

Лабораторная работа 6
.docxМИНИСТЕРСТВО ЦИФРОВОГО РАЗВИТИЯ, СВЯЗИ И МАССОВЫХ КОММУНИКАЦИЙ РОССИЙСКОЙ ФЕДЕРАЦИИ
Ордена Трудового Красного Знамени федеральное государственное бюджетное образовательное учреждение высшего образования
«Московский технический университет связи и информатики»
Кафедра «Математическая кибернетика и информационные технологии»
Дисциплина «Большие данные»
Отчет по лабораторной работе 6
Выполнил:
студент группы БСТ2104
Станишевский И.А.
Проверила: Тимофеева А. И.
Москва, 2023 г.
Содержание
Цель работы 3
Ход выполнения 3
Цель работы 3
Ход выполнения 3
Цель работы
Получить навыки работы с Spark ML.
Ход выполнения
Установим библиотеку pyspark и подключим необходимые библиотеки.
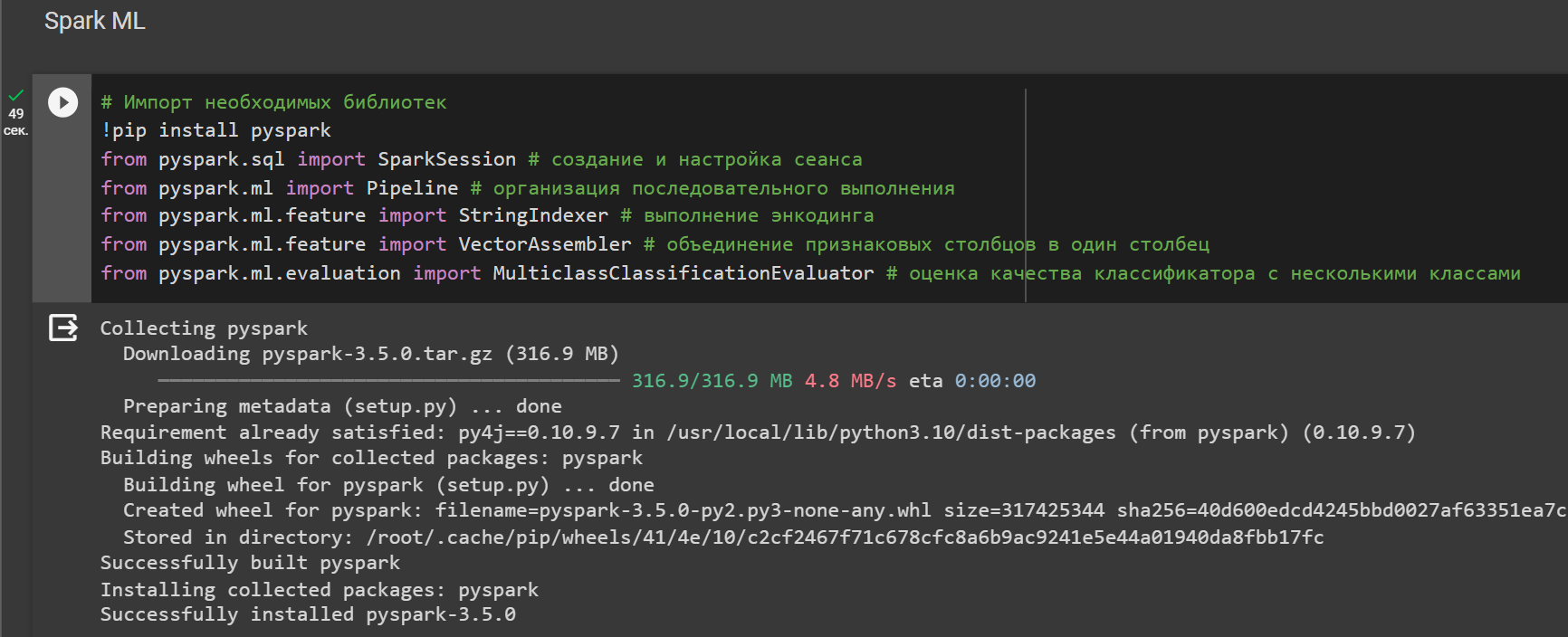
Рисунок 1 – Установка и импорт библиотек
Создаёт сессию Spark. Чтобы создать SparkSession, используем метод builder().
getOrCreate() возвращает уже существующий SparkSession; если он не существует, создается новый SparkSession.
appName() используется для установки имени приложения.

