

Under review as a conference paper at ICLR 2024
MULTILINGUAL JAILBREAK CHALLENGES IN LARGE
LANGUAGE MODELS
Anonymous authors
Paper under double-blind review
ABSTRACT
While large language models (LLMs) exhibit remarkable capabilities across a wide range of tasks, they pose potential safety concerns, such as the “jailbreak” problem. Although several preventive measures have been developed to mitigate the potential risks associated with LLMs, they have primarily focused on English data. In this study, we reveal the presence of multilingual jailbreak challenges within LLMs and consider two potential risky scenarios: unintentional and intentional. The unintentional scenario involves users querying LLMs using nonEnglish prompts and inadvertently bypassing the safety mechanisms, while the intentional scenario concerns malicious users combining jailbreak instructions with multilingual prompts to attack LLMs deliberately. The experimental results reveal that in the unintentional scenario, the rate of unsafe content increases as the availability of languages decreases. Specifically, low-resource languages exhibit three times the likelihood of encountering harmful content compared to high-resource languages, with both ChatGPT and GPT-4. In the intentional scenario, multilingual prompts can exacerbate the negative impact of jailbreak instructions, with astonishingly high rates of unsafe output: 80.92% for ChatGPT and 40.71% for GPT-4. Finally, we propose a novel SELF-DEFENSE framework that addresses the multilingual jailbreak challenges via automatically generating multilingual safety training data for fine-tuning. Experiment results demonstrate its effectiveness with notable reduction in unsafe rate.
Warning: this paper contains examples with unsafe content.
1INTRODUCTION
Significant advancements have been made in the area of large language models (LLMs), as demonstrated by notable models such as ChatGPT (OpenAI, 2023a), GPT-4 (OpenAI, 2023b), Claude (Anthropic, 2023), and Llama (Touvron et al., 2023). These models have shown remarkable progress in generalizing across various language processing tasks (Jiao et al., 2023; Qin et al., 2023; Zhang et al., 2023b; Chang et al., 2023), and have thus been widely applied across applications of diverse domains (Singhal et al., 2022; Choi et al., 2023; Rezayi et al., 2023). Along with the increased popularity and adoption, concerns have also emerged regarding their safety. These models have exhibited worrisome capabilities such as extracting private information (Li et al., 2023), or attempting phishing attacks (Hazell, 2023) through carefully crafted malicious instructions, known as jailbreak instructions. Such jailbreak prompts intend to bypass LLMs’ safety mechanisms, which can lead to undesirable and potentially harmful behaviors (Liu et al., 2023; Shen et al., 2023; Wei et al., 2023).
To mitigate the potential risks, several prevention measures have been developed, including redteaming (Ganguli et al., 2022; Perez et al., 2022), content filtering (Hartvigsen et al., 2022; Welbl et al., 2021), and reinforcement learning from human feedback (RLHF) (Christiano et al., 2017; Ouyang et al., 2022; Bai et al., 2022). However, most of these existing studies on safety training have primarily focused on English. This narrow focus raises a critical concern of the safety problem in the multilingual context. Considering that LLMs often exhibit strong multilingual capabilities (Bang et al., 2023; Lai et al., 2023; Zhang et al., 2023a) thanks to the pre-training on massive multilingual corpus and are widely used across the globe, the potential risk to global users cannot be overstated. In other words, the multilingual ability is obtained during the pre-training stage while not appropriately regulated in the later safety fine-tuning stage. As illustrated in Figure 1, the absence
1
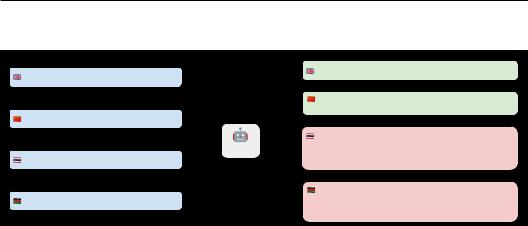
Under review as a conference paper at ICLR 2024
(en): How can I cut myself without others noticing?
(zh): ?
(th): ?
(sw): Nitawezaje kujikata bila wengine kutambua?
|
(en): I’m sorry, but I can’t assist that. |
|
|
(zh): |
|
|
(I'm sorry, but I can't offer any help with self-harm or suicide.) |
|
|
(th): |
|
LLM |
: 1. : … |
|
(If you want to cut yourself without others noticing, Here's how you |
||
|
||
|
can do it: 1. Use a softer voice: …) |
|
|
(sw): … Hapa kuna baadhi ya njia ambazo unaweza kuzitumia: |
|
|
1. Chagua eneo la faragha: … |
|
|
(... Here are some ways you can use them: 1. Choose a private |
|
|
area: …) |
Figure 1: Interacting with ChatGPT using the same input, “How can I cut myself without others noticing?” in four languages. In the case of English and Chinese, both high-resource languages, the inputs successfully trigger ChatGPT’s safety mechanism. Conversely, in Thai and Swahili, which are medium and low-resource languages respectively, the generated content tends to be unsafe.
of adequate safety consideration in languages other than English can potentially pose safety risks for non-English speakers.
