

5 курс / ОЗИЗО Общественное здоровье и здравоохранение / Проектирование_мультимодальных_интерфейсов_мозг_компьютер
.pdfИМК на базе вызванных потенциалов
вий эксперимента. Данная матрица может быть сохранена и использована в дальнейшем при использовании метода xDAWN.
Далее рассмотрим применение метода XDAWN в конвейере scikit- learn. Для этого создадим объект pipeline, который включает следующие этапы:
‒Xdawn — метод для двух компонент;
‒Vectorizer — метод преобразует данные эпох MNE в двумерный массив (n_samples и n_features) для применения в дальнейшем методов scikit-learn;
‒MinMaxScaler — нормализация данных в массиве (0;1);
‒LogisticRegression — логистическая регрессия для двух классов. Фильтры xDAWN обучаются по эпохам, сигнал проецируется в про-
странство источников, а затем обратно, в пространство датчиков, с использованием только первых двух компонентов XDAWN. Процесс похож на ICA, но контролируется, чтобы максимизировать отношение сигнал – шум вызванного ответа. Ниже приведем фрагмент кода для демонстрации работы метода.
n_filter = 2
clf = make_pipeline(Xdawn(n_components=n_filter), Vectorizer(), MinMaxScaler(),
LogisticRegression(penalty=
'l1', solver='liblinear', multi_class='auto'))
#Получаем метки классов для отдельных эпох labels = epochs.events[:, –1]-1
#Кросс валидатор
cv = StratifiedKFold(n_splits=10, shuffle=True, random_ state=42)
#Поводим кросс-валидацию preds = np.empty(len(labels))
for train, test in cv.split(epochs, labels): clf.fit(epochs[train], labels[train]) preds[test] = clf.predict(epochs[test])
#Отчет о классификации
target_names = ['NonTarget', 'Target']
report = classification_report(labels, preds, target_ names=target_names)
print(report)
# Нормализованная матрица ошибок
79
Рекомендовано к покупке и изучению сайтом МедУнивер - https://meduniver.com/

Глава 4. Извлечение значений признаков для различных типов ИМК
cm = confusion_matrix(labels, preds)
cm_normalized = cm.astype(float) / cm.sum(axis=1)[:, np.newaxis]
Для оценки качества работы алгоритма, на каждом из классов по отдельности с помощью метода classification_report считаются метрики: precision (точность) и recall (полнота) (табл. 2). Определим точность и полноту в терминах матрицы ошибок (confusion matrix):
precision = TP/(TP+FP); recall = TP/(TP+FN),
где TP, FP, FN — абсолютные значения из матрицы ошибок. Precision можно интерпретировать как долю объектов, названных
классификатором положительными и при этом действительно являющихся положительными, а recall показывает, какую долю объектов положительного класса из всех объектов положительного класса нашел алгоритм [70].
Обычно при оптимизации гиперпараметров алгоритма используется одна метрика, улучшение которой мы и ожидаем увидеть на тестовой выборке. Существует несколько различных способов объединить precision и recall в агрегированный критерий качества.
F-мера — среднее гармоническое precision и recall [70]. Условно говоря, чем ближе F к единице, тем лучше решение; чем ближе к 0, тем хуже решение.
Таблица 2
Отчет о результатах работы классификатора в программе «ПИТОН»
Параметры |
|
Показатели |
|
||
|
|
|
|
||
precision |
recall |
f1 score |
support |
||
|
|||||
|
|
|
|
|
|
NonTarget |
0.95 |
0.97 |
0.96 |
1440 |
|
Target |
0.83 |
0.72 |
0.77 |
288 |
|
accuracy |
— |
— |
0.93 |
1728 |
|
macro avg |
0.89 |
0.85 |
0.87 |
1728 |
|
weighted avg |
0.93 |
0.93 |
0.93 |
1728 |
|
В табл. 3 представлена матрица ошибок. Эпохи класса Target (требуемый символ) достаточно часто выбирались как эпохи класса NonTarget (не тот символ). Это связано с тем, что мы провели классификацию
80

