

Лабораторная работа №5
Тема: Организация работы со списками средствами Пролога.
Цель: Научиться работать со списковыми структурами Пролога.
1. Списки
Списки – это объекты, которые могут содержать различное число однотипных данных. Например: [1,2,3], [dog, cat, canary].
Предположим, нам необходимо создать справочную базу, в которой будем сохранять данные о лекционных курсах, которые могут читать профессора. Её можно реализовать с помощью следующей программы:
predicates
teacher(symbol,symbol,symbol)
clauses
teacher(ed,willis,english1).
teacher(ed,willis,math1).
teacher(ed,willis,hystory).
teacher(mary,marker,english2).
teacher(mary,marker,math2).
teacher(mary,marker,geometry).
Тут возникает необходимость повторять имена профессоров для каждого предмета. Это трудоёмко, поэтому лучше всего использовать тип списка. В следующем примере аргумент classes описан как тип списка.
domains
classes = symbol*
predicates
teacher(symbol,symbol,classes)
clauses
teacher(ed,wills,[english1,math1,hystory]).
teacher(mary,marker,[english2,math2,geometry]).
В этом примере отметим описание раздела domains:
domains
classes = symbol*.
Здесь демонстрируется, как описываются в Прологе списки. Символ (*) означает, что аргумент classes является символьным списком. Аналогично можно описать список целочисленных данных:
domains
integer_list = integer*.
Элементами списка могут быть самые разные данные, даже другие списки. Все элементы должны принадлежать одной области. Описание областей для элементов должно иметь следующую форму:
domains
elementlist = elements*
elements = integer
Список – это рекурсивная структура, которая состоит из головы и хвоста. Головой называют первый элемент списка, а хвост – это все остальные элементы. Хвост списка всегда будет списком, а голова – это один элемент. Отметим, что пустой список не возможно разделить на голову и хвост. Обозначается пустой список как [].
Концептуально списки имеют структуру дерева. Например, список [a,b,c,d] можно представить следующим образом:
list

a list

b list
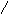
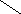 c
list
c
list
d []
А одноэлементный список [а] имеет вид:
list
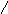

a []
Пролог даёт возможность явно задавать голову и хвост списка. Вместо отделения элементов запятыми, можно выделить голову и хвост знаком «|». Например, список [a,b,c] равен списку [a | [b,c]] [a | [b | [c | []]]].
Разделители можно также комбинировать. Так список [a,b,c,d] можно задать следующим образом [a,b | [c,d]].
Для обработки списков лучше всего подходят рекурсивные алгоритмы. Обработка списка состоит из рекурсивного смещения и обработки головы списка до тех пор, пока список не станет пустым. Алгоритм такого типа традиционно состоит из двух фраз. Первая из них говорит, что необходимо делать со списком, а вторая – что делать с пустым списком.
Обеспечить печать элементов списка можно следующим образом:
domains
list = integer* % или любой другой тип, который хотите использовать
predicates
write_a_list(list)
clauses
write_a_list([]). % если список пуст, то ничего не делать.
write_a_list([H |T]):- /* отделяем голову списка Н (Head) и хвост Т(Tail), затем печатаем Н и рекурсивно обрабатываем Т */
write(H),nl,
write_a_list(T).
Если задать цель: write_a_list([1,2,3]), то список [1,2,3] будет разбит на голову Н=1 и хвост Т = [2,3]. Предикатом write(H) напечатается голова, и рекурсивно будет обрабатываться предикатом write_a_list(T) хвост [2,3]. Процесс завершится, когда хвост станет пустым списком.
Используя тот же рекурсивный принцип, можно выявить, принадлежит ли данный элемент заданному списку. Пусть предикат, выясняющий данный факт, будет иметь вид:
member(name, namelist)
В следующей программе первая фраза исследует голову списка. Если голова списка совпадает с именем элемента, которое мы ищем, тогда можно сделать вывод, что имя принадлежит списку. Так как в данном случае хвост списка нас не интересует, то он характеризуется анонимной переменной. Если же имени нет в голове, то его необходимо рекурсивным образом поискать в хвосте списка. За это и отвечает вторая фраза программы.
is_a_member_of(Name,[Name|_]).
is_a_member_of(Name,[_|Tail]):- is_a_member_of(Name,Tail).
Существуют и другие полезные рекурсивные процедуры обработки списков:
Является ли списком:
list([]):-!.
list([H|T]):-
list(T).
Объединение двух списков:
append([],L,L).
append([H|T],L,[H|T1]):-
append(T,L,T1).
Разбиение списка на два: c положительными и отрицательными элементами:
split([],[],[]):-!.
split([H|T],[H|T1],L):-
H>=0,
split(T,T1,L),!.
split([H|T],L,[H|T1]):-
split(T,L,T1).
Соединениедвух списков [a1,a2,a3,...] и [b1,b2,b3,...] по правилу [a1,b1,a2,b2,a3,b3,...]:
app([],L,L).
app(L,[],L).
app([H1|T1],[H2|T2],[H1,H2|T]):-
app[T1,T2,T).
Число элементов в списке:
number([],0).
number([H|T],N) :- number(T,M), N=M+1.
Удаление первого вхождения элемента в список:
del1(X,[X|Y],Y) :- !.
del1(X,[Z|Y],[Z|W]) :- del1(X,Y,W).
Удаление всех вхождений элемента в список:
del_all(X,[],[]).
del_all(X,[X|Y],W) :- del_all(X,Y,W).
del_all(X,[Z|Y],W) :- del_all(X,Y,W).
Индексация элементов списка (получить элемент под номером N или узнать номер элемента X):
get([X|Y],1,X).
get([W|Y],N,X) :- N=M+1, get(Y,M,X).
Поиск максимального элемента в списке:
max([X],X).
max([X|Y],X) :- max(Y,W), X>W.
max([X|Y],W) :- max(Y,W).
Обращение списка:
revers([X],[X]).
revers([X|Y],Z) :- revers(Y,W), app(W,[X],Z).