

Отчет_Лаба2_ИИ_и_МО_Алексеева
.docУфимский государственный авиационный технический университет
ОТЧЕТ по лабораторной работе №2
по дисциплине:
«Искусственный интеллект и машинное обучение»
на тему:
«Методы кластеризации.»
Выполнили: бакалавры гр. ПРО-223
Алексеева А. В.
Исламгареев И. Д
Проверил: Юдинцев Богдан Сергеевич
1 Цель работы
Получить следующие знания, умения и навыки:
изучить вопрос кластеризации: методы k-means, алгоритм CLOPE;
научиться реализовывать методы и алгоритмы кластеризации с помощью различных инструментов (например, ПП «Deductor Studio»).
2 Задание
1. Реализовать кластеризацию данных методом k-means. Исходные
данные должны иметь не менее 300 наблюдений. Проанализировать
изменения в кластеризации в зависимости от способа разделения
исходного множества на тестовое и обучающее и параметров
метода, проанализировать результаты кластеризации в зависимости
от числа кластеров. Реализация метода в ПП «Deductor Studio»
представлена в методических указаниях.
2. Применить алгоритм кластеризации k-means, реализованный на
Python (программа прилагается к методическому материалу) к
своим исходным данным с параметрами «по-умолчанию». Изменить
один из параметров (например, ошибку или количество итераций
алгоритма), применить алгоритм повторно и сделать выводы по
результатам.
3. Реализовать кластеризацию транзакций методом CLOPE. Исходные
данные должны иметь не менее 300 наблюдений, данные должны быть в
виде номера транзакции и транзакции в виде наименования свойствазначения свойства. Проанализировать изменения в кластеризации
транзакций в зависимости от способа разделения исходного множества
на тестовое и обучающее и параметров метода, проанализировать
результаты кластеризации в зависимости от числа кластеров.
2 Теоретические основы
Кластеризация — это разделение множества входных векторов на группы (кластеры) по степени «схожести» друг на друга.
Алгоритм k-means (k-средних) Наиболее простой, но в то же время достаточно неточный метод кластеризации в классической реализации. Он разбивает множество элементов векторного пространства на заранее известное число кластеров k. Действие алгоритма таково, что он стремится минимизировать среднеквадратичное отклонение на точках каждого кластера. Основная идея заключается в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике. Алгоритм завершается, когда на какой-то итерации не происходит изменения кластеров.
Проблемы алгоритма k-means:
* необходимо заранее знать количество кластеров. Мной было предложено метод определения количества кластеров, который основывался на нахождении кластеров, распределенных по некоему закону (в моем случае все сводилось к нормальному закону). После этого выполнялся классический алгоритм k-means, который давал более точные результаты.
* алгоритм очень чувствителен к выбору начальных центров кластеров. Классический вариант подразумевает случайный выбор класторов, что очень часто являлось источником погрешности. Как вариант решения, необходимо проводить исследования объекта для более точного определения центров начальных кластеров. В моем случае на начальном этапе предлагается принимать в качестве центов самые отдаленные точки кластеров.
* не справляется с задачей, когда объект принадлежит к разным кластерам в равной степени или не принадлежит ни одному.
Алгоритм CLOPE (Clustering with sLOPE) — неиерархический итеративный метод кластерного анализа, предназначенный для обработки больших наборов категориальных данных.
Алгоритм CLOPE в изначальной формулировке является алгоритмом кластеризации транзакционных данных (под транзакцией понимается некоторый произвольный набор объектов конечной длины). Основной идеей данного метода является использование глобального критерия оптимизации на основе максимизации функции стоимости применительно к задачам кластеризации.
Во время выполнения алгоритма в оперативной памяти требуется хранить относительно малое количество информации о каждом кластере и производится минимальное число проходов по набору данных. При использовании метода CLOPE количество кластеров подбирается автоматически и зависит от коэффициента отталкивания — параметра, определяющего уровень сходства транзакций внутри кластера. Коэффициент отталкивания задается пользователем: чем больше данный параметр, тем ниже уровень сходства транзакций и, как следствие, большее количество кластеров будет создано.
Результат выполнения работы
1 Задание
Реализована кластеризация данных методом k-means. Проанализированы
изменения в кластеризации в зависимости от способа разделения
исходного множества на тестовое и обучающее и параметров
метода, проанализированы результаты кластеризации в зависимости
от числа кластеров.
