

7675
.pdfб) комплексы моделей производства и потребления;
в) комплексы моделей формирования и распределения доходов;
г) комплексы моделей трудовых ресурсов;
д) комплексы моделей ценообразования;
е) комплексы моделей финансовых связей и др.
3) классификация эконометрических моделей на дескриптивные и нормативные модели:
а) дескриптивные модели предназначены для объяснения наблюдаемых фактов или для построения вероятностного прогноза. В
качестве примера дескриптивной модели можно привести производственные функции и функции покупательного спроса,
построенные на основе обработки статистических данных;
б) нормативные модели отвечают на вопрос «как это должно бытьβ»,
т. е. предполагают целенаправленную деятельность. В качестве примера нормативной модели можно привести модели оптимального планирования,
характеризующие тем или иным образом цели экономического развития,
возможности и средства их достижения; 4) классификация эконометрических моделей по характеру отражения
причинно-следственных связей. При этом выделяют:
а) модели жестко детерминистские;
б) модели, в которых учитываются факторы случайности и неопределенности.
Вследствие перехода от жёстко детерминированных моделей к моделям второго типа, были разработаны реальные возможности успешного применения более совершенной методологии моделирования экономических процессов, учитывающих факторы случайности и неопределённости, а именно:
а) проведение многовариантных расчетов и модельных экспериментов с вариацией конструкции модели и ее исходных данных;
б) изучение устойчивости и надежности получаемых решений;
в) выделение зоны неопределенности;
г) включение в модель резервов;
д) применение приемов, повышающих приспособляемость
(адаптивность) экономических решений к вероятным и непредвиденным ситуациям
В последнее время широко применяются эконометрические модели,
непосредственно отражающие стохастичность и неопределенность экономических процессов. Данные модели используют соответствующий математический аппарат: теорию вероятностей и математическую статистику, теорию игр и статистических решений, теорию массового обслуживания, теорию случайных процессов.
5) Классификация эконометрических моделей по способам отражения фактора времени. При этом выделяют:
а) статические модели, характеризующие исследуемую зависимость между переменными на определённый момент времени;
б) динамические модели, характеризующие изменение экономических процессов во времени.
Общая постановка задачи в эконометрике. Виды переменных.
Описание эконометрической модели.
Эконометрическая модель – вероятностно-статистическая модель,
описывающая механизм функционирования экономической или социально-экономической системы.
Можно выделить три класса эконометрических моделей:
1) Регрессионная модель с одним уравнением- yi=f(x1i, x2i ,…., xmi), где m -число независимых переменных, i - номер наблюдения.
В таких моделях результативный признак -y (зависимая переменная)
представляется в виде функции факторных признаков - x1, x2 ,…, xm (независимых переменных).
Примеры регрессионных моделей с одним уравнением:
Функция цены: P=f(Q, Pk), где цена определенного товара - P зависит
от объема его поставки – Q и от цен конкурирующих товаров -Pk.
Функция спроса: Qd=f(P, Pk,I), где величина спроса на определенный товар –Qd зависит, от цены данного товара - P, от цен товаров-конкурентов - Pk, а также от реальных доходов потребителей
- I.
Производственная функция: Q=f(L,K), представляющая собой зависимость объема производства определенного товара (Q) от производственных факторов, например, от затрат капитала (K) и
затрат труда (L).
2) Системы одновременных уравнений.
Эти модели описываются системами взаимосвязанных регрессионных уравнений. Система «объясняет», а также прогнозирует столько результативных признаков, сколько уравнений входит в систему.
Уравнения системы могут быть либо тождествами, либо поведенческими уравнениями. Для тождеств характерно, что их вид и значения параметров известны.
3) Модели временных данных (в которых результативный признак является функцией переменной времени (в качестве фактора выступает время) или переменных, относящихся к другим моментам времени).
К моделям временных данных, представляющих собой зависимость результативного признака от времени, относятся модели:
-тренда (зависимости результативного признака от трендовой компоненты);
-сезонности (зависимости результативного признака от сезонной компоненты);
-тренда и сезонности.
К моделям временных данных, представляющих собой зависимость результативного признака от переменных, датированных другими моментами времени, относятся модели:
- модели, объясняющие поведение результативного признака в зависимости от предыдущих значений факторных переменных – yt=f(xt-1) -
модели с распределенным лагом (например, зависимость инвестиций в
экономику от доходов, полученных в предыдущий период времени);
-модели, объясняющие поведение результативного признака в зависимости от предыдущих значений результативных переменных - yt=f(yt-1) - модели авторегрессии (например, зависимость расходов на товар длительного пользования от этих же расходов в предыдущий период времени);
-модели, объясняющие поведение результативного признака в зависимости от будущих значений факторных или результативных переменных yt=f(xt+1) - модели ожиданий. Например, зависимость спроса на товар длительного пользования от ожидаемого курса доллара (евро).
Модели временных данных подразделяют также на модели,
построенные по стационарным и нестационарным временным рядам.