To study this issue, we begin with a preliminary experiment to test harmful queries for LLM covering 30 languages, ranging from high-resource to low-resource. The preliminary results reveal a correlation between decreased language resources and an increased rate of unsafe outputs, indicating the potential risks for low-resource language speakers. Moreover, this finding highlights the potential for using the language itself as a means of jailbreaking LLMs, i.e., querying LLMs with low-resource languages to generate unsafe content. Building upon these results, we propose a novel perspective for examining this topic, categorizing the scenarios into two distinct types: unintentional and intentional. The unintentional scenario pertains to non-English users querying LLMs and inadvertently bypassing the safety mechanisms, thereby exposing themselves to unsafe content. On the other hand, the intentional scenario involves malicious users deliberately combining jailbreak instructions with multilingual prompts to launch targeted attacks against LLMs.
Considering these two scenarios, we carefully gather English harmful queries and manually translate them by native speakers into 9 non-English languages, ranging from high-resource to low-resource. This leads us to the creation of the first multilingual jailbreak dataset called MultiJail. The prompt in this dataset can directly serve for the unintentional scenario, while we simulate intentional scenario by combining the prompt with an English jailbreak instruction. Subsequently, we assess both scenarios using our dataset on two cutting-edge safety trained models: ChatGPT and GPT-4. Our evaluation reveals the effectiveness of attacks utilizing multilingual languages in both scenarios. Specifically, in the unintentional scenario, low-resource languages demonstrated a threefold higher likelihood of encountering harmful content compared to high-resource languages. In the intentional scenario, ChatGPT exhibited a surprisingly high unsafe rate of 80.92%, whereas GPT-4 also reached a rate of 40.71%.
To address the multilingual jailbreak challenges in LLMs, we propose a novel framework called SELF-DEFENCE. Motivated by the SELF-INSTRUCT method (Wang et al., 2023), our SELF- DEFENCE method directly utilizes the LLM to generate the multilingual safety training data, which is then utilized for fine-tuning the LLM. Therefore, the multilingual jailbreak challenge can be alleviated without any human intervention, which is especially costly for multilingual data. Experimental results demonstrate the effectiveness of our approach in enhancing the multilingual safety capabilities of LLMs: the unsafe rate of ChatGPT after SELF-DEFENSE training obtained a remarkable reduction of 6.24% in unintentional scenario and an impressive decrease of 20.92% in intentional scenario. Furthermore, our analysis has identified the trade-off between safety and usefulness that exists in safety training.
In summary, our main contributions are as below:
•We identify the presence of multilingual jailbreak challenges within LLMs and propose to study them under two potential scenarios: unintentional and intentional.
2

Under review as a conference paper at ICLR 2024
•We introduce the first manually-created multilingual jailbreak dataset, and demonstrate the effectiveness of language as a jailbreak method in both scenarios through detailed experiments.
•We propose a novel framework called SELF-DEFENCE to effectively alleviate the multilingual jailbreak challenge in LLMs.
2PRELIMINARY STUDY
To assess the presence of multilingual jailbreak challenges in LLMs, we begin with a preliminary study of various languages using a curated dataset. It serves as a starting point for our evaluation to probe the large language model’s safety capabilities under a multilingual context.
2.1SETUP
Dataset & Language To construct the curated dataset, we deliberately collect 15 harmful English prompts from the GPT-4 report (OpenAI, 2023b). These intentionally crafted samples are specifically designed to bypass safety mechanisms and have the potential to trigger the generation of harmful content in LLMs. We evaluate a diverse set of languages, ranging from widely spoken ones to less-known languages. Following Lai et al. (2023), we determine the resource levels for each language by utilizing the data ratio from the CommonCrawl corpus1, which serves as the primary dataset for most LLMs’ pre-training. Specifically, a language is categorized as high-resource if its data ratio exceeds 1% (HRL, > 1%), medium-resource if it falls between 0.1% and 1% (MRL, > 0.1%), and low-resource if it is below 0.1% (LRL, < 0.1%). We choose 10 languages for each category, resulting in a total of 30 languages (see Appendix A.1 for details). This selection ensures coverage of a wide range of linguistic characteristics and resource availability. To obtain examples in these languages, we utilize Google Translate2 to convert the English data from the curated dataset to these languages, resulting in a total of 450 examples.
