

лр5 вар17 (Информационный подход к построению оценок распределения по ограниченному числу опытных данных) — копия
.docxФЕДЕРАЛЬНОЕ АГЕНСТВО ПО ОБРАЗОВАНИЮ
ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧЕРЕЖДЕНИЕ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
УФИМСКИЙ ГОСУДАРСТВЕННЫЙ АВИАЦИОННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
Кафедра технической кибернетики
ОТЧЕТ
по лабораторной работе №5.
по дисциплине «Моделирование»
«Информационный подход к построению оценок распределения по ограниченному числу опытных данных»
Проверил:
Гвоздев В. Е.
Вариант 17.
Цель работы: Изучение специальных статистических методов анализа малых выборок.
Задание на работу:
1. На основе выборочных данных (Таблица 2 приложения), построить оценку неусеченного закона распределения.
2. Произвести сопоставление полученной оценки с нормальным законом распределения, у которого математическое ожидание и среднеквадратическое отклонение определены по выборочным данным Сопоставление произвести на основе метрик ХИ-квадрат и F-критерия Колмогорова (см. работу «Построение оценок законов распределения случайных величин по выборочным данным»).
Ход работы:
Исходные данные:
X |
17 |
1 |
18,5 |
2 |
17,2 |
3 |
17,1 |
4 |
18,6 |
5 |
18,0 |
6 |
17,4 |
7 |
18,2 |
8 |
17,9 |
9 |
17,7 |
10 |
18,1 |
11 |
17,2 |
12 |
17,6 |
13 |
18,6 |
14 |
17,5 |
15 |
17,7 |
16 |
17,7 |
17 |
17,1 |
18 |
18,7 |
19 |
18,4 |
20 |
17,9 |
21 |
17,5 |
22 |
17,6 |
23 |
18,3 |
24 |
17,3 |
25 |
18,5 |
26 |
17,7 |
27 |
18,5 |
28 |
17,8 |
29 |
17,0 |
30 |
17,6 |
Построим вариационный ряд из данной выборки:
X |
17 |
1 |
17,0 |
2 |
17,1 |
3 |
17,1 |
4 |
17,2 |
5 |
17,2 |
6 |
17,3 |
7 |
17,4 |
8 |
17,5 |
9 |
17,5 |
10 |
17,6 |
11 |
17,6 |
12 |
17,6 |
13 |
17,7 |
14 |
17,7 |
15 |
17,7 |
16 |
17,7 |
17 |
17,8 |
18 |
17,9 |
19 |
17,9 |
20 |
18,0 |
21 |
18,1 |
22 |
18,2 |
23 |
18,3 |
24 |
18,4 |
25 |
18,5 |
26 |
18,5 |
27 |
18,5 |
28 |
18,6 |
29 |
18,6 |
30 |
18,7 |
Задание 1
На основе выборочных данных, построить оценку неусеченного закона распределения.
Шаг
1.
Исходный интервал a,
b,
на котором возможны реализации случайной
величины X,
преобразуется таким образом, чтобы
нижняя граница интервала совпала с
началом координат
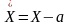 (при этом верхняя граница интервала
примет значение
(при этом верхняя граница интервала
примет значение
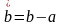 ).
Соответственно преобразуются данные
исходной выборки
).
Соответственно преобразуются данные
исходной выборки
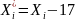
i |
Xi* |
1 |
0,0 |
2 |
0,1 |
3 |
0,1 |
4 |
0,2 |
5 |
0,2 |
6 |
0,3 |
7 |
0,4 |
8 |
0,5 |
9 |
0,5 |
10 |
0,6 |
11 |
0,6 |
12 |
0,6 |
13 |
0,7 |
14 |
0,7 |
15 |
0,7 |
16 |
0,7 |
17 |
0,8 |
18 |
0,9 |
19 |
0,9 |
20 |
1,0 |
21 |
1,1 |
22 |
1,2 |
23 |
1,3 |
24 |
1,4 |
25 |
1,5 |
26 |
1,5 |
27 |
1,5 |
28 |
1,6 |
29 |
1,6 |
30 |
1,7 |
Шаг 2. Оцениваются значения двух первых начальных моментов распределения
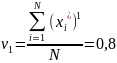
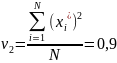
и
с помощью выражения
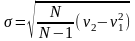 оценивается величина среднеквадратического
отклонения распределения.
оценивается величина среднеквадратического
отклонения распределения.
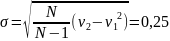
Шаг 3. Определяется значение первого нормированного начального момента
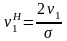