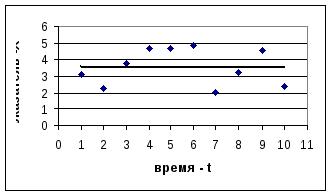
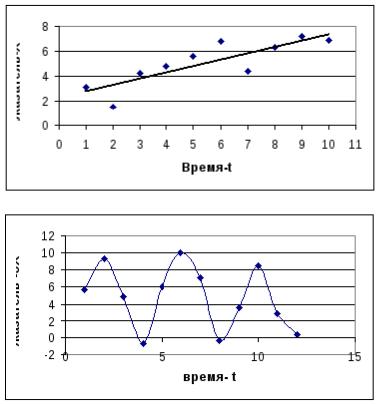
Стационарные временные ряды – ряды, имеющие постоянное среднее значение и колеблющиеся вокруг него с постоянной дисперсией
(определение стационарности в узком смысле) (рис. 1.а). В таких рядах распределение показателя - уровня ряда не зависит от времени, т.е.
стационарный временной ряд не содержит трендовой или сезонной компонент. В нестационарных временных рядах распределение уровня ряда зависит от переменной времени (рис. 1.б., 1.в).
а)
б)
в)
Проблема идентификации эконометрических моделей.
При переходе от приведенной формы модели к структурной исследователь сталкивается с проблемой идентификации.
Идентификация – единственность соответствия между структурной и приведенной формами модели.
Параметры структурной формы модели по оценкам приведенных коэффициентов можно определить не всегда. Для этого необходимо, чтобы модель была идентифицируемой.
С позиции идентифицируемости структурные модели можно подразделить на три вида:
Выделяют:
1) Точно идентифицируемая модель – все ее уравнения точно идентифицированы. То есть все структурные коэффициенты определяются однозначно (единственным способом) по коэффициентам приведенной формы модели. И число параметров структурной модели
равно числу параметров приведенной формы.
2)Неидентифицируемая модель – число приведенных коэффициентов меньше числа структурных коэффициентов. Оценки всех структурных параметров невозможно найти по коэффициентам приведенной модели.
3)Сверхидентифицируемая модель – число приведенных коэффициентов больше числа структурных коэффициентов (на основе приведенной формы можно получить 2 и более значений одного структурного коэффициента). Практически решаема, но требует применения специальных методов.
На идентификацию проверяются все уравнения модели. Модель считается идентифицируемой, если все уравнения идентифицируемы; сверх
– если хоть одно сверхидентифицируемо, а остальные точно идентифицируемы. Если среди всех уравнений модели есть хотя бы одно неидентифицированное, то вся модель считается неидентифицированной.
Правила идентификации
Введем следующие обозначения:
М- число экзогенных (предопределенных) переменных в модели;
т- число экзогенных (предопределенных) переменных в данном уравнении;
К - число эндогенных переменных в модели;
k - число эндогенных переменных в данном уравнении.
А) Необходимое (но недостаточное) условие идентификации.
Для того чтобы уравнение модели было идентифицируемо,
необходимо, чтобы число предопределенных переменных, отсутствующих в данном уравнении, было не меньше «числа эндогенных переменных,
входящих в уравнение минус 1», т.е.:  ;
;
Если 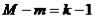 , уравнение точно идентифицировано.
, уравнение точно идентифицировано.
Если 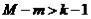 , уравнение сверхидентифицировано.
, уравнение сверхидентифицировано.
Либо D+1=H (H – число эндогенных переменных в уравнении; D –
число отсутствующих экзогенных переменных).

Эти правила следует применять к структурной форме модели.
Достаточное условие идентификации. Введем обозначения: А
- матрица коэффициентов при переменных не входящих в данное уравнение.
Достаточное условие идентификации заключается в том, что
-определитель матрицы А должен быть не равен нулю,
-ранг матрицы А должен быть не меньше, чем число эндогенных
переменных в системе без одного 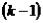 .
.
Ранг матрицы - размер наибольшей ее квадратной подматрицы,
определитель которой не равен нулю. Пример:
a |
b |
c d |
тогда ранг R=2. |
Сформулируем необходимое и достаточное условия идентификации:
1) Если 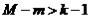 и ранг матрицы А
и ранг матрицы А 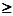 равен
равен 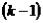 , то уравнение
, то уравнение
сверхидентифицировано.
2)Если 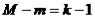 и ранг матрицы А
и ранг матрицы А 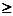
 , то уравнение точно идентифицировано.
, то уравнение точно идентифицировано.
3)Если 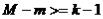 и ранг матрицы А <
и ранг матрицы А < 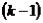 то уравнение неидентифицированно.
то уравнение неидентифицированно.
4)Если 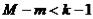 , то уравнение неидентифицированно. В этом
, то уравнение неидентифицированно. В этом
случае ранг матрицы А будет меньше |
. |
|
|
|
||
Оценка точно идентифицированного уравнения осуществляется с |
||||||
помощью косвенного метода наименьших квадратов (КМНК). |
|
|||||
Алгоритм КМНК включает 3 шага: |
|
|
|
|
||
1) |
составление |
приведенной |
формы |
модели |
и |
|
выражение каждого коэффициента приведенной формы через структурные параметры;
2)применение обычного МНК к каждому уравнению приведенной формы и получение численных оценок приведенных параметров;
3)определение оценок параметров структурной формы по оценкам
приведенных коэффициентов, используя соотношения, найденные на шаге
1.