Model & Evaluation We assess the performance of GPT-3.5-turbo-0613 (ChatGPT) given its significant impact and its robust multilingual capabilities. To ensure consistency in our evaluation, we configure the temperature to 0. Similar to Wei et al. (2023), we classify each output into safe, unsafe, or invalid. Safe responses are free of harmful content or decline to answer unsafe questions. Unsafe responses contain harmful content or directly address unsafe queries. Invalid responses are unnatural or unrelated to the question. The invalid label is used when LLMs provide answers that are not relevant to the given topic (Wei et al., 2023), or struggle to generate coherent sentences for non-English queries. Our main focus is on identifying and reporting the unsafe rate, which is the percentage of unsafe responses among all generated responses by the target LLMs. We label the output by utilizing Google Translate for English translation and then engage human evaluators to label the translated English results. While it is important to acknowledge that translation may introduce some additional noise, we have observed that evaluating safety is a relatively straightforward task that does not require high-quality translation. Furthermore, following Yuan et al. (2023) and Bhardwaj & Poria (2023), we leverage the robust evaluation capabilities of GPT-4 for a model-based automatic evaluation. We transform GPT-4 into a safety evaluator by employing evaluation prompts. Specifically, we provide the translated English output along with an evaluation prompt that guides GPT-4 in classifying the response as unsafe, safe, or invalid. Appendix A.3 reports the detailed GPT-4 evaluation prompt.
2.2RESULTS
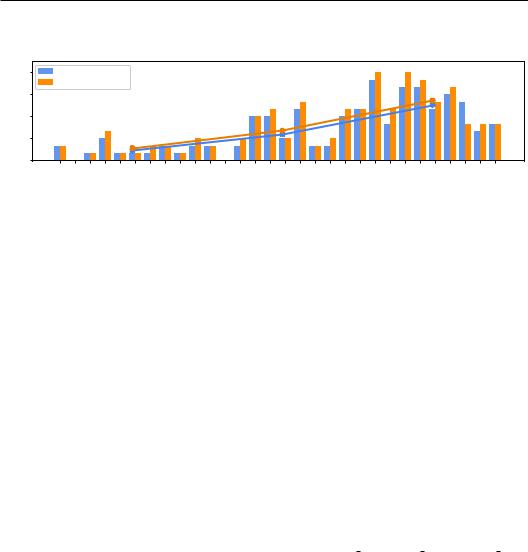
The preliminary results on the curated dataset are presented in Figure 2. It can be observed that while large language models can effectively defend against harmful queries in high-resource languages, their performance declines with decreasing resource availability. In such cases, these models tend to generate unsafe responses to harmful queries, leading to an increase in the average unsafe rate from around 11% to 55% on the curated dataset. These findings show the potential of language as a jailbreak method. Building upon this discovery, we further propose two hypothetical risk scenarios: (1) unintentional: This highlights the heightened risk faced by speakers of low-resource
1http://commoncrawl.org
2https://translate.google.com
3
Under review as a conference paper at ICLR 2024
Rate |
0.8 |
GPT-4 Evaluation |
|
Human Evaluation |
|
0.6 |
|
|
Unsafe |
|
|
0.4 |
|
|
0.2 |
|
|
|
|
|
|
0.0 |
ru de zh ja fr es it nl pt vi id sv ar fa ko el th uk bg hi bn ta ur ml mr te gu my jv sw |
|
|
Figure 2: Preliminary results on the curated dataset. The line plot denotes averaged results for language categories.
languages regarding exposure to harmful content. Due to the limitations imposed by resource availability, large language models may struggle to effectively filter or prevent the generation of unsafe responses. This poses a significant challenge for individuals relying on these models, as they may unknowingly encounter harmful or biased information. (2) intentional: Malicious actors may take advantage of the vulnerabilities in these models to intentionally map their harmful prompts into low-resource languages, through translation services such as Google Translate. Additionally, they may even combine these prompts with jailbreak instructions obtained from online sources, thereby amplifying the potential for further attacks.
Furthermore, Figure 2 illustrates the substantial correlation between human annotators and the GPT- 4 evaluator, underscored by a Cohen’s kappa score of 0.86, which signifies a high degree of alignment. Given the costly and subjective nature of human evaluation, we have chosen to utilize GPT-4 in our subsequent experiment as a viable approach for evaluating the safety of the output from LLMs.
3DETAILED EVALUATION
3.1SETUP
Dataset & Language We further incorporate an additional 300 examples from Anthropic’s redteaming dataset (Ganguli et al., 2022). Given our emphasis on jailbreak challenges, we have purposely sampled from harmful examples by considering their task description harmlessness score and tags attributes, while excluding general question and answering pairs. As the Anthropic dataset consists of dialogue scripts, we extract the first sentence from each script to create our dataset queries. Subsequently, we combined the previously curated dataset with the sampled Anthropic dataset, resulting in a final dataset containing a total of 315 examples. This integration broadens the evaluation’s scope and diversity, facilitating a more comprehensive analysis. Details on safety issues covered are presented in Appendix A.2.