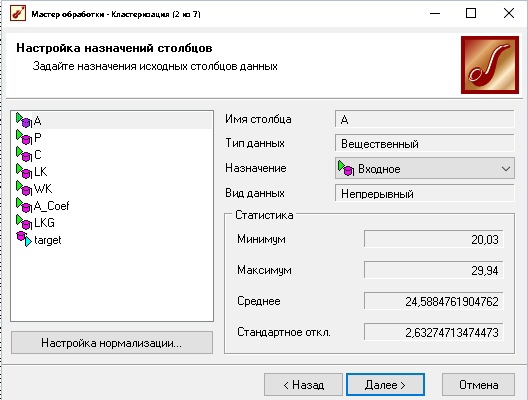
Рисунок 1 Настройка параметров данных
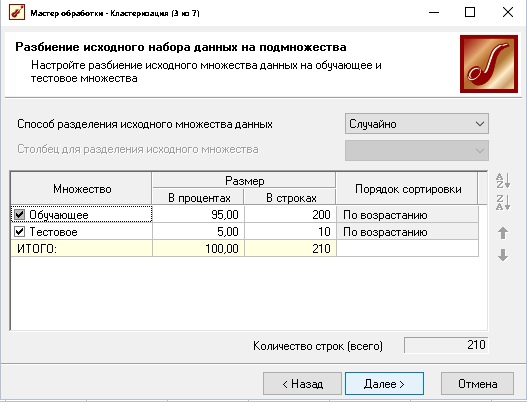
Рисунок 2 Настройка тестового множества
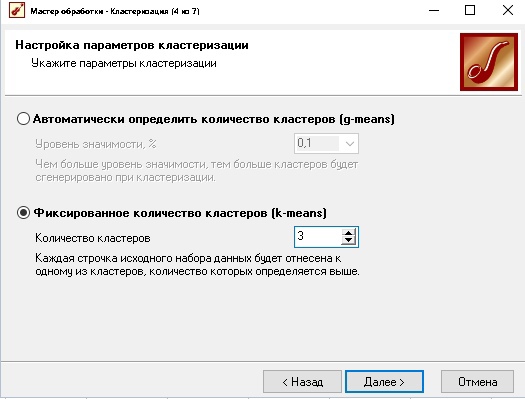
Рисунок 3 Настройка параметров кластеризации

Рисунок 4 – Кластеризация набора данных
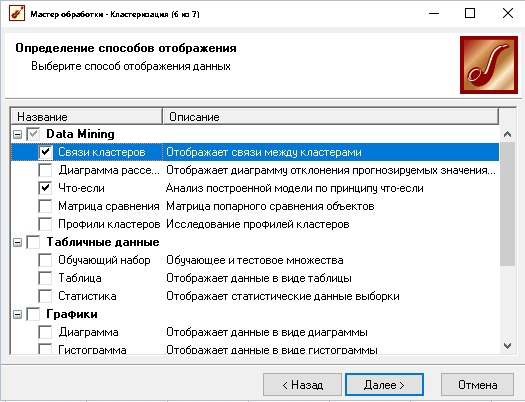
Рисунок 5 Определение способов отображения данных

Рисунок 6 Результаты кластеризации в виде связи кластеров
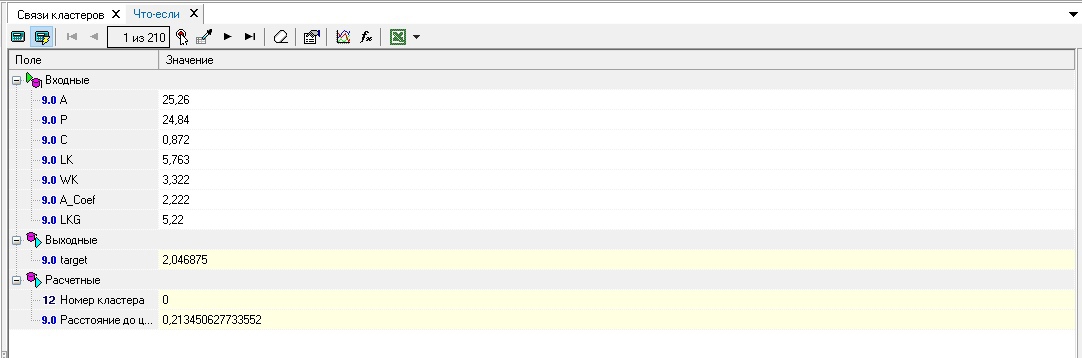
Рисунок 7 Результаты кластеризации в виде связи что – если