Оценка сверхидентифицированного уравнения осуществляется при помощи двухшагового метода наименьших квадратов.
Алгоритм двухшагового МНК включает следующие шаги:
1)составление приведенной формы модели;
2)применение обычного МНК к каждому уравнению приведенной формы и получение численных оценок приведенных параметров;
3)определение расчетных значений эндогенных переменных,
которые фигурируют в качестве факторов в структурной форме модели; 4) определение структурных параметров каждого уравнения в
отдельности обычным МНК, используя в качестве факторов входящие в это уравнение предопределенные переменные и расчетные значения эндогенных переменных, полученные на шаге 1 .
Понятие комплексных систем прогнозирования. Метод прогнозного графа. Математические модели оптимизации и прогнозирования микроэкономики.
Практическое использование такие системы находят на высших уровнях управления крупных экономических систем: страны, отрасли, ре-
гиона, холдинга, транснациональной компании и т.п.
Необходимость в создании комплексных систем возникает в связи со сложностью современных организационно-производственных систем и не-
возможностью их единообразного описания и прогнозирования С исполь-
зованием только одного метода.
Разработку комплексных систем прогнозирования ведут исходя из структуры прогнозируемого объекта или процесса.
При разработке и анализе комплексных систем прогнозирования к основным операциям относят определение состава и процедур сингулярных
(простых) методов прогнозирования, входящих в систему, а также ло-
гические правила их объединения в систему. Простые процедуры исполь-
зуют для прогнозирования подсистем и блоков, входящих в структуру про-
гнозируемого процесса или объекта.
Примерами использования комплексных систем прогнозирования являются: метод прогнозного графа, система ПАТТЕРН и др.
Метод прогнозного графа.
Разработан группой киевских специалистов института кибернетики под руководством академика В.М.Глушкова. Основой метода являются экспертные и формально-математические процедуры построения и анализа опорного графа, отражающего обобщенное суждение широкого круга специалистов о потребностях, возможных путях и ресурсах, необходимых для достижения поставленной цели.
Комплексная система, построенная в соответствии с этим методом,
реализует следующие процедуры: выбор объектов прогноза; исследование фона (среды); классификация событий; формирование задач и генеральной цели прогноза; анализ иерархии; формирование событий; принятие внут-
ренней и внешней структуры объекта прогноза; анкетирование экспертов,
математическая обработка данных анкетного опроса; количественная оценка структуры; верификация полученных результатов.
Опорный граф строится сверху от события, являющегося конечной целью, до самого нижнего уровня, содержащего события, свершение кото-
рых обеспечивают уже имеющиеся научно-технические достижения. Такие события можно считать реализованными («заземленными»).
На каждом уровне группа экспертов формулирует события-цели и условия их достижения. Обработка информации на ЭВМ позволяет опре-
делить важность различных событий для свершения конечной цели, найти оптимальные пути и оценить по разным критериям варианты решений.
Программа работы ЭВМ обеспечивает также перестройку графа, его упорядочение, в том числе и ликвидацию тупиков и петель, то есть возврата к уже совершенным событиям, а также перераспределение и обновление информации.
Достоинством метода является возможность работы с графом в ре-
жиме диалога «человек - информационная система» для проверки некото-
рых ситуаций, то есть возможность проигрывать разные ситуации.
Граф является динамической системой, и при поступлении от экс-
пертов новой информации производится пере смотр-ревизия оценок, вари-
антов прогноза и принятых решений.
В результате этой ревизии ЭВМ может сформулировать запросы к принимающим решение о целесообразности пересмотра тех или иных дей-
ствий или обсуждения экспертами и принимающими решение вновь сло-
жившейся ситуации. Такие способности прогнозного графа к совершенст-
вованию и «самоанализу» открывают возможности новой методологии планирования и управления.
Круг организаций, использующих систему, построенную по типу прогнозного графа, достаточно широк и включает официальные инстанции и органы управления, а также генеральных и главных инструкторов и дру-
гих специалистов, ответственных за НИОКР и их разделов.
Система ПАТТЕРН Разработана в США в 1964 г. для обоснования планирования и
управления научными исследованиями и опытно-конструкторскими разра-
ботками. Используется для обоснования прогнозов и планов посредством научно-технической оценки количественных данных.
Метод как элемент включает построение сценария (динамической картины будущего). Выявленная в сценарии главная цель детализируется на отдельные подцели, каждая из которых разделяется на более частные задачи
(производится декомпозиция цели) и т.д.
«Дерево целей» содержит только те проблемы, которые требуют на-
учно-технической разработки, остальные исключаются из рассмотрения.
Для каждого уровня дерева целей устанавливаются коэффициенты относительной важности всех его элементов, выраженные в долях единицы.
Важное значение имеет определение состояния и возможных сроков завершения работ, характеризуемых коэффициентами состояния разработ-