

МИНИСТЕРСТВО ЦИФРОВОГО РАЗВИТИЯ, СВЯЗИ И МАССОВЫХ КОММУНИКАЦИЙ РОССИЙСКОЙ ФЕДЕРАЦИИ
Ордена Трудового Красного Знамени федеральное государственное бюджетное образовательное учреждение высшего образования
«Московский технический университет связи и информатики»
Кафедра «Математическая кибернетика и информационные технологии»
Дисциплина «Большие данные»
Лабораторная работа 1
Выполнил:
студент группы БСТ2104
Мажукин И.Н.
Проверила: Полянцева К. А.
Москва, 2023 г.
Содержание
Цель работы 3
1 Задание 1 3
2 Ход работы 3
3 Задание 2 3
4 Ход работы 4
Работа с UI 13
Цель работы 3
1 Задание 1 4
2 Ход работы 4
3 Задание 2 4
4 Ход работы 5
Работа с UI 15
Цель работы
Получить навыки работы с файловой системой HDFS.
Задание 1
Требуется выполнить вход на хост с использованием протокола SSH, используя команду в формате "ssh username@<IP-адрес>". При первой попытке входа на хост необходимо сменить пароль. Для этого нужно будет ввести старый пароль, который указан в Jenkins Job, а затем новый пароль.
Ход работы
На рисунке 1 представлен вход на хост с использованием протокола SSH.
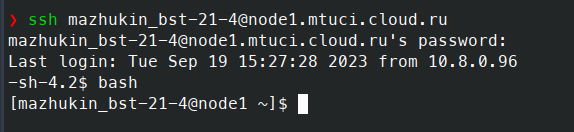
Рисунок 1 – Вход на хост с использованием протокола SSH
Задание 2
Создайте локальный тестовый файл, используя команду "echo "test text" >> test".
Увеличьте размер файла, чтобы он превышал размер одного блока HDFS, используя команду "fallocate -lv 777M test".
Создайте новую директорию в HDFS по пути "/data/test_dir".
Положите файл "test" в HDFS по пути "/data/test_dir/test", используя команду "hdfs dfs -put test /data/test_dir/".
Скопируйте директорию "/data/test_dir" в "/data/test_dir_1", используя команду "hdfs dfs -cp /data/test_dir /data/test_dir_1".
Удалите файл "test" из директории "test_dir_1" без сохранения файла в корзине, используя команду "hdfs dfs -rm /data/test_dir_1/test".
Просмотрите размер любой директории, используя команду "hdfs dfs -du -h /data/test_dir".
Просмотрите, как файл "/data/test_dir/test" хранится на файловой системе с помощью команды "hdfs fsck /data/test_dir/test".
Выполните команду "hdfs fsck /data/test_dir_1/test -blocks -files -locations".
Ход работы
На рисунке 2 показано создание локального тестового файла, используя команду "echo 'test text' >> test" и проверка, с помощью команды "cat test".

Рисунок 2 – Создание тестового файла
На рисунке 3 показан процесс создания локального тестового файла "test" размером 777 мегабайт с использованием команды "fallocate -l 777M test", а также результат выполнения команды "du -m test", показывающий, что размер файла действительно составляет 777 мегабайт.
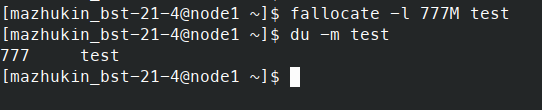
Рисунок 3 – Увеличение размера тестового файла до 777 МВ
На рисунке 4 показана команда "hdfs dfs -mkdir /data/test_dir_mazhukin", используемая для создания новой директории внутри файловой системы HDFS, а также команда "hdfs dfs -ls /data", показывающая список папок, находящихся внутри папки "data" в HDFS, который теперь содержит нашу новую директорию "test_dir_ mazhukin".

![]()
Рисунок 4 – Создание директории "test_dir_ mazhukin" в HDFS
На рисунке 5 показана команда "hdfs dfs -put test /data/test_dir_ mazhukin", используемая для копирование из локальной системы в HDFS локального файла "test" в директорию "test_dir_ mazhukin" в файловой системе HDFS, а также команда "hdfs dfs -ls /data/test_dir_ mazhukin", показывающая список файлов, находящихся внутри директории "test_dir_mazhukin" в HDFS, который теперь содержит только наш загруженный файл "test".