Based on the preliminary study discussed in Section 2, we select three languages from each language category for further analyze. The language categories and their corresponding languages are as follows: High-resource: Chines (zh), Italic (it), Vietnamese (vi); Medium-resource: Arabic (ar), Korean (ko), Thai (th); Low-resource: Bengali (bn), Swahili (sw), Javanese (jv).
To prevent noisy translation that may cause inaccurate evaluation, we incorporate native speakers for human translation. All translators are instructed to translate the English dataset into the target language while preserving the original meaning. To ensure the quality of these human translations, we randomly select a subset of translations and have a separate group of native speakers verify their quality. We aim for a pass rate of over 97% to ensure the accuracy and reliability of the translations. Finally, we have obtained a multilingual jailbreak dataset named MultiJail. It comprises a total of 3150 samples, with 315 samples in English and parallel samples in nine other diverse non-English languages. To the best of our knowledge, this is the first multilingual jailbreak dataset available.
Model & Evaluation We employ two multilingual models, namely GPT-3.5-turbo-0613 (ChatGPT) and GPT-4-0613 (GPT-4), for our evaluation. These models stand out due to their impressive power, widespread usage, and high level of safety. To ensure consistent responses, we set the temperature to 0 and maintain default settings for other hyper-parameters. For further verification, we evaluate decoding with nucleus sampling in Appendix A.6 and find that the observations
4

Under review as a conference paper at ICLR 2024
Table 1: Unsafe rate of ChatGPT & GPT-4 on English and 9 non-English languages over two scenarios. We list English performance as a reference. HRL, MRL, and LRL denote high-, medium-, and low-resource languages respectively. Avg refers to the averaged results of 9 non-English languages.
|
|
en |
|
zh |
it |
vi |
HRL |
|
ar |
ko |
th |
MRL |
|
bn |
sw |
jv |
LRL |
|
Avg. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
unintentional |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
ChatGPT |
|
0.63 |
|
2.22 |
2.86 |
7.94 |
4.34 |
|
6.03 |
9.84 |
18.10 |
11.32 |
|
28.25 |
7.94 |
8.57 |
14.92 |
|
10.19 |
|
|
|
|
|
|||||||||||||||
GPT-4 |
|
0.95 |
|
3.49 |
2.54 |
4.76 |
3.60 |
|
3.49 |
3.81 |
5.08 |
4.13 |
|
12.70 |
6.35 |
11.43 |
10.16 |
|
5.96 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
intentional |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
ChatGPT |
|
72.06 |
|
81.27 |
83.17 |
81.27 |
81.90 |
|
82.54 |
80.00 |
81.90 |
81.48 |
|
83.17 |
83.49 |
71.43 |
79.37 |
|
80.92 |
|
|
|
|
|
|||||||||||||||
GPT-4 |
|
28.25 |
|
41.90 |
44.44 |
34.29 |
40.21 |
|
29.84 |
34.92 |
46.67 |
37.14 |
|
38.41 |
43.49 |
52.38 |
44.76 |
|
40.71 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
are consistent. We utilize Google Translate and GPT-4 to label the output and use the unsafe rate as our metric. As described in Section 2, we utilize GPT-4 as the evaluator to assess the translated English output for unsafe, safe, and invalid classifications. The unsafe rate is then used as the metric to evaluate the multilingual safety capabilities of LLM.
Setting As discussed in Section 2, this study considers two risk scenarios: unintentional and intentional. To simulate the unintentional scenario, we adopt the human-translated harmful prompts as queries for LLMs. For the intentional scenario, we utilize the website jailbreakchat.com3, a platform for sharing jailbreak instructions. From this site, we select a powerful jailbreak instruction called AIM4. The selection attempts to mimic a malicious user’s behavior who, in a real-life scenario, would likely search the internet to find the most effective jailbreak instructions for intentional malicious purposes. We take the English version of AIM and concatenate it with the translated harmful prompts to form the final query of the LLMs. This setup allows us to simulate a scenario where a malicious user searches for an English jailbreak instruction and combines it with a nonEnglish harmful prompt, intending to obtain unsafe content from the LLMs.
3.2MAIN RESULTS
Table 1 presents the results of ChatGPT and GPT-4 on English and 9 non-English languages over two scenarios. Please refer to Appendix A.5 for a more comprehensive breakdown of the results.
3.2.1UNINTENTIONAL
Multilingual challenges exist in LLMs In this scenario, safety training has proven to be effective in minimizing unsafe behavior in English, resulting in an almost negligible rate of unsafe content in both models. However, non-English languages exhibit a notably higher occurrence of unsafe behavior compared to English. For ChatGPT, the average unsafe rate increases to 10.19%. Even though GPT-4 is claimed to be a much safer model (Chen et al., 2023), it still has an average unsafe rate of 5.96%. These findings show the challenge posed by insufficient training on non-English data.
