

4 / Работа с логистической регрессией в Python
.pdf1. Определение признака для классификации. Выбираем признак для классификации и выводим соотношения записей по классам. Например, для рассматриваемого набора данных (файл export.csv) рассмотрим классификацию по признаку «Кол-во покупок нового товара», т.н. скоринг-отклик - оценка отклика потребителя на направление ему предложения (0 – есть покупка, 1 – нет покупки). Приведем данную колонку к бинарному виду и выведем распределение по классам:
2. Анализ значимости признаков для классификации. Например, очевидно, такие признаки как "Клиент. код" и "Дата актуальности" не представляют никакой полезности при данной классификации, т.о. удаляем их из анализируемого набора данных
dataset = dataset.drop(['Клиент.Код'], axis=1)
dataset = dataset.drop(['Дата актуальности'], axis=1)
Для неочевидных случаев используем построение графиков кросс-табуляции или считаем соотношение количества записей в классе 1 и в классе 0 по данному признаку. Например, если рассмотреть колонку «Округ», то распределение по классам для каждого практически не меняется:

Округ 1/0 class relation:
0.3391139839192811
0.30019120458891013
0.3036041539401344
0.33710407239819007
0.3072463768115942
Т.о. данный признак малозначим для классификации и его можно удалить.
Примером хорошего признака является колонка «Статус». Построим для данного признака график кросс-табуляции:
plot_crosstab(dataset, 'Статус', 'y')
Это также видно по распределению по классам в каждой категории
Статус 1/0 class relation:
0.5463675929025779
0.29132947976878615
0.1991869918699187
0.4051844932274638
Если в наборе данных встречаются «пробелы» или недопустимые значения в какихлибо признаках и эти признаки являются значимыми для классификации, то эти строки
можно удалить, если оставшихся записей достаточно для обучения модели с необходимой точностью.
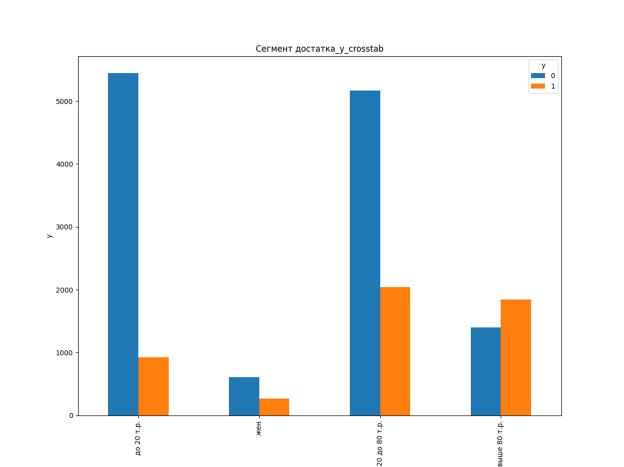
Например, признак «Сегмент достатка»:
Это значимый признак для классификации, но т.к. небольшое количество трок содержат ошибочные значения ('жен'), поэтому удаляем эти строки, чтобы повысить точность классификации:
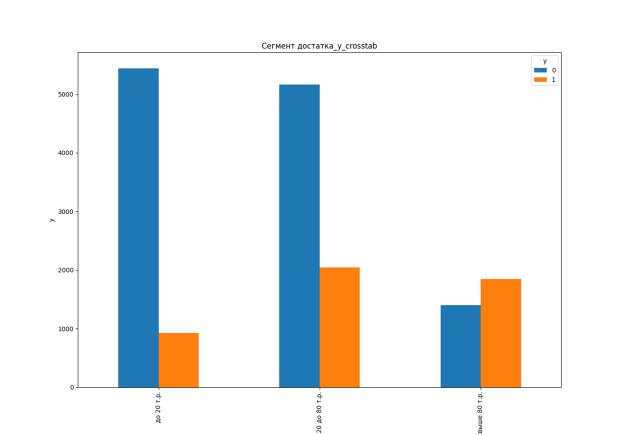
Также можно заполнить ошибочные или пропущенные значения, используя, например, такое же количественное отношение, как и в заполненных полях.
Некоторые признаки могут содержать слишком много категорий, что может негативно сказываться на качестве обучения модели. Например, если посчитать количество уникальных значений в колонке «Счет»:
pd.unique(dataset['Счет']).size
Количество категорий в колонке 'Счет': 2143 ,
То можно сделать вывод, что необходима группировка значений по категориям: до
1000 р., до 5000 р. и т.д.