Рисунок 5 – Загрузка файла "test" в директорию "test_dir_ mazhukin " в HDFS
На рисунке 6 изображена команда "hdfs dfs -cp /data/test_dir_ mazhukin /data/test_dir_mazhukin_1", с помощью которой происходит копирование директории "test_dir_ mazhukin" с изменением имени на "test_dir_ mazhukin_1". Команда "hdfs dfs -ls /data" используется для проверки успешного копирования директорий.
![]()
![]()
Рисунок 6 – Копирование директории "test_dir_mazhukin" и создание "test_dir_mazhukin_1" в HDFS
На рисунке 7 представлены команды "hdfs dfs -rm -skipTrash /data/test_dir_mazhukin_1/test" для удаления файла "test" из директории "test_dir_mazhukin_1", "-skipTrash" указывает на то, что файлы должны быть удалены без отправки их в "Корзину", а также команда "hdfs dfs -ls /data/test_dir_mazhukin_1", показывающая содержимое директории после удаления файла и подтверждающая успешное выполнение операции.
Рисунок 7 – Копирование директории "test_dir_mazhukin" и создание "test_dir_mazhukin_1" в HDFS
На рисунке 8 представлена команда "hdfs dfs -du -h /data/test_dir_mazhukin", позволяющая определить размер директории "test_dir_mazhukin" в HDFS. Результат команды "777 M 2.3 G" указывает на то, что общий объем занимаемого пространства на диске для директории "test_dir_mazhukin" составляет 2,5 гигабайта, а размер файла "test" составляет 777 мегабайт и репликация этого файла занимает 2.3 гигабайта пространства на диске (учитывая фактор репликации по умолчанию, равный 3).
Р![]() исунок
8 –
Проверка
размера директории "test_dir_mazhukin"
в HDFS
исунок
8 –
Проверка
размера директории "test_dir_mazhukin"
в HDFS
На рисунке 9 показано выполнение проверки HDFS с использованием команды "hdfs fsck /data/test_dir/test -files -blocks -loca tions" и результат после успешной проверки.
Рисунок 9 - выполнение проверки HDFS
Какой фактор репликации установлен на кластере? Ответ: 3
Сколько блоков составляют файл? Ответ: 7
При выполнении команды fsck появилась строчка
Connecting to namenode via http://<active_namenode>:50070/fsck?ugi=user&path=%2Fdata%2Ftest1 |
Команда fsck также использует WebHDFS API.
Выполним команду hdfs fsck /data/test_dir_mazhukin_1/test -blocks -files –locations. "files" относится к файлам, хранящимся в HDFS. "blocks" являются минимальными единицами данных в HDFS. Файлы разбиваются на блоки фиксированного размера (обычно 128 МБ или 64 МБ) и каждый блок реплицируется на несколько узлов данных. "locations" относятся к физическим узлам данных, на которых хранятся реплики блоков.

Рисунок 10 – Вывод информация о каждом блоке, из которого состоит файл
Нам станет доступна информация о каждом блоке, из которого состоит файл. Разберем информацию по первому блоку HDFS:
0. BP-1573654390-10.53.210.XXX-1692789776563:blk_1073747600_6921 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[10.53.210.133:1019,DS-6e6240e7-5ce7-4cae-afd5-3382f24e049c,DISK], DatanodeInfoWithStorage[10.53.210.XXX:1019,DS-f0a4e64f-aa6c-4204-93e7-1ec4bba0dc59,DISK], DatanodeInfoWithStorage[10.53.210.143:1019,DS-f0d9852e-3d01-474d-95fc-856662cb5d38,DISK]] |
0. |
Номер блока по порядку |
BP-1573654390-10.53.210.XXX-1692789776563 |
Идентификатор block pull |
blk_1073747600 |
Идентификатор блока |
6921 |
Generation stamp. |
len=134217728 |
Объем блока |
Live_repl=3 |
Количество живых реплик блока |
DatanodeInfoWithStorage[10.53.210.133:1019 |
IP-адрес и порт, по которому доступен блок |
DS-6e6240e7-5ce7-4cae-afd5-3382f24e049c |
Data Storage ID идентификатор ноды (Если у ноды изменится hostname или IP-адрес, нода всё равно будет идентифицироваться внутри HDFS) |
DISK |
Способ хранения блока (Может также хранится в S3-хранилище) |
Заполните таблицу для данных первого блока Вашего тестового файла
0. |
Номер блока по порядку |
BP-2089730104-192.168.0.3-1694299343161 |
Идентификатор block pull |
blk_1073744156 |
Идентификатор блока |
3332 |
Generation stamp. |
len=134217728 |
Объем блока |
Live_repl=3 |
Количество живых реплик блока |
DatanodeInf oWithStorage[192.168.0.7:50010 |
IP-адрес и порт, по которому доступен блок |
DS-0fa1051e-e894-40f2-9702-25061bf076da |
Data Storage ID идентификатор ноды (Если у ноды изменится hostname или IP-адрес, нода всё равно будет идентифицироваться внутри HDFS) |
DISK |
Способ хранения блока (Может также хранится в S3-хранилище) |
Также с помощью команды можно узнать подробную информацию о состоянии конкретного блока данных (hdfs fsck -blockId blk_1073744156)
hdfs fsck -blockId blk_XXXXX |
Скопируйте результат работы команды для любого из блоков, составляющих ваш тестовый файл. Какие данные мы получили?