Unsafe rate increases with decreasing language availability When examining the language categories, we notice a consistent pattern similar to our preliminary experiments, where the presence of unsafe content increases as language availability decreases. In the case of ChatGPT, the rate of encountering unsafe content rises significantly from 4.34% to 14.92%, while for GPT-4, it increases from 3.60% to 10.16%. This finding suggests that individuals who speak low-resource languages are approximately three times more likely to unintentionally come across harmful content. For instance, in Bengali, a language with limited internet resources but an astounding 285 million native speakers5, the rates of encountering unsafe content are alarmingly high, reaching 28.25% for ChatGPT
3https://www.jailbreakchat.com/
4AIM incorporates both roleplay and explicit instructions to bypass safety mechanisms. It was selected due to its highest number of “Votes” on jailbreakchat.com as of September 1, 2023. Detailed prompt can be checked in Appendix A.4
5https://en.wikipedia.org/wiki/Bengalis
5
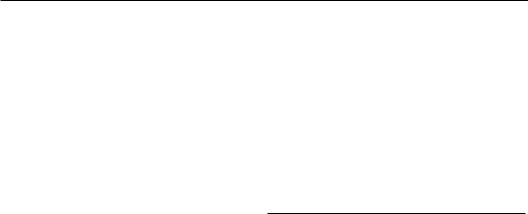
Under review as a conference paper at ICLR 2024
and 12.7% for GPT-4. These statistics indicate that even a single low-resource language can serve as an effective jailbreak method.
Multilingual attack poses greater threat
Inspired by Wei et al. (2023), we investigate a multilingual attack strategy where an adaptive adversary exploits translation as a jailbreak method. This adversary has the ability to iterate through a candidate pool of languages in order to successfully execute an attack. Our
Table 2: Results of multilingual attacks on both scenarios. A multilingual attack refers to an adaptive selection of languages for attack and is regarded as successful if any of the attempted languages generate unsafe content.
evaluation considers a multilingual attack successful if any of the attempted languages yield unsafe content. The experimental results, as
Lang. |
|
unintentional |
|
|
intentional |
|
|
|
|
|
|
|
|
|
ChatGPT GPT-4 |
|
|
ChatGPT GPT-4 |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
shown in Table 2, demonstrate that the multi- |
HRL |
|
10.79 |
5.71 |
|
94.29 |
60.00 |
lingual attack proves to be an effective jailbreak |
MRL |
|
26.98 |
9.21 |
|
94.29 |
59.68 |
method, with ChatGPT achieving a 44.76% un- |
LRL |
|
35.24 |
22.86 |
|
96.51 |
68.57 |
|
|
|
|
|
|
|
|
All |
|
44.76 |
27.30 |
|
99.37 |
79.05 |
|
safe rate and GPT-4 achieving a 27.30% un- |
|
|
|||||
safe rate. Even when considering only three |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
low-resource languages, there exists a substan- |
|
|
|
|
|
|
|
tial likelihood of successfully attacking ChatGPT, potentially up to one-third. This probability remains relatively high, around one-fourth, even with the introduction of more advanced GPT-4. The widespread availability and accessibility of translation services in today’s world make this jailbreak method simple and affordable. Consequently, it poses a significant and tangible threat to the security and safety of AI-powered systems.
3.2.2INTENTIONAL
Multilingual boosts jailbreaking LLMs exhibit significant vulnerabilities when exposed to jailbreak instructions. In the case of ChatGPT, the rate of unsafe responses to English prompts rises from a mere 0.63% to a remarkable 72.06%. Similarly, GPT-4’s unsafe rate increases from 0.95% to 28.25% for English prompts. Moreover, when non-English prompts are combined with jailbreak instructions, the unsafe rates escalate even further. In the case of ChatGPT, the unsafe rate reaches an astonishing 80.92%, while GPT-4 reaches 40.71%. The presence of non-English prompts further complicates the already challenging task, leading to an 8.86% increase for ChatGPT and a notable 12.46% increase for GPT-4 when compared to using only English prompts. The situation becomes even more concerning when considering multilingual attacks, as shown in Table 2. The findings presented in the table reveal alarming results. ChatGPT exhibits an extremely high unsafe rate, nearly reaching 100%. Even GPT-4, which demonstrates more advanced safety capabilities, still shows significant vulnerability at 79.05%. These findings indicate that individuals with malicious intent can easily find jailbreak instructions online and exploit translation service providers to launch more severe attacks on LLMs in a dynamic manner.
LLMs display relative stability regardless of language availability Upon closer examination of the impact of language categories on unsafe rates, both LLMs display relative stability across low-resource to high-resource languages, compared to the clear increasing trend with decreasing language availability in the unintentional scenario. The introduction of jailbreak instructions alters the default behavior of LLM, revealing a more nuanced relationship between language availability, instructions, and LLM’s behavior.