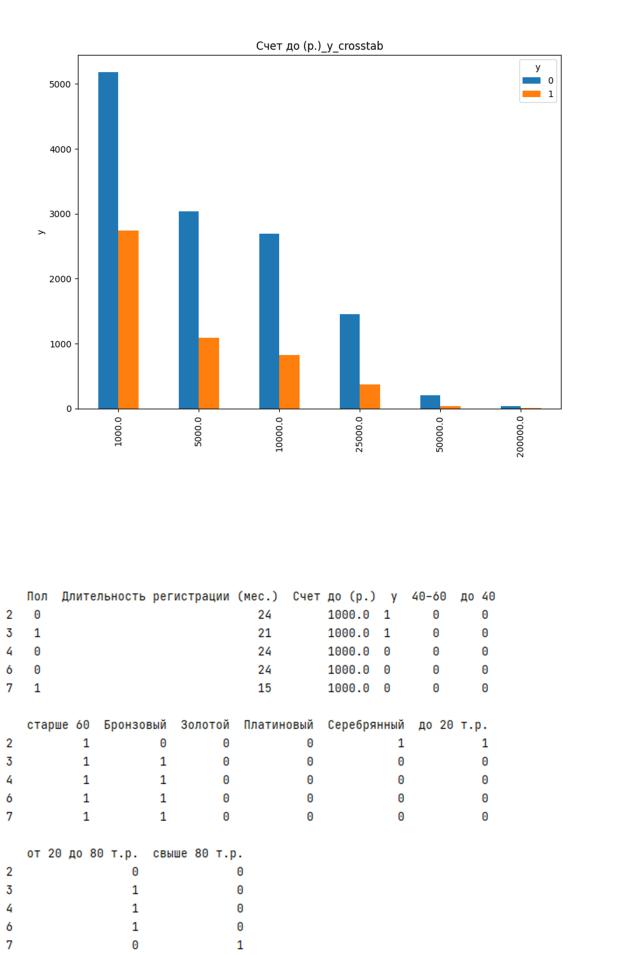
Также для корректной работы алгорима необходимо нормализовать категориальные признаки, такие как, например, в колонке 'Статус' ("Золотой", "Платиновый" и т.п.) с помощью one-hot (бинарного) кодирования.
Итоговый вид набора данных после предварительно обработки:
Для дополнительной оценки используемых для классификации признаков можно также применить встроенный в пакет sklearn рекурсивный алгоритм оценки (RFE), который определит оценки признаков в виде True/False для каждого:
[('Пол', True), ('Длительность регистрации (мес.)', True), ('Счет до (р.)', True), ('40-60', True), ('до 40', True), ('старше 60', True), ('Бронзовый', True), ('Золотой', True), ('Платиновый', True), ('Серебрянный', True), ('до 20 т.р.', True), ('от 20 до 80 т.р.', True), ('свыше 80 т.р.', True)]
3. Обучение классификатора и оценка качества обученной модели. Разделяем из общего набора данных тренировочную (70%) и тестовую выборку (30%). Параметр stratify=out_data позволяет делать выборку с сохранением пропорции распределения классов (как в множестве out_data, где представлено «Кол-во покупок нового товара»):
in_data_train, in_data_test, out_data_train, out_data_test = train_test_split(in_data, out_data, test_size=0.3, stratify=out_data)
Создаем модель классификатора (Логистическая регрессия):
logreg = LogisticRegression(C=reg) ,
где reg = 1.0 - коэффициент регуляризации (чем меньше значение, тем сильнее регуляризация, что влияет на итоговую точность модели)
Обучаем наш классификатор
logreg.fit(in_data_train, out_data_train)
Оценка точности классификатора для тестового набора после обучения:
score = logreg.score(in_data_test, out_data_test)
Точность классификатора (score): 0.7806328307496284
Прогнозирование на обученной модели:
y_predicted= logreg.predict(in_data_test)
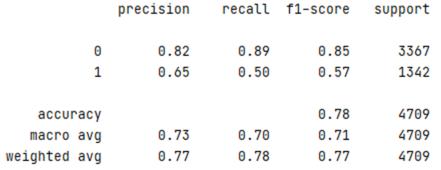
Вывод итогового отчета по результатам прогнозирования:
print(classification_report(out_data_test, y_predicted))
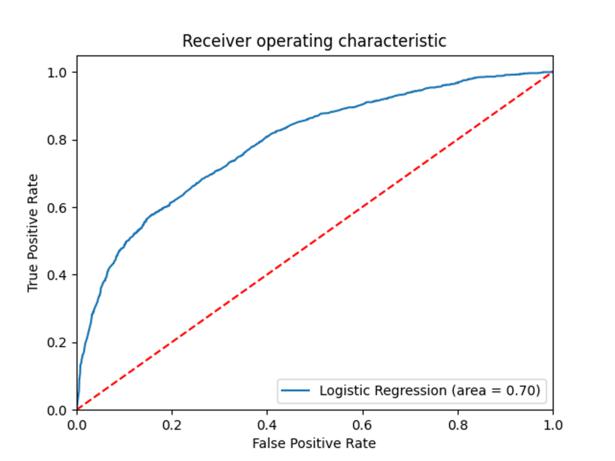
Вывод ROC-кривой:
plot_ROC(logreg, in_data_test, out_data_test)