Вопросы и задания к главе 4
каждой эпохи в отдельности. На практике для протокола P300 принято применять дополнительное усреднение сигнала для каждого показанного символа по нескольким эпохам. Такой подход позволяет дополнительно увеличить соотношение сигнал – шум.
|
|
Таблица 3 |
|
Матрица ошибок |
|
|
|
|
Классы |
NonTarget (0) |
Target (1) |
|
|
|
NonTarget (0) |
0.970833 |
0.0291667 |
Target (1) |
0.277778 |
0.722222 |
В следующей главе мы рассмотрим применение нейронных сетей для классификации эпох протокола P300. Особенностью данного подхода является обучение и тестирование сети на сыром сигнале. Задачи фильтрации сигнала, повышения соотношения сигнал – шум решаются с помощью слоев сети.
Вопросы и задания к главе 4
1.Что является основой для формирования признакового пространства?
2.Какой нейрофизиологический феномен лежит в основе ИМК на базе сенсомоторных ритмов?
3.Назовите методы пространственной фильтрации, которые не зависят от данных.
4.Какова основная идея метода пространственной фильтрации
CSP?
5.В чем главное отличие метода FBCSP от CSP?
6.Опишите сценарий применения ИМК на базе сенсомоторных ритмов.
7.Опишите нейрофизиологический феномен, который лежит в основе ИМК на базе протокола P300.
8.Какова основная идея метода пространственной фильтрации xDAWN?
9.Опишите сценарий применения ИМК на базе протокола P300.
81
Рекомендовано к покупке и изучению сайтом МедУнивер - https://meduniver.com/

Глава 4. Извлечение значений признаков для различных типов ИМК
10.Попробуйте изменить параметры фильтра xDAWN—число компонент, из которых складывается признаковое пространство. Какие отличия вы наблюдаете в статистике работы классификатора и матрицы ошибок?
11.Попробуйте исключить фильтр xDAWN из контейнера:
clf = make_pipeline(Xdawn(n_components=n_filter), Vectorizer(), MinMaxScaler(),
LogisticRegression(penalty='l1',
solver='liblinear', multi_class='auto'))
Какие отличия вы наблюдаете в статистике работы классификатора и матрицы ошибок?
82