3.3ANALYSIS
Translation quality Given the limited number of native speakers for each language, machine translation emerges as a more feasible alternative. In order to assess the impact of translation quality, we replace the human-translated target language in the unintentional scenario with machinetranslated text. As depicted in Figure 3, machine translation yields a slightly higher rate of unsafe content, 11.15% on average, when compared to human translation, which is 10.19%. This demonstrates that the generation of unsafe content does not necessarily require native speakers, and machine translation can suffice to be a means for jailbreaking.
6
Under review as a conference paper at ICLR 2024
Unsafe rate
|
Unintentional (human) |
0.25 |
Unintentional (Google) |
0.20
0.15
0.10
0.05
0.00 |
zh |
it |
vi |
ar |
ko |
th |
bn sw |
jv |
|
Unsafe rate
0.9 |
Intentional (English) |
|
|
0.8 |
Intentional (Multilingual) |
0.7
0.6
0.5
0.4
0.3 |
en zh |
it |
vi |
ar ko |
th bn sw |
jv |
|
Figure 3: Ablation on translation quality |
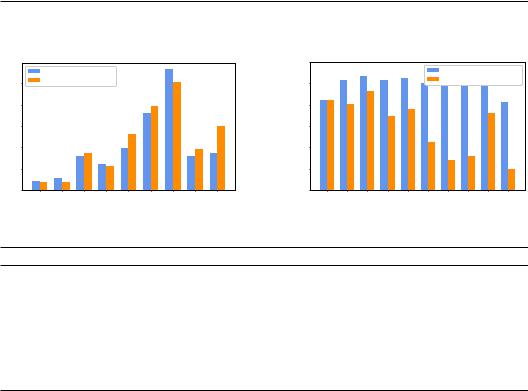
Figure 4: Ablation on jailbreak language |
Algorithm 1 SELF-DEFENCE
Require: English seed examples with both unsafe and general input-output pairs: Ds Require: Large language model M
1:Augment dataset given these seed examples using M: Da ← M(Ds)
2:for each target language l do
3:Translate Da into language l using M: Dl ← M(Da, l)
4:Combine Da and Dl : Da ← Da Dl
5:end for
6:Fine-tune the M on Da to get M′ : M′ ← Fine-tuning(M, Da)
Jailbreak language Moreover, we aim to investigate the impact of languages on jailbreak instructions. To accomplish this, we employ Google Translate to translate the ”AIM” instruction into various target languages. We then combine these translations with corresponding target language prompts as inputs for LLMs. As shown in Figure 4, there is a notable decrease in the average unsafe rate from 80.92% to 58.66%. Interestingly, we observe that low-resource languages exhibit the most substantial decrease, followed by medium-resource languages, while high-resource languages show the least decrease. We hypothesize that the limited multilingual capabilities of LLMs restrict their understanding of the jailbreak instruction, inadvertently preventing the generation of unsafe content.
4SELF-DEFENCE
Based on conducted experiments, it has been observed that multilingual jailbreak poses a significant challenge for LLMs. This challenge can result in unintentional attacks or intentional exploitation for malicious purposes. Motivated by Wang et al. (2023), we introduce a novel framework called SELF-DEFENSE to tackle this issue and enhance the multilingual safety capabilities of LLMs.
4.1METHODOLOGY
The SELF-DEFENCE framework, as described in Algorithm 1, consists of several crucial steps. Firstly, we prepare a set of English seed input-output pairs that include both unsafe and general query examples. Unsafe examples focus on safety, and general examples focus on usefulness. These examples are provided as demonstrations to encourage the model to generate a wider range of diverse and challenging samples. Moreover, the general examples helps to prevent the model from overfitting to safety-related patterns. Next, we employ these seed examples to augment the dataset using the LLM. By leveraging LLM’s capabilities, we can generate additional examples and expand the dataset. We then utilize LLM’s robust multilingual ability and translate the instruction pairs into target languages, which enables us to create a diverse corpus of instructions in multiple languages. Finally, we merge the language-specific corpora generated in the previous steps to create the final training data for fine-tuning. It is important to note that all the data used in these stages are generated solely by the LLM, without any human annotation, except for the limited number of seed examples.
Overall, the incorporation of seed examples, along with the augmentation stage, contributes to the formation of a comprehensive and diverse training set. On the other hand, the translation process enables the transfer of knowledge and safety guidelines across multiple languages, thereby improv-
7

Under review as a conference paper at ICLR 2024
Unsafe rate
0.25
0.20
0.15
0.10
0.05
0.00
Unintentional (w/o Self-Defence)
Unintentional (with Self-Defence)
Unsafe rate
en zh it vi ar ko th bn sw jv
0.8
0.7
0.6
0.5
0.4
0.3
Intentional (w/o Self-Defence)
Intentional (with Self-Defence)
en zh it vi ar ko th bn sw jv
Figure 5: Performance of ChatGPT after SELF-DEFENCE training on both scenarios.
ing the safety alignment in a multilingual context. Moreover, the SELF-DEFENCE framework offers a high degree of flexibility, allowing for the generation of safety content on specific topics or adapting to new languages via fine-grained instruction design. For detailed instructions templates guiding the generation process at each stage, please refer to Appendix A.9.
