

БД_Лабораторная_работа_6_БСТ2104_Мажукин_И_Н
.docxМинистерство цифрового развития связи и массовых коммуникаций
Ордена Трудового Красного Знамени
Федеральное государственное бюджетное образовательное учреждение
высшего образования
«МОСКОВСКИЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
СВЯЗИ И ИНФОРМАТИКИ»
Кафедра «Математическая кибернетика и информационные технологии»
Отчёт по лабораторной работе №6
по дисциплине «Большие данные»
Выполнил: студент группы БСТ2104
Мажукин И.Н.
Проверил: Тимофеева А.И.
Москва, 2023 г.
Ход лабораторной работы:
На рисунке 1 представлены команды для импорта необходимых библиотек

Рисунок 1 – Команды для импорта библиотек
Пояснение команд:
from pyspark.sql import SparkSession: создаётся сессия Spark, которая является точкой входа для использования PySpark. SparkSession предоставляет API для создания DataFrame, который является основным объектом для работы с данными в PySpark.
from pyspark.ml import Pipeline: создаётся Pipeline (API в PySpark для построения и последовательного выполнения цепочки этапов обработки данных и обучения модели)
from pyspark.ml.feature import StringIndexer: создаётся StringIndexer, который используется для преобразования строковых данных в числовые.
from pyspark.ml.feature import VectorAssembler: создаётся VectorAssembler, который используется для объединения нескольких столбцов в один столбец вектора.
from pyspark.ml.evaluation import MulticlassClassificationEvaluator: создаётся MulticlassClassificationEvaluator, который предоставляет инструменты для оценки производительности модели
На рисунке 2 представлена команда для создания Spark сессии

Рисунок 2 – Команда для создания Spark сессии
На рисунке 3 представлено создание переменной spark, который присваивается объект SparkSession

Рисунок 3 – Создание переменной spark
На рисунках 4 и 5 представлены коды и выводы результатов заданий

Рисунок 4 – Код и вывод результата задания

Рисунок 5 – Код и вывод результата задания
На рисунке 6 представлена работа с категориальными признаками

Рисунок 6 – Код работы с категориальными признаками
На рисунке 7 представлено применение новых столбцов к датафрейму
![]()
Рисунок 7 – Применение новых столбцов к датафрейму
На рисунках 8 и 9 представлены коды и выводы результатов заданий

Рисунок 8 – Код и вывод результата задания
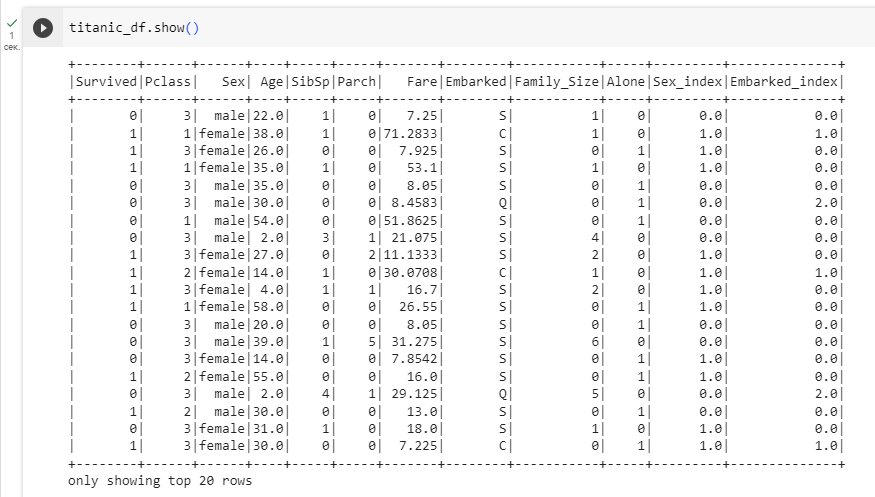
Рисунок 9 – Код и вывод результата задания
На рисунке 10 представлена команда для формирования списка признаков, которые будут использоваться в качестве фич