Рисунок 2 – Инициализацией среды выполнения Spark
Читаем входные данные, через spark.read.parquet().

Рисунок 3 – Вывод содержимого файла
Работа с функциями StringIndexer(), которая позволяет преобразовывать столбец с категориальными значениями

Рисунок 5 – Преобразование категориальных значений и применяем новые столбцы к датафрейму
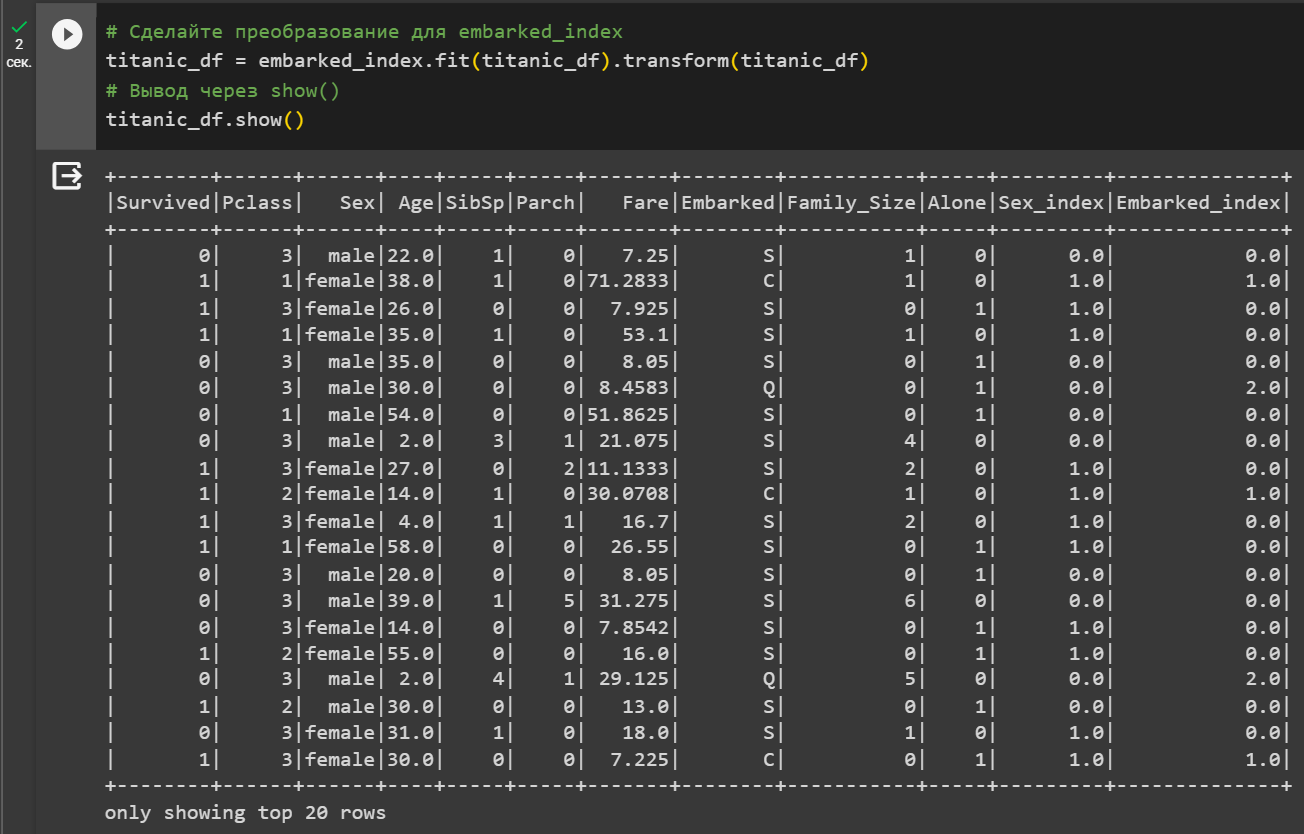
Рисунок 6 – Вывод измененного файла

Рисунок 7 – Работа с features и VectorAssembler

Рисунок 8 – Вывод тренировочного датасета
LogisticRegression

Рисунок 9 – Реализация LogisticRegression модели
DecisionTreeClassifier

Рисунок 10 – Реализация DecisionTreeClassifier модели
RandomForestClassifier

Рисунок 11 – Создание RandomForestClassifier модели
Gradient-boosted tree classifier

Рисунок 12 – Реализация Gradient-boosted tree classifier модели

Рисунок 13 – Сохранение и загрузки модели из директории
Pipeline - инструмент, позволяющий объединить последовательность этапов обработки данных и моделирования для эффективного и чистого выполнения многокомпонентных задач машинного обучения.