Рисунок 8 Результаты кластеризации в виде профилей кластеров

Рисунок 9 Настройка параметров кластеризации для сравнения с предыдущим результатом. Количество кластеров = 5
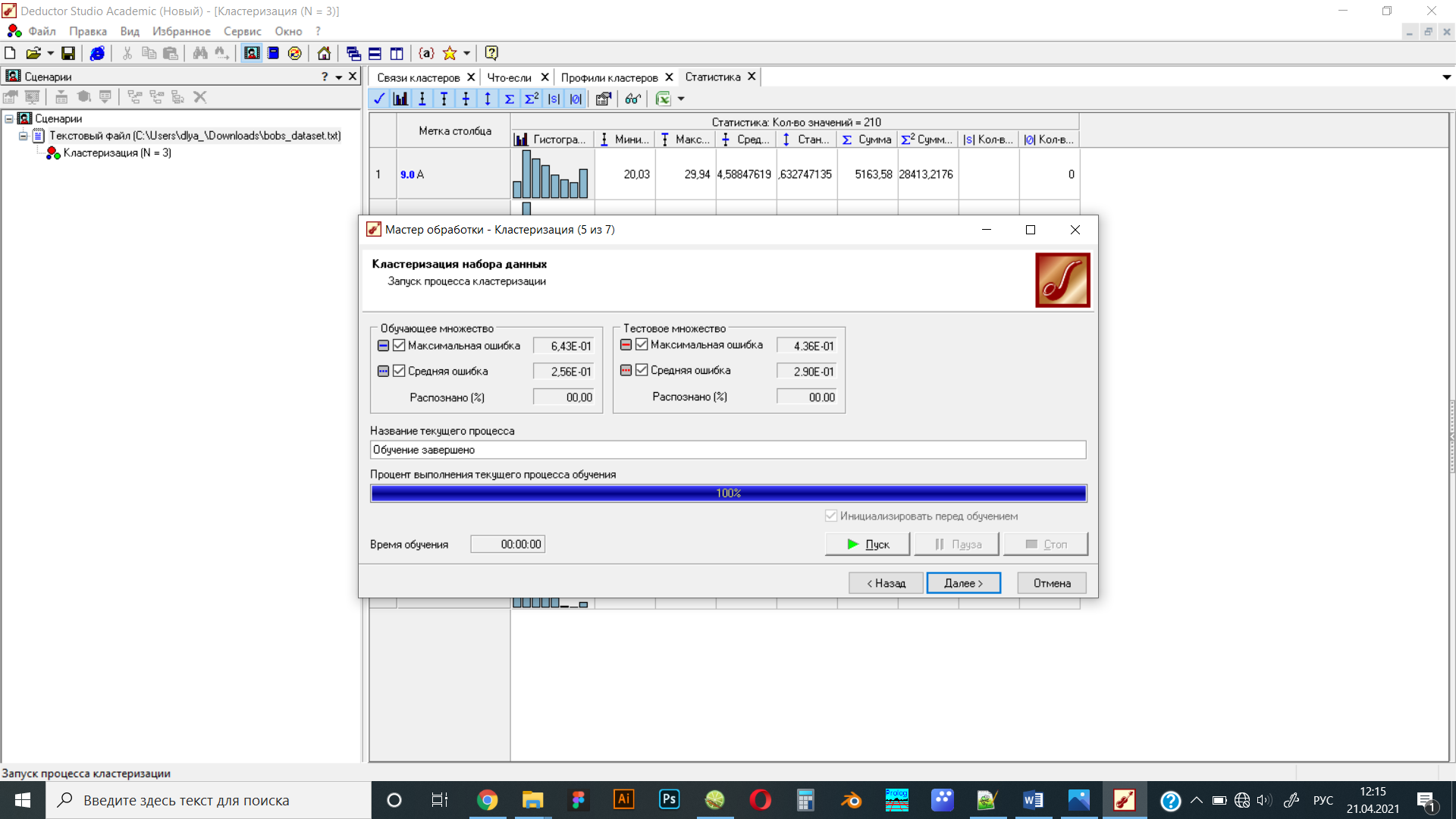
Рисунок 10 При количестве кластеров, равном пяти, размер ошибки уменьшается, так как при увеличении кластеров элементы соединяются в более узкие группы, тем самым отличие между элементами становится меньше, чем при меньшем количестве кластеров
Вывод по заданию: При изменении количества кластеров изменился диапазон разброса и погрешности. Т.