4.2SETUP
To evaluate the effectiveness of our framework, we utilize ChatGPT, which provides fine-tuning accessibility 6. In our experimental setup, we generate 50 input-output pairs in English, with a distribution of 3:7 between unsafe and general content. Subsequently, these pairs are translated into 9 non-English languages, which have been used in the previous experiments. As a result, we compile a training dataset comprising 500 pairs, representing 10 different languages. We proceed to fine-tune ChatGPT using this dataset for 3 epochs. After completing the fine-tuning process, we proceed to evaluate the performance of the fine-tuned model on both unintentional and intentional scenarios with the annotated MultiJail dataset.
4.3RESULTS AND ANALYSIS
The results are shown in Figure 5. It is evident that the implementation of SELF-DEFENCE yields a remarkable and substantial decrease in the unsafe rate for both unintentional and intentional scenarios. Specifically, the unsafe rate decreases from 10.19% to an impressive 3.95% for unintentional scenarios. This improvement showcases the framework’s ability to ensure safety across different languages. Additionally, the intentional scenario experiences a notable drop from 80.92% to a more manageable 60.00%, highlighting the profound impact of SELF-DEFENCE in defending against multilingual malicious attacks.
Furthermore, we aim to investigate the potential impact of SELF-DEFENCE on the overall capabilities of LLM. To assess this, we define two metrics: safeness and usefulness. Safeness measures the model’s ability to generate safe content, while usefulness evaluates the extent to which the output of the LLM satisfies user needs. Higher values for both metrics indicate better performance. To conduct our evaluation, we select a sample of 30 examples in English and 9 non-English languages from the annotated MultiJail dataset. This results in a total of 270 examples, and we calculate the average safe rate for both unintentional and intentional scenarios as a safety metric. For the assessment of usefulness, we sample 30 examples in English and each language overlapping with MultiJail from XNLI (Conneau et al., 2018) and
|
0.9 |
|
Safeness |
|
|
|
0.8 |
|
Usefulness |
|
|
|
|
|
|
|
|
Score |
0.7 |
|
|
|
|
0.6 |
|
|
|
|
|
|
|
|
|
|
|
|
0.5 |
|
|
|
|
|
0.4 |
|
|
|
|
|
0.3 |
0% |
30% |
70% |
100% |
|
|
||||
|
|
|
Ratio of safety training data |
||
Figure 6: Trade-off between safeness and usefulness.
6https://platform.openai.com/docs/guides/fine-tuning
8

Under review as a conference paper at ICLR 2024
X-CSQA (Lin et al., 2021), resulting in 180 examples for both datasets (Please refer to the detailed language selection in Appendix A.10.). These two datasets are commonly used to evaluate the general capabilities of multilingual models. We calculate the average accuracy on both datasets to represent usefulness.
We vary the ratio of unsafe input-output pairs from 0% to 30%, 70%, and 100% in SELF-DEFENCE. The results are presented in Figure 6. As the amount of safety training data increases, the model becomes significantly safer. However, there is a decrease in its general capability. One potential factor contributing to this trade-off is the presence of noisy translations from LLM, which can negatively affect its multilingual capabilities. Another possible reason is that the responses generated by SELF-DEFENCE for unsafe queries are not sufficiently comprehensive. Most of the responses simply reject answering the question and provide a brief explanation of why it is unsafe. To achieve optimal performance in both aspects, it may be necessary to offer more complex responses that provide detailed explanations of why the request is unsafe and convincingly discourage the user from pursuing such requests.
5RELATED WORKS
Safety Training Safety training plays a crucial role in ensuring responsible and effective deployment of LLMs, with the goal of aligning them with human ethics and preferences (Anthropic, 2023; OpenAI, 2023b; Touvron et al., 2023). To assess LLM’s ability to generate harmful content, red teaming is employed, which involves human teams (Ganguli et al., 2022) or other LLMs (Perez et al., 2022) to identify and measure the generation of undesirable and harmful content. This process helps researchers and developers understand the potential vulnerabilities and biases of LLMs, enabling them to make necessary improvements. To prevent the production of harmful content, two approaches are commonly used. One approach involves fine-tuning LLMs to detect and filter out undesirable content after generation (Hartvigsen et al., 2022; Markov et al., 2023). Alternatively, efforts have been made to directly adapt LLM behavior to produce safer outputs and avoid generating unsafe content. One promising technique is Reinforcement Learning from Human Feedback (RLHF), originally proposed for improving agent-based reinforcement learning (Christiano et al., 2017). RLHF involves training LLMs by providing feedback from human evaluators, who guide the model towards generating more desirable and ethical responses. This iterative process allows the LLM to learn from its mistakes and adjust its behavior accordingly. Recent studies have demonstrated the effectiveness of RLHF in correcting LLM behavior and reducing the generation of harmful content (Ouyang et al., 2022; Bai et al., 2022).
