

Лабораторная работа №4
.docxМинистерство цифрового развития, связи и массовых коммуникаций
Российской Федерации Ордена Трудового Красного Знамени
федеральное государственное бюджетное образовательное
учреждение высшего образования
Московский технический университет связи и информатики
Кафедра «Математическая кибернетика и информационные технологии»
Лабораторная работа №4
по дисциплине
«Управление данными»
Москва 2023
Оглавление
Цель работы 2
Ход лабораторной работы 3
Вывод 18
Цель работы
Ознакомиться с методами ассоциативного анализа из библиотеки MLxtend
Ход лабораторной работы
Создадим Python скрипт и загрузим данные в датафрейм.

Рисунок 1 – Загрузка данных в датафрейм
Переформируем данные удалив все значения NaN

Рисунок 2 – Удаление значений из NaN
Получим список всех уникальных товаров

Рисунок 2 – Получение уникальных товаров
Выведем список всех товаров, а также их количество

Рисунок 3 – Полученный результат
Преобразуем данные к виду, удобному для анализа

Рисунок 4 - Код
Проведем ассоциативный анализ используя алгоритм FPGrowth при уровне поддержки 0.03

Рисунок 5 – Полученный результат
Определим минимальное и максимальное значения для уровня поддержки для набора из 1,2, и.т.д. объектов.

Рисунок 6 – Код

Рисунок 7 – Полученный результат
Проведём аналогичный анализ используя алгоритм FPMax.

Рисунок 8 – Полученный результат

Рисунок 9 – Код

Рисунок 10 – Полученный результат
Сравним полученные результаты для FPGrowth и FPMax. Разница между FPMax и FPGrowth заключается в том, что алгоритм FPMax выводит только "максимальные" наборы! Максимальный набор - это набор, который является частым, то есть имеет уровень поддержки больше, чем минимальная граница, и при этом не является поднабором для другого частого набора.
Построим гистограмму для каждого товара. Столбцы на гистограмме упорядочены по уменьшению частоты. Отобразим результат только для 10 самых встречаемых товаров.

Рисунок 11 – Полученный результат
Наиболее часто встречающихся элементы на данной гистограмме имеют наиболее высокий уровень поддержки в наборе из одного элемента.
Преобразуем набор данных, чтобы он содержал ограниченный набор товаров

Рисунок 12 – Код
Проведём анализ FPGrowth и FPMax для нового набора данных.

Рисунок 13 – Код

Рисунок 14 – Полученный результат

Рисунок 15 – Полученный результат
Сформируем набор данных из определенных товаров и так, чтобы размер транзакции был 2 и более

Рисунок 16 – Код
Получим частоты наборов используя алгоритм FPGrowth

Рисунок 17 – Полученный результат
Проведем ассоциативный анализ

Рисунок 18 – Полученный результат
Проведём построение ассоциативных правил для различных метрик. Рассчитаем среднее значение, медиану и СКО для каждой из метрик.

Рисунок 19 – Полученный результат

Рисунок 20 – Полученный результат

Рисунок 21 – Полученный результат
Построим граф для следующего анализа:

Рисунок 22 – Полученный результат

Рисунок 23 – Код
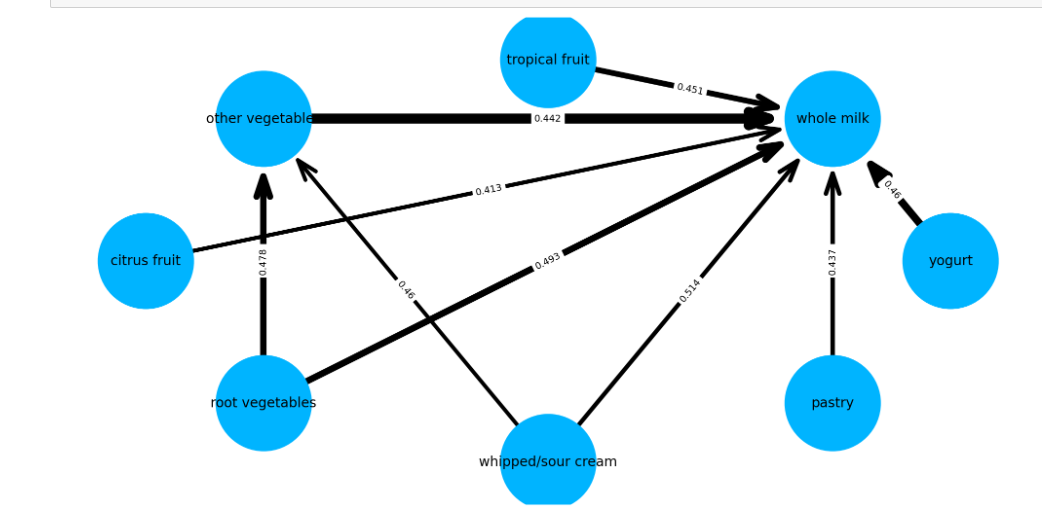
Рисунок 24 – Полученный граф
Вывод
Ознакомился с методами ассоциативного анализа из библиотеки MLxtend