е. алгоритм заранее разбивает множество элементов базы данных на указанное количество кластеров, в нашем случае количество кластеров равно 3 и 5. Чем больше кластеров, тем меньше диапазон разброса и погрешности.
2 задание
Применен алгоритм кластеризации k-means, реализованный на
Python к своим исходным данным с параметрами «по-умолчанию». Изменен
один из параметров и повторно применен алгоритм.

Рисунок 11 Результаты работы программы
Легенда к базе данных:
А – площадь плода
P – периметр плода
С – компактность плода
LK – длина плода
WK – ширина плода
A_Coef – коэффициент ассиметрии плода
LKG – длина углубления плода
Target – сорт плода

Рисунок 12 Результаты работы программы

Рисунок 13 Результат работы программы (диаграммы)
Вывод по заданию: программа выводит количество кластеров для всех наборов данных, а также выводит координаты каждого кластера.
Исходя из работы программы, можно сделать вывод, что наиболее значимые параметры по которым происходит кластеризация данных – это LKG и A_Coef.
3 задание
Реализована кластеризация транзакций методом CLOPE.
Проанализированы изменения в кластеризации транзакций в зависимости от параметров метода, проанализированы результаты кластеризации в зависимости от числа кластеров.
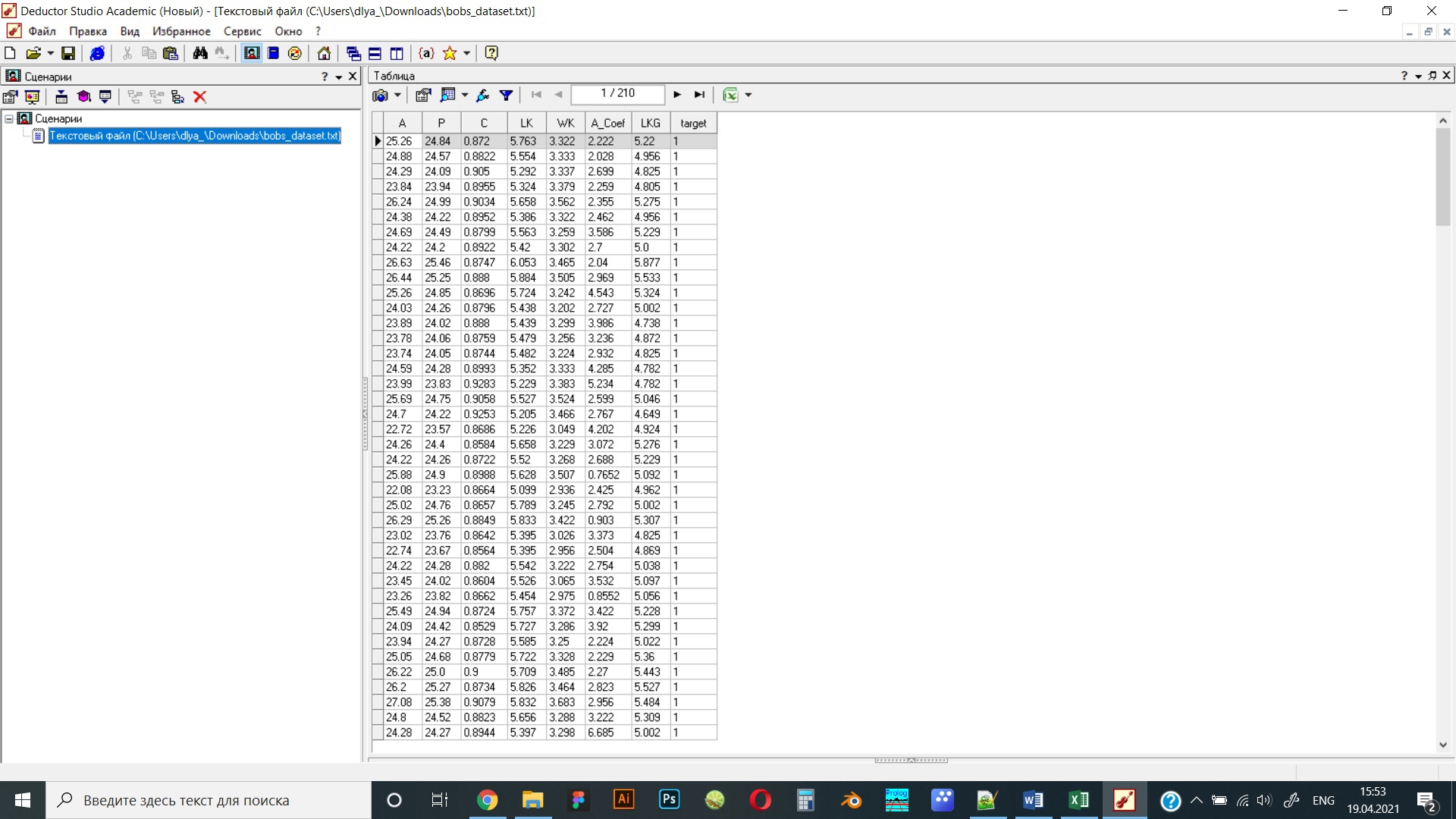
Рисунок 14 Фрагмент импортированных данных
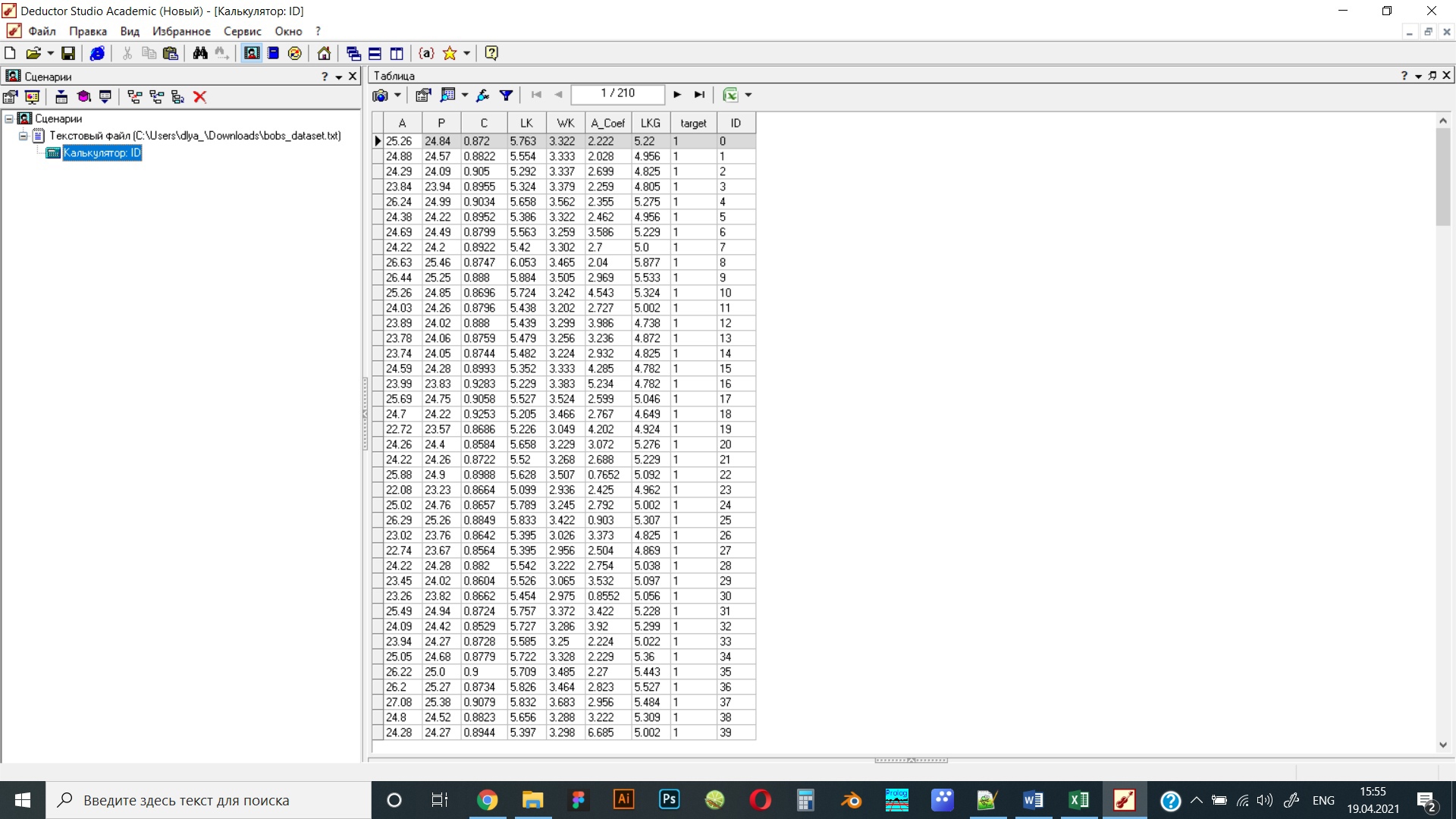
Рисунок 15 – Приведение данных к транзакционному виду: фрагмент таблицы с добавленными ID
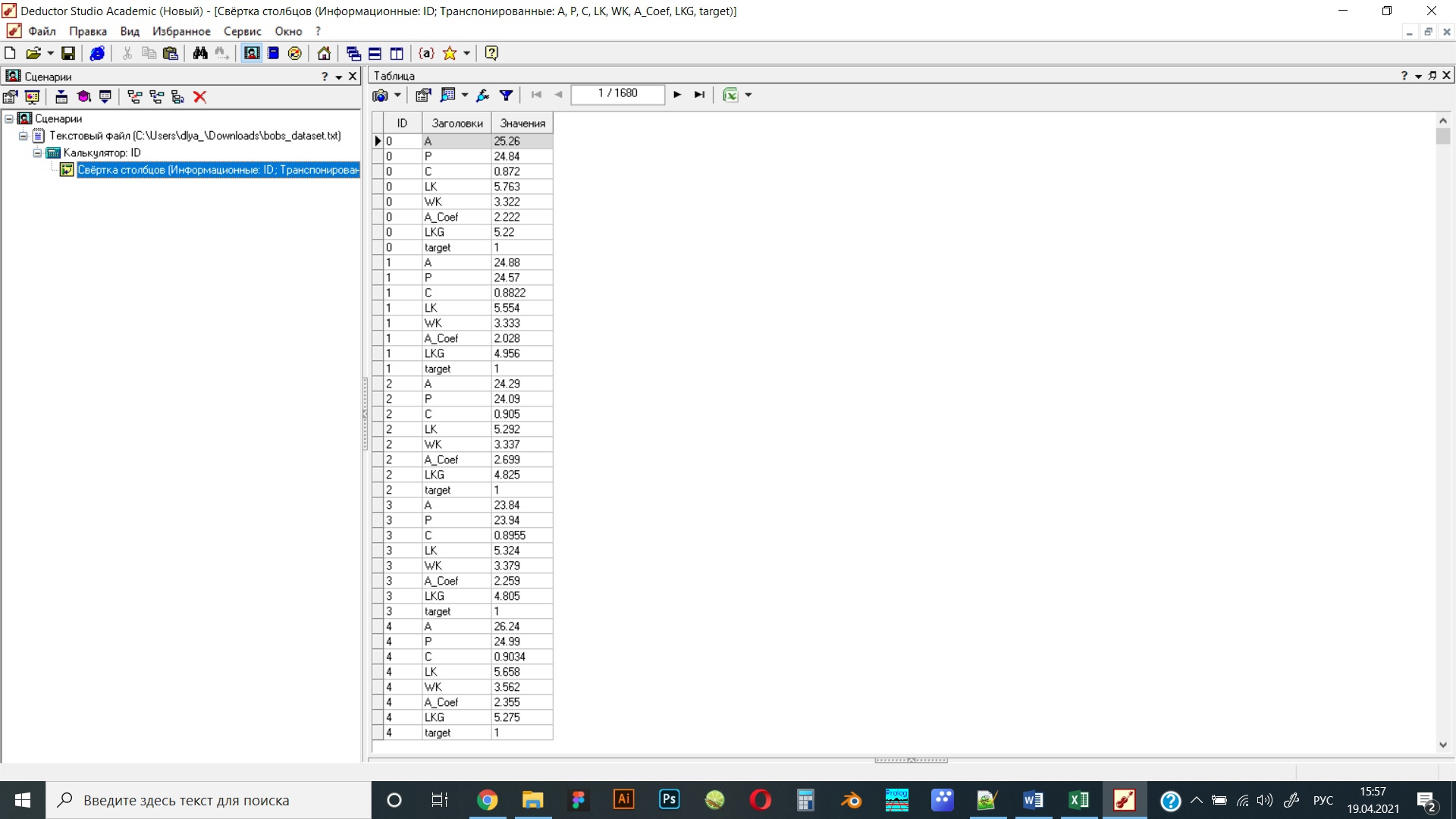
Рисунок 16 Свертка столбцов
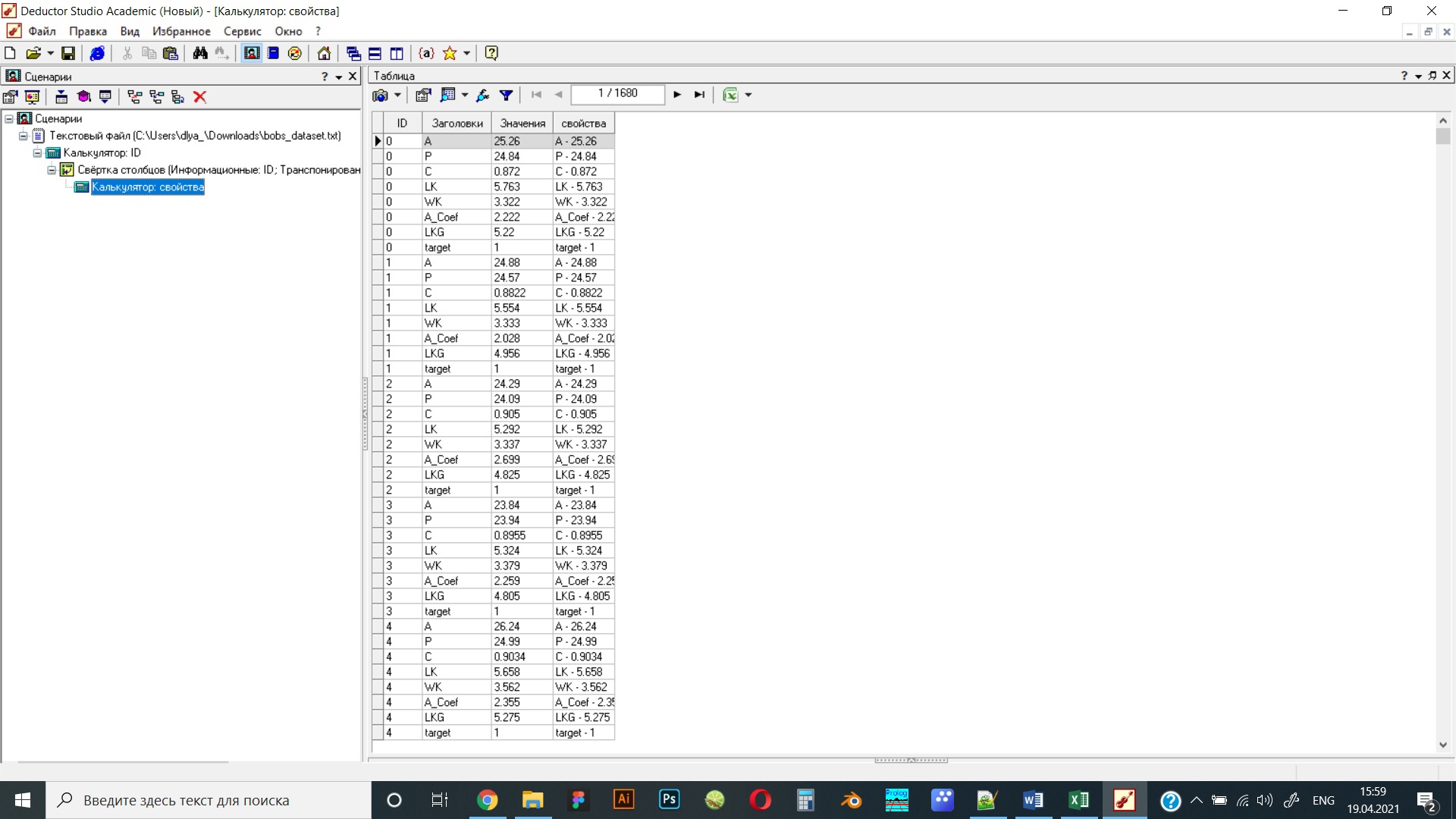
Рисунок 17 Объединение полей с названиями характеристик
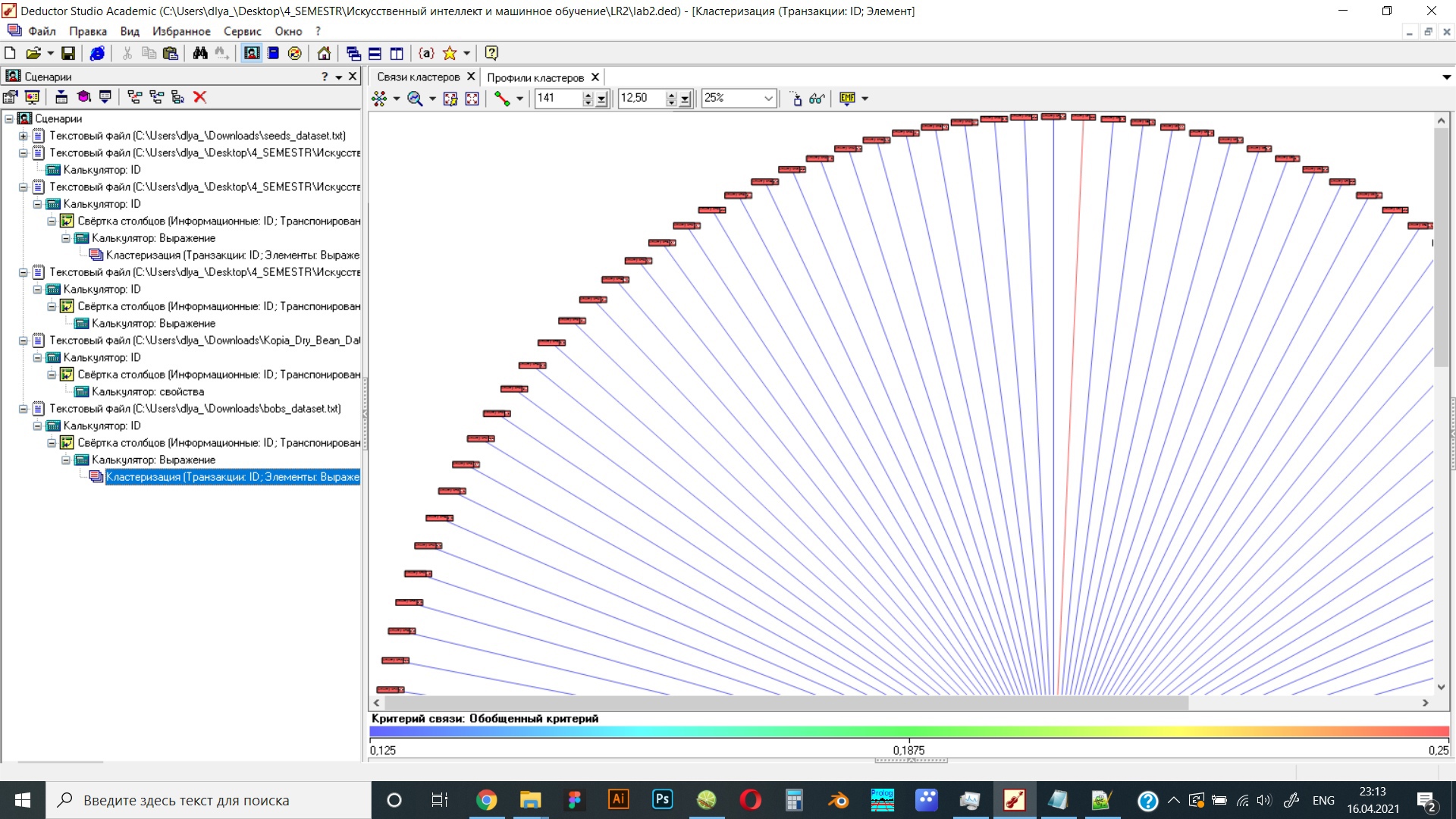