Рисунок 11 – Вывод информации о блоке
Выполним несколько команд через HDFS REST API. Так как на кластерах SDP Hadoop по умолчанию включена аутентификация kerberos, будем использовать соответсвтующий синтаксис команд:
Выполним вывод информации о файле /data/test_dir/test:
curl -i --negotiate -u : http://<active_namenode>:50070/webhdfs/v1/data/test_dir/test?op=GETFILESTATUS |
curl -i --negotiate -u : http://node1.mtuci.cloud.ru:50070/webhdfs/v1/data/test_dir_mazhukin/test?op=GETFILESTATUS
Какая информация выводится в результате работы команды?

Рисунок 12 – Вывод информации о файле /data/test_dir_mazhukin/test
HTTP/1.1 200 OK: Эта строка указывает на успешный ответ сервера с кодом состояния 200.
Date: Mon, 18 Sep 2023 19:07:56 GMT: Эта строка указывает на дату и время ответа сервера.
Cache-Control: no-cache: Этот заголовок указывает на то, что ответ не должен кэшироваться на клиентской стороне или промежуточных серверах.
Expires: Mon, 18 Sep 2023 19:07:56 GMT: Этот заголовок указывает на то, что ресурс будет считаться устаревшим после указанной даты и времени.
Pragma: no-cache: Этот заголовок указывает на то, что ответ не должен кэшироваться.
X-FRAME-OPTIONS: SAMEORIGIN: Этот заголовок указывает на опции фрейма X-Frame, определяющие, какие сайты имеют право встраивать данный контент внутри фрейма. В данном случае, заголовок говорит, что только сайты из того же источника (origin) имеют право встраивать контент.
Content-Type: application/json: Этот заголовок указывает на тип содержимого ответа, который в данном случае является JSON-данными.
Transfer-Encoding: chunked: Этот заголовок указывает на способ передачи содержимого, в данном случае содержимое передается блоками переменной длины.
{"FileStatus":{...}}: Это фрагмент JSON-данных, содержащий информацию о файле. В нем указаны различные свойства файла, такие как время доступа (accessTime), размер блока (blockSize), количество дочерних элементов (childrenNum), идентификатор файла (fileId), группа владельца файла (group), длина файла (length), время изменения файла (modificationTime), владелец файла (owner), суффикс пути файла (pathSuffix), разрешение доступа к файлу (permission), репликация файла (replication), хранилище файла (storagePolicy) и тип файла (type).
Теперь попробуем прочитать первые 10 символов тестового файла, используя тот же синтаксис команды:

Рисунок 13 – Вывод первых 10 символов тестового файла,
"curl -i --negotiate -u : http://<active_namenode>:50070/webhdfs/v1/data/test_dir/test?op=OPEN&length=10" |
curl -i --negotiate -u : http://node1.mtuci.cloud.ru:50070/webhdfs/v1/data/test_dir_mazhukin/test?op=OPEN&length=10
где
sber-node |
Адрес ноды, на которой установлен клиент hdfs |
50070 |
Порт подключения к REST API |
--negotiate |
включаем SPNEGO в curl |
/webhdfs/v1 |
Адрес Web API |
/data/test_dir/test |
Путь к нужному файлу в HDFS |
op= |
Производимое действие |
length= |
Желаемая длина считывания символов |
Почему мы не получили требуемых данных? Ответ: Мы обратились не дошли до нужной node.
Проанализируйте ссылку раздела location из ответа сервера
Для того, чтобы получить желаемые данные мы можем добавить в curl-запрос флаг -L (location). Эта опция заставит Curl повторить запрос для нового адреса, который мы получили ранее в Location.

Рисунок 14 – Вывод верной информации
"curl -i -L --negotiate -u : http://<active_namenode>:50070/webhdfs/v1/data/test_dir/test?op=OPEN&length=10" |
"curl -i -L --negotiate -u : http://node5.mtuci.cloud.ru:50070/webhdfs/v1/data/test_dir_mazhukin/test?op=OPEN&length=10"
Скопируйте файл /test из /data/test_dir в test_dir_1 и удалите его /data/test_dir_1/test с помощью curl-команды. Приложите скриншоты.
hdfs dfs -chmod -R 777 /data/test_dir_mazhukin
hdfs dfs -chmod -R 777 /data/test_dir_mazhukin_1
curl -i - -negotiate -u : -X PUT "http://node1.mtuci.cloud.ru:50070/webhdfs/v1/data/test_dir_mazhukin/test?op=RENAME&destination=/data/test_dir_mazhukin_1/"
curl -i - -negotiate -u : -X DELETE "http://node1.mtuci.cloud.ru:50070/webhdfs/v1/data/test_dir_mazhukin_1/test?op=DELETE&recursive=false"

Рисунок 15 – Выполнение команд