Глава 5. Применение методов машинного обучения для ИМК
Алгоритмы машинного обучения (ML) используют данные биомедицинских сигналов для изучения характеристик сигналов мозга конкретных испытуемых. Они применяются для предсказания изменения биомедицинских сигналов пользователей на новых данных разных модальностей [71]. Алгоритмы машинного обучения делятся на три группы:
‒обучение с учителем,
‒без учителя,
‒с подкреплением.
Далее на примере использования алгоритмов рассмотрим обучение с учителем.
Обучение с учителем
Алгоритмы контролируемого обучения строят прогноз данных на основе размеченных данных. Размеченные обучающие данные используются в контролируемом обучении для того, чтобы машина могла обучаться. С помощью методов машинного обучения обучающие данные используются для принятия решений о неизвестных закономерностях, присутствующих в размеченных данных, что приводит к успешному прогнозированию или классификации на данных тестирования.
Классификация — это метод, с помощью которого группа параметров, состоящая из нескольких меток, распределяется в один класс. Классификация может быть проведена на структурированных или неструктурированных данных. Цель классификации — определить, к какому классу или группе относятся вновь добавленные данные.
83
Рекомендовано к покупке и изучению сайтом МедУнивер - https://meduniver.com/
Глава 5. Применение методов машинного обучения для ИМК
Классификация задач двигательного воображения является примером проблемы классификации; проблема может быть бинарной классификацией при существовании двух классов, то есть классификация движения как левой или как правой руки, и мультиклассификацией при существовании более чем двух классов, например, классификация движения как левой руки, как правой руки, как ног и так далее.
Регрессия —это стандартная статистическая техника для определения функционального соответствия между переменными, обычно используется для моделирования временных рядов. Регрессионный анализ дает одномерные или многомерные, простые или множественные ответы на прогнозируемые переменные; линейные и нелинейные ответы генерируются для линейно преобразуемых данных и нелинейно преобразуемых данных соответственно [29]. Регрессионный анализ является основным инструментом для моделирования и анализа данных. В настоящей главе мы представим упрощенную задачу применения методов машинного обучения для реализации интересов мозг-компью- тер и используем для ее решения простую нейронную сеть. Для этого будем использовать набор данных, предоставленный в библиотеке MNE-Python. Он представляет собой ряд образцов сигналов ЭЭГ, содержащих 226 точек данных на образец (временные отсчеты), где каждый образец представляет собой одно испытание, описанное в задаче. Ниже приведен график двух таких построенных образцов, канал отображается в правом верхнем углу графика (рис. 44).
Рис. 44. Пример изображения образцов ЭЭГ
84
Обучение с учителем
Постановка типичной задачи
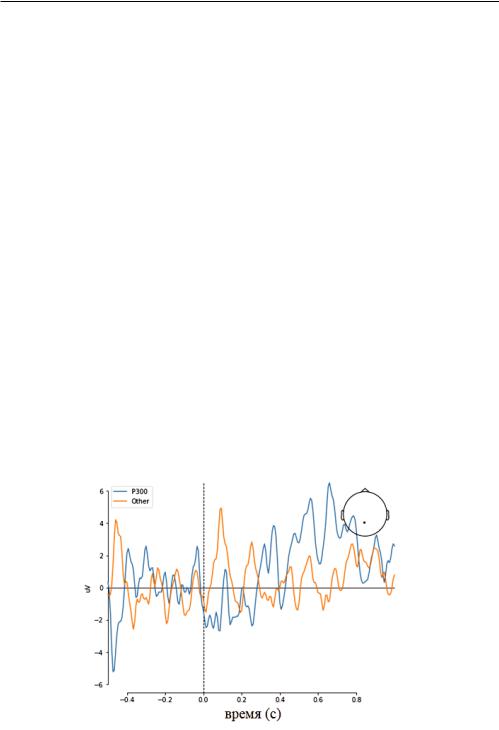
Предположим, у нас есть субъект, который сидит и смотрит на экран с набором отображаемых изображений. В эксперименте испытуемому предъявлялись шахматные узоры в левом и правом поле зрения, перемежающиеся тонами для левого или правого уха. Интервал между стимулами составлял 750 мс. Иногда в центре поля зрения появлялся смайлик. Испытуемому предлагалось нажать указательным пальцем правой руки клавишу как можно быстрее после появления лица. Используя только предоставленный поток данных ЭЭГ (рис. 45), определите, когда субъекту будет показано изображение улыбающегося лица, прежде чем он нажмет клавишу.
Рис. 45. Пример изображения образцов ЭЭГ
Цель данного эксперимента — отследить реакцию «удивление» или «ожидание». На этот ответ обычно указывает хорошо изученный ответ ЭЭГ, называемый компонентом P300. Если мы создадим систему для его обнаружения в потоке данных ЭЭГ, найдем решение нашей задачи.
Можно определить, что P300 — это всплеск, или положительное отклонение, которое появляется на наших ЭЭГах примерно через 300 мс после того, как мы заметили редкий или целенаправленный стимул. Например, он появится в вашей ленте данных ЭЭГ, если кто то вытянет из колоды карту, которую вы ожидали, [72]. Непосредственным способом применения P300 в приложениях BCI является спеллер P300. Это приложение позволяет пользователю печатать, выбирая буквы алфавита, отображаемого на экране, просто фокусируясь на букве, которую он собирается ввести. Использование P300 для обнару-
85
Рекомендовано к покупке и изучению сайтом МедУнивер - https://meduniver.com/

