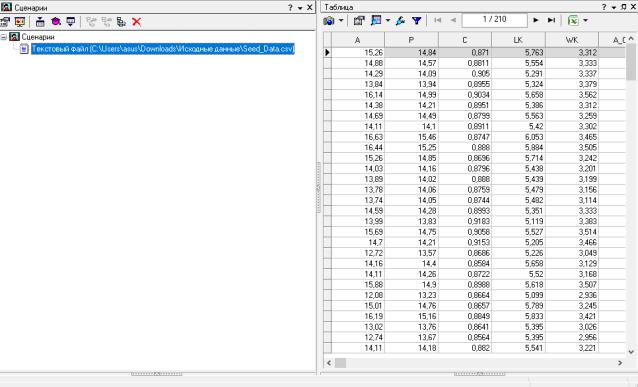
Рисунок 6 – Фрагмент импортированных данных
Дерево представляет собой набор условий (правил), согласно которым данные относятся к тому или иному классу. Также после построения присутствует информация о достоверности того или иного правила, его значимость. С помощью данного инструмента можно узнать ранг значимости каждого фактора (наиболее значимые факторы находятся на верхних уровнях дерева).
Для решения задачи запустим мастер обработки. Выберем в качестве обработки дерево решений (рис. 7). В мастере построения дерева решения на втором шаге настроим «target» – как выходной, остальные поля – входные
(рис.8). Далее предлагается настроить способ разбиения исходного множества данных на обучающее и тестовое. Зададим случайный способ разбиения, когда данные для тестового и обучающего множества берутся из исходного набора случайным образом (рис. 9). На следующем шаге мастера предлагается настроить параметры процесса обучения, а именно минимальное количество примеров, при котором будет создан новый узел
(пусть узел создается, если в него попали два и более примеров), а также
предлагается возможность строить дерево с более достоверными правилами,
и параметры отсечения узлов. Включим данные опции (рис.10).
Рисунок 7 – Мастер обработки: дерево решений

Рисунок 8 – Настройка входных и выходных данных
Рисунок 9 – Настройка алгоритма «Дерево решений»
(тестовое множество)
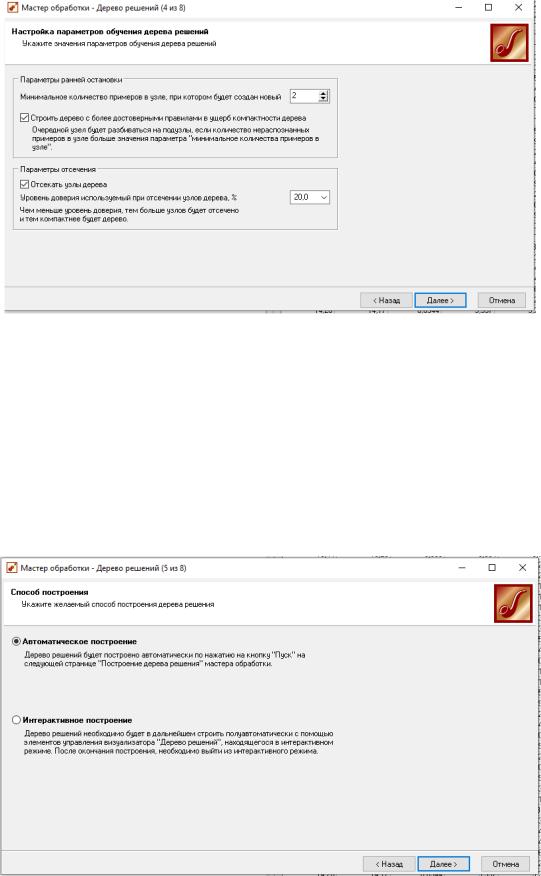
Рисунок 10– Настройка алгоритма «Дерево решений»
(параметры обучения)
Для построения дерева решений нужно выбрать автоматический способ построения (рис. 11). На следующем шаге мастера запускается сам процесс построения дерева. Также можно увидеть информацию о количестве распознанных примеров (рис.12).
Рисунок 11 – Настройка алгоритма «Дерево решений»
(способы построения)

Рисунок 12 – Настройка алгоритма «Дерево решений»
(построение дерева решений)
После построения дерева можно увидеть, что почти все примеры и на обучающей и на тестовой выборке распознаны. Перейдем на следующий шаг мастера для выбора способа визуализации полученных результатов.
Основной целью аналитика является отнесение зерна к тому или иному классу пшеницы. Механизм отнесения должен быть таким, чтобы по определенным параметрам зерна можно было отнести к определенному классу сорта пшеницы. Такой механизм предлагает визуализатор «Что-
если». Не менее важным является и просмотр самого дерева решений, на которое можно определить, какие факторы являются более важными
(верхние узлы дерева), какие второстепенные, а какие вообще не оказывают влияния (входные факторы, вообще не присутствующие в дереве решений).
Поэтому выберем также и визуализатор «Дерево решений».
Формализованные правила классификации, выраженные в форме «Если
<Условие>. Тогда <Класс>» можно увидеть, выбрав визуализатор «Правила
(дерево решений)». Часто аналитику бывает полезно узнать, сколько