Шаг
4.
Если соблюдается условие
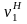 7.
то нормированные параметры распределения
определяются с помощью соотношений
7.
то нормированные параметры распределения
определяются с помощью соотношений
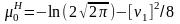
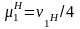
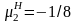
и
осуществляется переход к шагу 6. Т.к.
указанное условие в данном случае не
соблюдается ( ,
то переходим к шагу 5.
,
то переходим к шагу 5.
Шаг
5.
Вычисляются нормированные параметры
распределения с помощью выражения
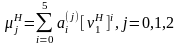
значения
коэффициентов полинома
 приводятся в таблице 2.1.
приводятся в таблице 2.1.
Таблица 1
-
j
0
1
2
a0
0.78760454
-0.23350401*101
0.19935077
a1
-0.25889486
0.88266373
-0.10402411
a2
-0.31872153
0.99215448*10-1
-0.7659968*10-2
a3
0.45243271*10-1
-0.52450713*10-1
0.64909123*10-2
a4
-0.27552103*10-2
0.62824786*10-2
-0.83410484*10-3
a5
0
-0.240757*10-3
0.33025782*10-4
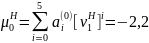
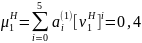

Шаг 6. Определяются ненормированные значения параметров распределения

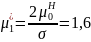
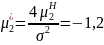
Шаг 7. Вычисляются значения параметров распределения, соответствующие исходному интервалу [17; 18,7]:

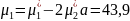
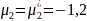
Отсюда
получим: f(x)=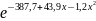 .
.