Рисунок 10 – Команда для формирования списка признаков
На рисунке 11 представлены команды для создания VectorAssembler и его применение для объединения нескольких столбцов (features) в один столбец-вектор, на рисунке 12 представлен результат выполнения
 Рисунок
11 – Команды для создания VectorAssembler и его
применение для объединения нескольких
столбцов (features) в один столбец-вектор
Рисунок
11 – Команды для создания VectorAssembler и его
применение для объединения нескольких
столбцов (features) в один столбец-вектор
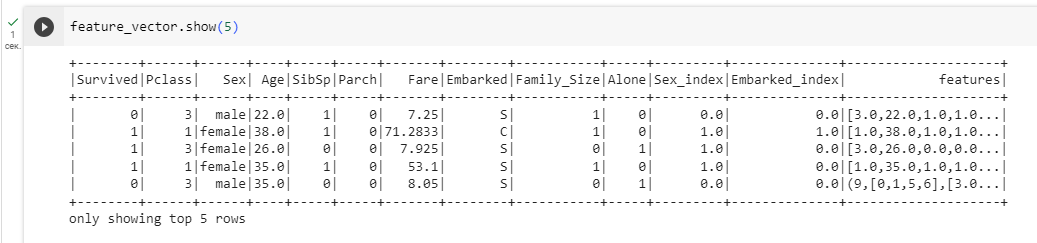
Рисунок 12 – Результат выполнения команд
На рисунке 13 представлена команда для формирования тренировочного и тестового датасета, на рисунке 14 представлен результат выполнения
![]()
Рисунок 13 – Формирование тренировочного и тестового датасета

Рисунок 14 – Результат выполнения команды
На рисунке 15 представлена команда для создания объекта evaluator с определёнными параметрами

Рисунок 15 – Команда для создания объекта evaluator с определёнными параметрами
На рисунке 16 представлен код, связанный с LogisticRegression (модель машинного обучения, которая пытается предсказать, выжил ли пассажир или нет на основе данных о том, кто выжил в обучающем наборе), использование модели для предсказания на тестовом наборе и вывод результата

Рисунок 16 – Код работы модели LogisticRegression, использование модели для предсказания на тестовом наборе и вывод результата
На рисунке 17 представлено вычисление точности модели LogisticRegression с использованием evaluator

Рисунок 17 – Вычисление точности модели LogisticRegression с использованием evaluator
На рисунке 18 представлен код, связанный с DecisionTreeClassifier (модель машинного обучения, способная выполнять мультиклассовую классификацию набора данных) и вывод результата

Рисунок 18 – Код работы модели DecisionTreeClassifier и вывод результата
На рисунке 19 представлено вычисление точности модели DecisionTreeClassifier с использованием evaluator

Рисунок 19 – Вычисление точности модели DecisionTreeClassifier с использованием evaluator
На рисунке 20 представлен код, связанный с RandomForestClassifier (модель машинного обучения, основанная на алгоритме RandomForest, основная идея которого заключается в построении нескольких решающих деревьев и объединении их прогнозов для получения более стабильного и точного результата), вывод результата и вычисление точности модели RandomForestClassifier с использованием evaluator

Рисунок 20 – Код работы модели RandomForestClassifier, вывод результата и вычисление точности с использованием evaluator
На рисунке 21 представлен код, связанный с Gradient-boosted tree classifier (модель машинного обучения, основная идея которой заключается в построении последовательности деревьев, где каждое новое дерево исправляет ошибки предыдущей композиции), вывод результата и вычисление точности модели Gradient-boosted tree classifier с использованием evaluator

Рисунок 21 – Код работы модели Gradient-boosted tree classifier, вывод результата и вычисление точности с использованием evaluator
На рисунке 22 представлено сохранение модели RandomForest и подключение нужного класса для её загрузки

Рисунок 22 – Сохранение и загрузка модели RandomForest
На рисунках 23-27 представлена работа с Pipeline (инструмент, позволяющий объединить последовательность этапов обработки данных и моделирования для эффективного и чистого выполнения многокомпонентных задач машинного обучения)

Рисунок 23 – Импортирование модуля PipelineModel, считывание данные из файла train.parquet и вывод результата

Рисунок 24 – Разбиение DataFrame titanic_df на тренировочный (80%) и тестовый (20%) наборы данных, вывод результата, преобразования двух столбцов в числовой формат, объединение столбцов в один вектор и создание Pipeline

Рисунок 25 – Получение обученной модели, проверка её типа, сохранение с перезаписью, загрузка, применение и вывод результата

Рисунок 26 – Получение обученной модели, проверка её типа, сохранение с перезаписью, загрузка, применение и вывод результата

Рисунок 27 – Код работы модели Pipeline для градиентного бустинга, вывод результата и вычисление точности с использованием evaluator