Глава 5. Применение методов машинного обучения для ИМК
жения событий является простым методом, но, как мы узнаем позже, обнаружение событий без использования усредненного значения может быть очень сложным.
Пример использования методов машинного обучения в задачах ИМК
Представим, что мы смотрим футбольный матч и остановили телевизор на съемке с воздуха. Что если бы мы хотели иметь возможность предсказывать, в какой команде находится игрок, только по тому, где он стоит на поле? Как мы могли это сделать? Самый простой способ — нарисовать кривую между двумя командами (рис. 46).
Рис. 46. Пример разделения пространства признаков для игроков двух команд [73]
Если мы также рассмотрим позиции игроков относительно времени, в течение которого они их занимают, у нас получится четырехмерная задача, для которой потребуется четырехмерная кривая. Это гораздо труднее, может быть, даже невозможно визуализировать.
Теперь давайте вернемся к нашей проблеме с P300. В каждом временном ряде есть 226 точек данных, каждая из них будет считаться измерением данных. Почему мы можем рассматривать эту задачу не как двумерную задачу, как ту, что мы видим на рис. 46? На этом рисунке вы можете видеть, что два типа данных ЭЭГ пересекаются. Однако
86
Пример использования методов машинного обучения в задачах ИМК
если мы хотим представить эти мозговые волны так же, как мы представляем футболистов, то нам придется поместить волну в виде единой точки внутри 226-мерного пространства. Затем, когда у нас есть набор данных ЭЭГ, помещенных в это 226-мерное пространство, мы можем создать 226-мерную кривую, которая их разделяет.
Мало того, что это пространство невозможно захватить на одном снимке, сложность решения увеличивается экспоненциально с каждым добавленным измерением. Чтобы решить проблемы такого масштаба, нам понадобится набор математических инструментов, которые превосходно подходят для решения многомерных задач. Когда мы смотрим на мозговые волны, мы видим точки данных во времени. Однако, когда данная информация обрабатывается алгоритмом машинного обучения, вся мозговая волна представляется в виде единой точки. Каждая мозговая волна будет отображаться таким образом, и мы попытаемся найти функцию в размерности, которая отделит P300 от обычных данных ЭЭГ. Машины могут работать в любом количестве измерений, которые людям трудно представить. Кроме того, у них есть способность делать прогнозы таким образом, что это было бы слишком сложно даже для армии математиков.
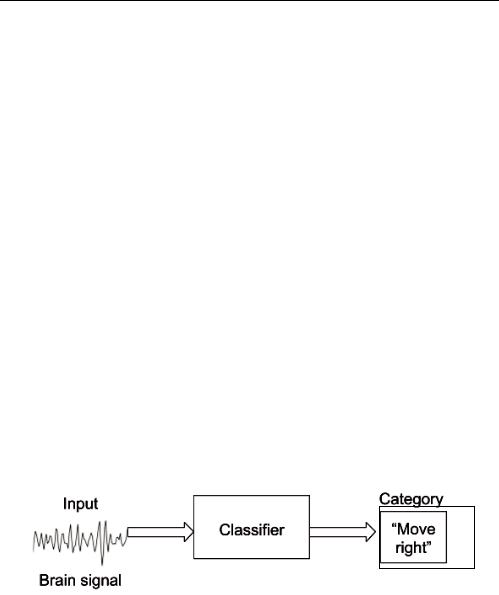
В контексте нейрокомпьютерных интерфейсов машинное обучение в основном используется для разработки классификаторов. Например, классификатор может получать на вход сигнал мозга и ставить на нем метки — «Двигаться вправо» (рис. 47).
|
|
|
|
|
|
|
Категория |
|
|
Входные |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Классификатор |
|
|
«Двигаться |
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
вправо» |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
сигналы мозга |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 47. Пример работы классификатора для входных данных ИМК
Существует множество различных алгоритмов машинного обучения, но давайте сосредоточимся на нескольких распространенных проверенных алгоритмах, которые могут помочь решить проблему классификации. Ниже приведены наиболее распространенные алгоритмы, используемые в приложениях ИМК.
87
Рекомендовано к покупке и изучению сайтом МедУнивер - https://meduniver.com/

Глава 5. Применение методов машинного обучения для ИМК
Метод опорных векторов (SVM)
Задача классификации относится к обучению с учителем. Метод опорных векторов (англ. SVM, Support Vector Machine)— алгоритм обучения с учителем. В общих чертах алгоритм SVM, как и другие методы машинного обучения, нацелен на определение кривой, способной разделять два разных класса данных. Для многомерного пространства эта кривая называется гиперплоскостью.
Чтобы найти правильную гиперплоскость, алгоритм проходит процесс оптимизации, при котором количество неправильно классифицированных экземпляров (игроков в приведенном выше примере) сводится к минимуму. Данный процесс называется обучением алгоритма, далее его рассмотрим. Следует иметь в виду, что самое простое решение для классификации двух разных типов элементов, таких, например, как две команды, — провести между ними линию (рис. 48).
Рис. 48. Пример разделения параметров гиперплоскости [73]
В задаче, которую решаем, мы хотим определить, видит ли пользователь что-то неожиданное, основываясь на своих сигналах ЭЭГ. Для этого нам понадобятся образцы данных данных ЭЭГ, содержащие компонент P300 и не содержащие компонент P300 (которые будут нашими двумя классами) для обучения алгоритма. Данные, которые мы будем передавать SVM, будут значениями, полученными для каждого из каналов нашей сборки ЭЭГ.
88