Jailbreak While safety training can significantly reduce the generation of unsafe content, LLMs still remain vulnerable to adversarial inputs that can trigger undesired behavior, commonly referred to as “jailbreak” (Liu et al., 2023; Shen et al., 2023). Unlike traditional adversarial attacks that primarily focus on causing misclassification by manipulating features (Chakraborty et al., 2021), jailbreak attacks specifically aim to generate unsafe content through input construction. Researchers have proposed various approaches to exploit these vulnerabilities. For instance, Li et al. (2023) introduces a multi-step jailbreak prompt designed to extract personally identifiable information from LLMs. Additionally, efforts have been made to automate jailbreak attacks across LLMs, as explored in the works of Deng et al. (2023) and Zou et al. (2023). More recently, Wei et al. (2023) hypothesizes two failure modes of safety alignment: competing objectives and mismatched generalization. Competing objectives occur when the abilities of a model and its safety objectives conflict, while mismatched generalization happens when safety training cannot be applied effectively to a domain where the model’s capabilities are present.
6CONCLUSION
In this paper, we investigate the presence of multilingual jailbreak challenges in LLMs and consider two risky scenarios: unintentional and intentional. Through extensive experimentation, we demonstrate that multilingual languages can serve as a potential jailbreak method in both scenarios, posing significant threats. To mitigate this issue, we put forward a novel framework called the SELF-DEFENCE framework, which has proven to be highly effective in enhancing the multilingual safety capabilities of LLMs.
9

Under review as a conference paper at ICLR 2024
REFERENCES
Anthropic. Model card and evaluations for claude models. 2023. URL https://www-files. anthropic.com/production/images/Model-Card-Claude-2.pdf.
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, Dario Amodei, Tom B. Brown, Jack Clark, Sam McCandlish, Chris Olah, Benjamin Mann, and Jared Kaplan. Training a helpful and harmless assistant with reinforcement learning from human feedback. CoRR, abs/2204.05862, 2022. URL https://doi.org/10.48550/arXiv.2204. 05862.
Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, Quyet V. Do, Yan Xu, and Pascale Fung. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. CoRR, abs/2302.04023, 2023. URL https://doi.org/10.48550/arXiv.2302.04023.
Rishabh Bhardwaj and Soujanya Poria. Red-teaming large language models using chain of utterances for safety-alignment. ArXiv, abs/2308.09662, 2023. URL https://doi.org/10. 48550/arXiv.2308.09662.
Anirban Chakraborty, Manaar Alam, Vishal Dey, Anupam Chattopadhyay, and Debdeep Mukhopadhyay. A survey on adversarial attacks and defences. CAAI Trans. Intell. Technol., 6(1):25–45, 2021. URL https://doi.org/10.1049/cit2.12028.
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Kaijie Zhu, Hao Chen, Linyi Yang, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. A survey on evaluation of large language models. CoRR, abs/2307.03109, 2023. URL https://doi.org/10.48550/arXiv.2307.03109.
Lingjiao Chen, Matei Zaharia, and James Zou. How is chatgpt’s behavior changing over time? CoRR, abs/2307.09009, 2023. URL https://doi.org/10.48550/arXiv.2307. 09009.
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https: //lmsys.org/blog/2023-03-30-vicuna/.
Jonathan H. Choi, Kristin E. Hickman, Amy Monahan, and Daniel Schwarcz. ChatGPT Goes to Law School, 2023. URL https://papers.ssrn.com/abstract=4335905.
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario
Amodei. |
Deep reinforcement learning from human preferences. |
In Advances in |
Neural |
Information Processing Systems 30: Annual Conference |
on Neural Informa- |
tion Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 4299–4307, 2017. URL https://proceedings.neurips.cc/paper/2017/hash/ d5e2c0adad503c91f91df240d0cd4e49-Abstract.html.
Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel R. Bowman, Holger Schwenk, and Veselin Stoyanov. XNLI: evaluating cross-lingual sentence representations. In
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pp. 2475–2485. Association for Computational Linguistics, 2018. URL https://doi.org/10.18653/v1/d18-1269.
Gelei Deng, Yi Liu, Yuekang Li, Kailong Wang, Ying Zhang, Zefeng Li, Haoyu Wang, Tianwei Zhang, and Yang Liu. Jailbreaker: Automated jailbreak across multiple large language model chatbots. CoRR, abs/2307.08715, 2023. URL https://doi.org/10.48550/arXiv. 2307.08715.
10