Рисунок 18 Результат работы программы в виде связи кластеров при коэффициенте отталкивания 2,6 (рисунок 1)
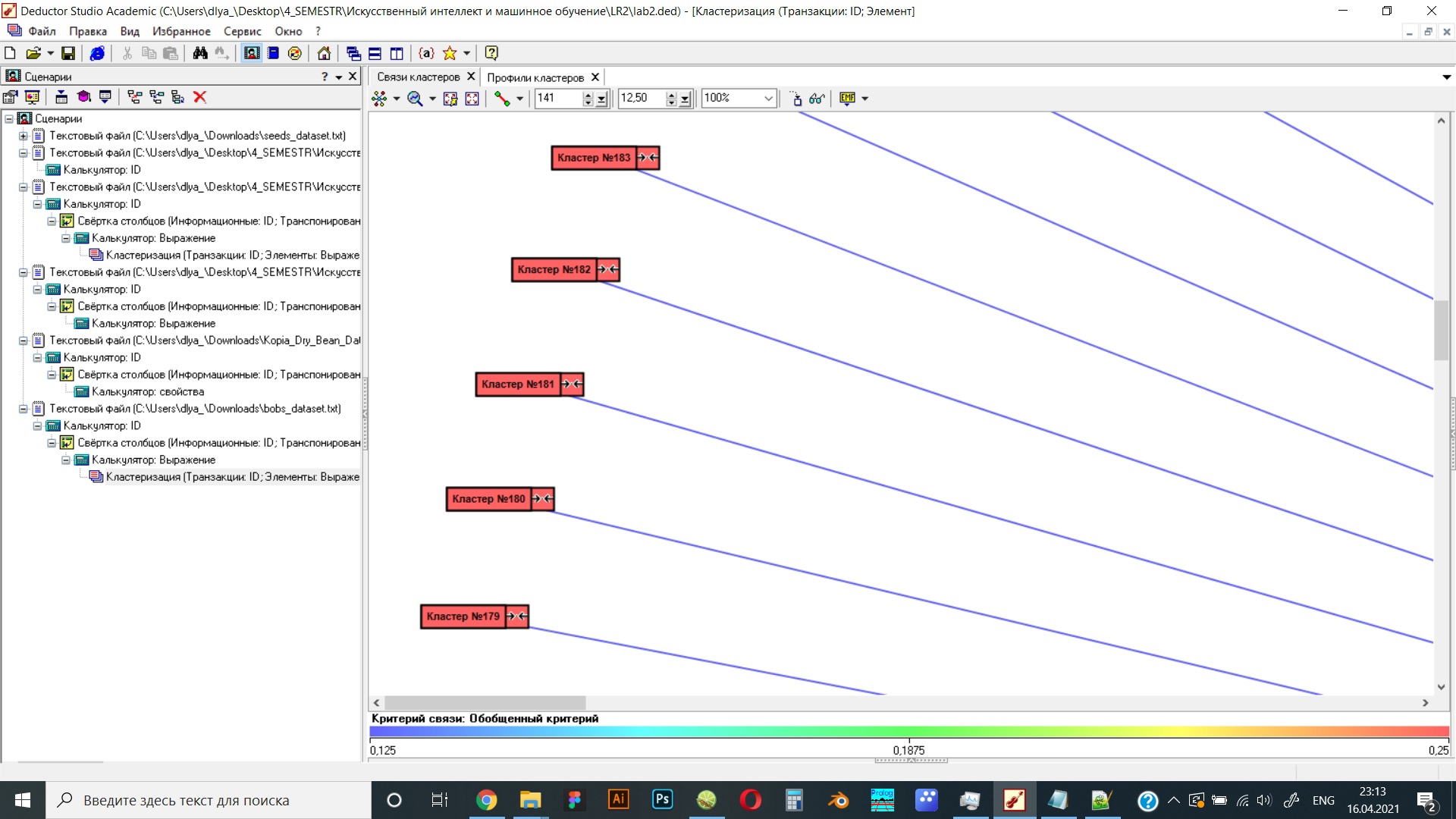
Рисунок 19 Результат работы программы в виде связи кластеров при коэффициенте отталкивания 2,6 (рисунок 2)
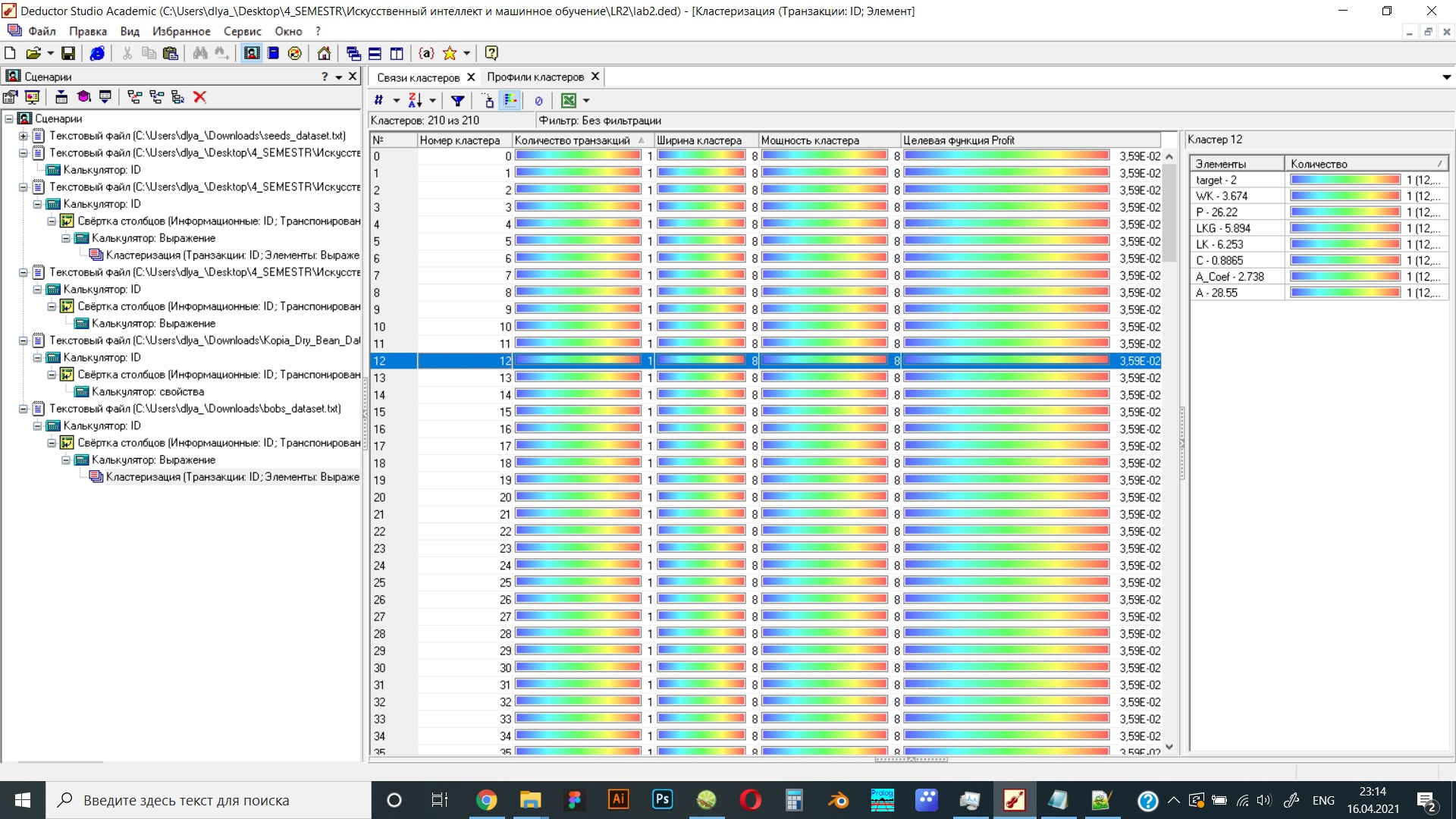
Рисунок 20 Результат работы программы в виде профилей кластеров при результате отталкивания 2,6

Рисунок 21 Результат работы программы в виде профилей кластеров при результате отталкивания 8

Рисунок 22 Результат работы программы в виде связи кластеров при коэффициенте отталкивания 8
Вывод по заданию: Алгоритм с помощью коэффициента отталкивания, который отвечает за сходство транзакций, определяет связи между кластерами.
Можно заметить, что чем меньше коэффициент отталкивания, тем ниже уровень транзакций, и, следовательно, будет больше кластеров.
Вывод
Получили следующие знания, умения и навыки:
• изучили вопрос кластеризации: методы k-means, алгоритм CLOPE;
• научились реализовывать методы и алгоритмы кластеризации с помощью различных инструментов (например, ПП «Deductor Studio»).
Уфа – 2020