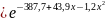

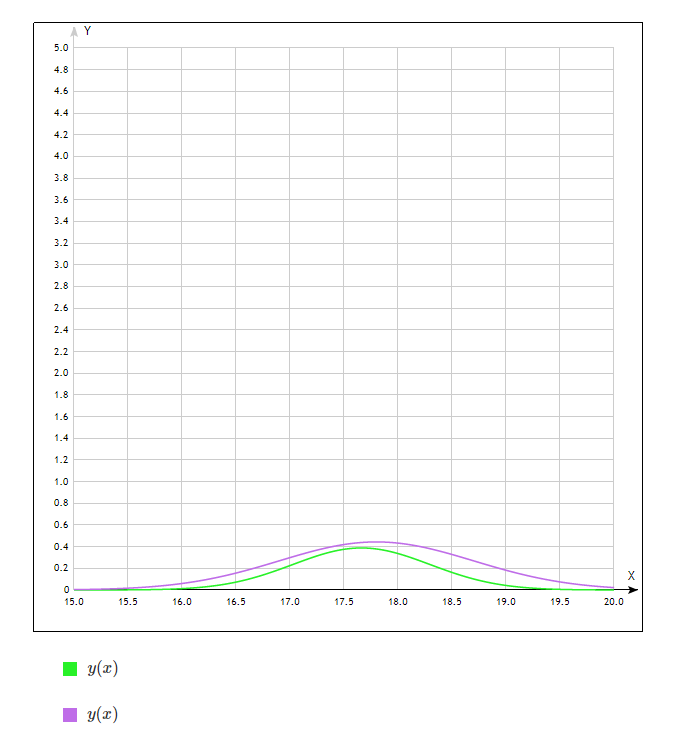
Рисунок 1 – Оценка функции распределения
Задание 2
Проверка
гипотезы о нормальном распределении
выборки с помощью критерия
 .
.
Xmin=17, xmax=18,7
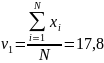
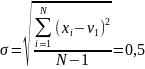
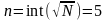
Разобьем интервал [17;18,7] на 5 частей: [17;17,34), [17,34;17,68), [17,68;18,02), [18,02;18,36), [18,36;18,7]
Номер интервала |
mi |
pi |
Npi |
|
1 |
6 |
0,12 |
3,6 |
1,6 |
2 |
6 |
0,22 |
6,6 |
0,05 |
3 |
8 |
0,26 |
7,8 |
0,005 |
4 |
3 |
0,19 |
5,7 |
1,28 |
5 |
7 |
0,09 |
2,7 |
6,8 |
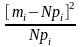
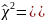
По
заданному уровню значимости
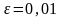 найдем
найдем
 .
Сопоставив
.
Сопоставив
 с
с
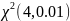 =13,28,
можем заключить, что гипотеза КАКАЯ???
о
нормальном распределении или как-то
так не
противоречит фактическим данным.
=13,28,
можем заключить, что гипотеза КАКАЯ???
о
нормальном распределении или как-то
так не
противоречит фактическим данным.
Проверка гипотезы о нормальном распределении выборки с помощью критерия Колмогорова.
Оценка
плотности распределения: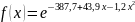 ,тогда
,тогда
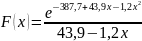 .
.
Xi |
F(x) |
Fнорм(x) |
F(x)-Fнорм(x) |
17,0 |
0,16 |
0,05 |
0,11 |
17,1 |
0,2 |
0,08 |
0,12 |
17,1 |
0,2 |
0,08 |
0,12 |
17,2 |
0,25 |
0,11 |
0,14 |
17,2 |
0,25 |
0,11 |
0,14 |
17,3 |
0,3 |
0,15 |
0,15 |
17,4 |
0,36 |
0,21 |
0,15 |
17,5 |
0,42 |
0,27 |
0,15 |
17,5 |
0,42 |
0,27 |
0,15 |
17,6 |
0,49 |
0,34 |
0,15 |
17,6 |
0,49 |
0,34 |
0,15 |
17,6 |
0,49 |
0,34 |
0,15 |
17,7 |
0,55 |
0,42 |
0,13 |
17,7 |
0,55 |
0,42 |
0,13 |
17,7 |
0,55 |
0,42 |
0,13 |
17,7 |
0,55 |
0,42 |
0,13 |
17,8 |
0,62 |
0,5 |
0,12 |
17,9 |
0,68 |
0,57 |
0,11 |
17,9 |
0,68 |
0,57 |
0,11 |
18,0 |
0,74 |
0,65 |
0,09 |
18,1 |
0,79 |
0,72 |
0,07 |
18,2 |
0,84 |
0,78 |
0,06 |
18,3 |
0,89 |
0,84 |
0,05 |
18,4 |
0,92 |
0,88 |
0,04 |
18,5 |
0,95 |
0,91 |
0,04 |
18,5 |
0,95 |
0,91 |
0,04 |
18,5 |
0,95 |
0,91 |
0,04 |
18,6 |
0,98 |
0,94 |
0,04 |
18,6 |
0,98 |
0,94 |
0,04 |
18,7 |
0,99 |
0,96 |
0,03 |
|
|
МАКС |
0,15 |
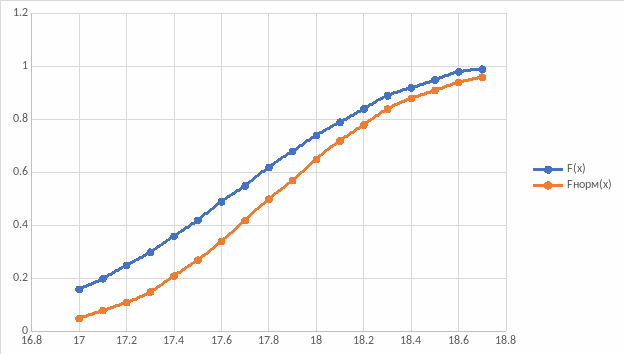
Рисунок 2 – График интегральной функции
Из Рисунок 2 – График интегральной функции видно, что наибольшее различие наблюдается в точке х=17,6 и составляет 0,15.
Возьмем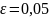 ,
тогда критические значения
,
тогда критические значения
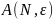 для наибольшего отклонения эмпирического
распределения от теоретического
(критерий Колмогорова) составит
для наибольшего отклонения эмпирического
распределения от теоретического
(критерий Колмогорова) составит
 .
.
Т.к.
 ,
следовательно гипотеза
о нормальном распределении не противоречит
фактическим данным.
,
следовательно гипотеза
о нормальном распределении не противоречит
фактическим данным.
Вывод: Был изучен информационный подход к построению оценок распределения по ограниченному числу опытных данных.
Ответы на контрольные вопросы:
В чем философская основа информационного метода.
Философская основа данного метода заключается в использовании только опытной информации.
В чем преимущество информационного метода по сравнению с эвристическими методами обработки малых выборок?
Преимущество заключается в использовании исключительно фактических данных, и как следствие получении более реальных результатов.
Каковы ограничения информационного метода оценивания законов распределения случайных величин?
Основным ограничением для данного метода является рост систематической погрешности, т.к. не учитываются особенности отдельных случаев.
ФОРМУЛИРОВКА ТАКАЯ ЖЕ КАК У ВСЕХ И СОВЕРШЕННО НЕПОНЯТНАЯ
5-
Эта лаба сделана по принципу импровизируй, адаптируйся, выживай. Графики из первой части реальным значениям нихуя не соответствуют, зато они красивые, а это главное. Под красивыми я подразумеваю, что площадь под графиком полученной функции стремится к единице и различия между значениями графика полученной функции и функции закона нормального распределения примерно похожи, а самое главное сопоставимы с результатами в табличке. Графики интегральных функций – моя гордость, красивые получились, а главное даже результаты вычислений не выдуманные, сказка. К вопросам понятное дело опять прикопался, но ниче, 5- поставил.