

Отчёт_по_лабораторной_работе_№5_Мажукин_БСТ2104
.docxМинистерство цифрового развития связи и массовых коммуникаций
Ордена Трудового Красного Знамени
Федеральное государственное бюджетное образовательное учреждение
высшего образования
«МОСКОВСКИЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
СВЯЗИ И ИНФОРМАТИКИ»
Кафедра «Математическая кибернетика и информационные технологии»
Отчёт по лабораторной работе №5
по дисциплине «Большие данные»
Выполнил: студент группы БСТ2104
Мажукин И.Н.
Проверил: Тимофеева А.И.
Москва, 2023 г.
СОДЕРЖАНИЕ
№ стр.
1 |
Цель лабораторной работы . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . |
3 |
2 |
Выполнение заданий файла 01_spark_rdd.ipynb. . . . . . . . . . . . . . . . . . . . |
3 |
|
2.1 Предварительные настройки. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . |
3 |
|
2.2 Задача 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . |
5 |
|
2.3 Задача 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . |
6 |
|
2.4 Задача 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . |
7 |
|
2.5 Задание . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . |
8 |
3 |
Вывод . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . |
10 |
ЦЕЛЬ ЛАБОРАТОРНОЙ РАБОТЫ
Получить навыки работы с фреймворком Spark.
ВЫПОЛНЕНИЕ ЗАДАНИЙ ФАЙЛА 01_SPARK_RDD.IPYNB
2.1 Предварительные настройки
На рисунке 1 представлена установка OpenJDK 8, Apache Spark и распаковка скачанного архива Spark
![]()
Рисунок 1 – Установка OpenJDK 8, Apache Spark и распаковка скачанного архива Spark
На рисунке 2 представлена установка переменных окружения с указанными путями

Рисунок 2 – Установка переменных окружения с указанными путями
На рисунке 3 представлена установка пакета findspark

Рисунок 3 – Установка пакета findspark
На рисунке 4 представлены команды для импорта и инициализации findspark

Рисунок 4 – Команды для импорта и инициализации findspark
На рисунке 5 представлены команды для импорта pyspark и создания SparkContext

Рисунок 5 – Команды для импорта pyspark и создания SparkContext
На рисунке 6 представлено создание переменной sc, которая возвращает текущий объект SparkContext

Рисунок 6 – Создание переменной sc
2.2 Задача 1
При подсчёте отсеять пунктуацию и слова короче 3 символов. При фильтрации можно использовать регулярку: re.sub(u"\\W+", " ", x.strip(), flags=re.U).
Код и результат работы программы представлен на рисунке 7.

Рисунок 7 – Код и результат работы задачи 1 файла 01_spark_rdd.ipynb
2.3 Задача 2
Считать только имена собственные. Именами собственными в данном случае будем считать такие слова, у которых 1-я буква заглавная, остальные - прописные.
Код и результат работы программы представлен на рисунке 8.

Рисунок 8 – Код и результат работы задачи 2 файла 01_spark_rdd.ipynb
2.4 Задача 3
Переделайте задачу 2 так, чтоб кол-во имён собственных вычислялось с помощью аккумулятора.
Код и результат работы программы представлен на рисунке 9.

Рисунок 9 – Код и результат работы программы задачи 3 файла 01_spark_rdd.ipynb
2.5 Задание
Считать csv-файл в формате DataFrame, вывести первые n-записей, применить фильтр к данным, вывести данные с группировкой, вывести данные с группировкой и агрегированием
На рисунке 10 представлен код для считывания csv-файла в формате DataFrame и вывода первых 10 записей

Рисунок 10 – Код для считывания csv-файла и вывода первых 10 записей
Ответ на вопрос:
inferSchema в PySpark — это параметр, который указывает библиотеке на необходимость автоматического определения схемы данных при чтении данных в DataFrame.
Если не указать inferSchema явно, то PySpark будет использовать типы данных по умолчанию (обычно строки) для всех колонок. В приведённом выше коде это может привести к тому, что значения числовых колонок будут обработаны как строки, что может вызвать проблемы при выполнении агрегаций, фильтрации и других операций, где важен тип данных.
На рисунке 11 представлена команда для применения фильтра к данным

Рисунок 11 – Команда для применения фильтра к данным
На рисунке 12 представлен код группировки данных и вывод первых 10 строк группировки

Рисунок 12 – Группировка данных и вывод первых 10 строк группировки
На рисунке 13 представлен код группировки, агрегирования данных и вывод первых 10 строк группировки
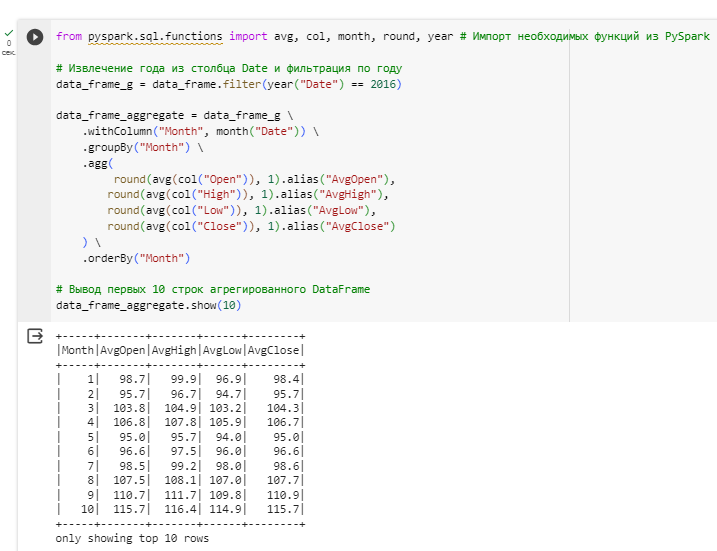
Рисунок 13 – Группировка, агрегирование данных и вывод первых 10 строк группировки
ВЫВОД
В результате выполнения данной лабораторной работы были получены навыки работы с фреймворком Spark.