Рисунок 14 – Установка модуля PipelineModel
Разбиваем DataFrame titanic_df на тренировочный (80%) и тестовый (20%) наборы данных, выводим результата, преобразовываем два столбца в числовой формат, объединеняем столбцы в один вектор и создаем Pipeline

Рисунок 15 – Вывод тренировочного датасета

Рисунок 16 – Преобразование категориальных значений и формирование вектора

Рисунок 17 – Реализация Pipeline на модели RandomForestClassifier

Рисунок 18 – Сохранение и загрузки модели

Рисунок 19 – Вывод строк предсказаний

Рисунок 20 – Результат предсказания Pipeline на модели RandomForestClassifier
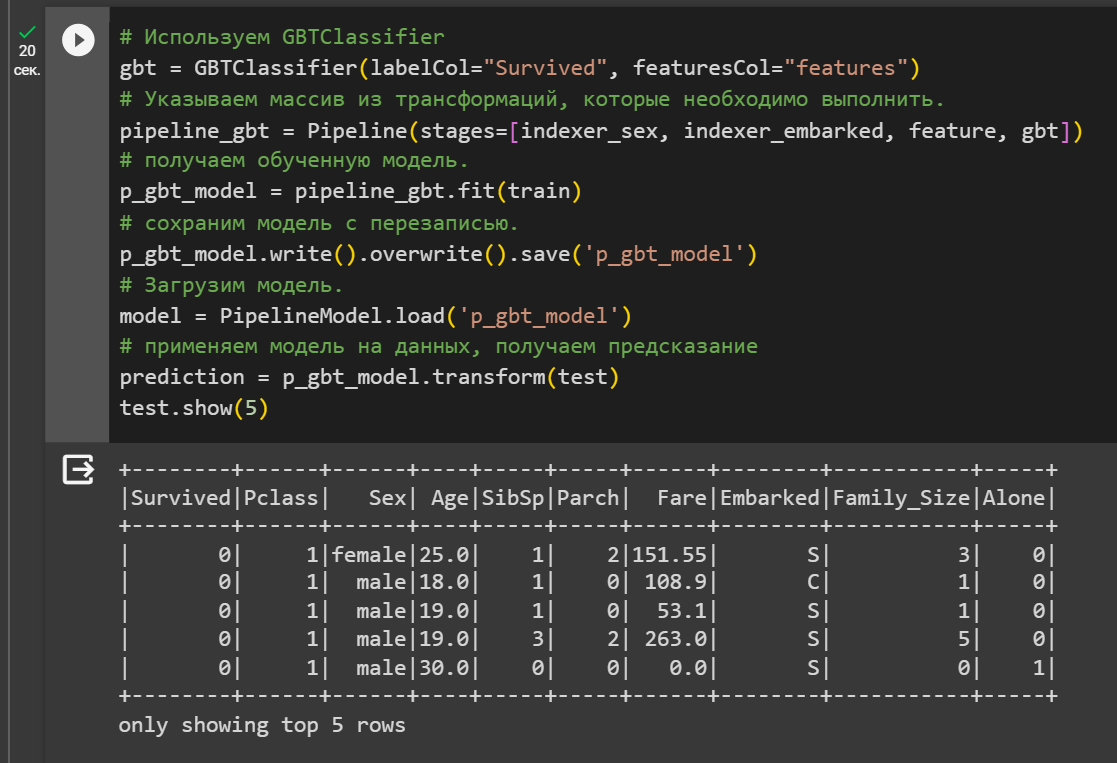
Рисунок 21 – Реализация Pipeline на модели Градиентного Бустинга

Рисунок 22 – Вывод Pipeline на модели Градиентного Бустинга