

PobedilRomanskogo / Введение в MPI
.pdfКоды ошибок
Все MPI подпрограммы (кроме MPI_WTIME и MPI_WTICK) возвращают код ошибки.
Для C/С++ возврат идет в значении функции, для Фортрана - в последней переменной процедуры.
Перед возвратом ошибки вызывается обработчик ошибок MPI. Стандарт
не гарантирует, что после ошибки будет продолжено исполнение программы (хотя это можно сделать).
MPI_SUCCESS - код успеха.
MPI_ERR_COMM – задан неверный коммуникатор. MPI_ERR_COUNT - задано неверное количество аргументов.
MPI_ERR_TYPE – неверный тип.
MPI_ERR_TAG – неверный тэг. MPI_ERR_RANK - неверный ранг. MPI_ERR_REQUEST - неверный запрос.
MPI_ERR_INTERN – внутренняя ошибка MPI (как правило, возникает
при обращении в «чужой» участок памяти). |
|
MPI_ERR_OTHER – другая ошибка. |
31 |
Запуск и компиляция программ
Запуск: mpirun –np N prog.exe
N – число вычислительных ядер; prog.exe – имя mpi-программы.
Компиляция: mpif90 names.f90 -o names.exe Язык C: mpicc names.c –o names.exe
mpif90, mpicc - это обертка над компиляторами f90, cc.
Посмотреть ключи компиляции командой: mpif90 –showme
32

Л/Р №3 - Параллельное программирование с помощью MPI: Вычисление определенного интеграла
•Написать и откомпилировать программу hello_world с помощью MPI. Запустить ее на 1, 5, 10 вычислительных ядрах (mpif90, mpirun –np N)
•Реализовать параллельный алгоритм вычисления определенного интеграла по методу трапеций. Воспользоваться по вариантам парами процедур
(MPI_SEND / MPI_RECV; MPI_ISEND / MPI_IRECV).
•Оформить процедуру вычисления подынтегральной функции в виде функции.
•Протестировать программу на различном числе вычислительных ядер: 1, 2, 5, 10, 25, 50. Заполнить таблицу. Число разбиений M=1 000 000 и 10 000 000. Сравнить реальное ускорение с теоретическим.
• Для проверки использовать интеграл |
1 |
4dx |
|
2 . |
|
|
|
0 1 x
•Прием результатов интегрирования от ненулевых процессов к 0-ому выполнять в цикле, переменная цикла – номер процесса.
•Печать конечного результата нужно реализовать только на 0-ом процессе.
•Воспользоваться очередью задач PBS Torque (слайд №33)*
Количество ядер, N Число разбиений, M Время исполнения, с.
1,2,10,25,50
33
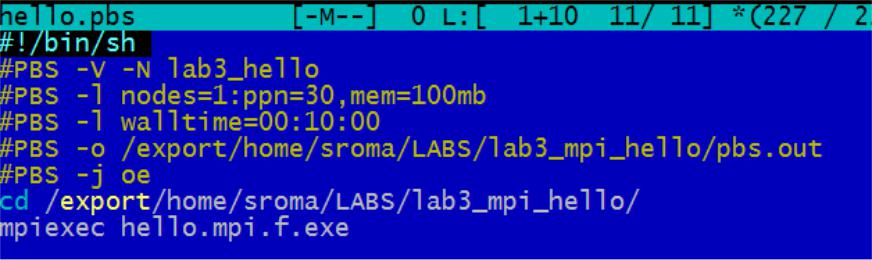
Очередь задач PBS Torque
ppn=M – число процессов. |
|
-N name –имя задания. |
|
walltime – время исполнения программы (максимальное). |
|
cd dir – необходимо принудительно перейти в директорию с |
|
программой. |
|
mpiexec – обертка над mpirun для запуска заданий в очереди |
|
задач. |
|
Запуск командой: qsub name.pbs |
|
Статус исполнения: qstat |
|
Удалить зависшее задание: qdel number. |
34 |
|
name.pbs – имя файла с заданием; number – номер в очереди.
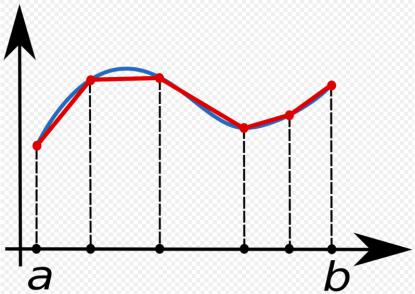
Метод трапеций
b |
1 |
|
n 1 |
|
|
|
|
|
f (x)dx |
|
f (xi 1 ) f (xi ) (xi 1 xi ). |
|
|||||
|
|
|||||||
a |
2 i 0 |
|
|
|
|
|||
b |
|
|
f (a) f (b) |
N 1 |
b a |
|
||
|
|
|
||||||
f (x)dx |
|
|
f (xi |
) |
|
. |
||
2 |
N |
|||||||
a |
|
i 1 |
|
|
||||
Требуется реализовать метод трапеций с постоянным шагом h.
35
Закон Амдала
Алгоритм: доля α от общего объема вычислений может быть получена только последовательными расчетами (время Tпос), а, соответственно, доля 1 − α может быть распараллелена (то есть время вычисления Tпар будет обратно пропорционально числу задействованных процессов N). Тогда ускорение k, которое может быть получено на вычислительной системе из N процессоров, по сравнению с однопроцессорным решением не будет превышать величины:
|
|
1 |
|
|
T |
|
T |
||||
k |
|
|
|
|
|
|
пар пос |
. |
|||
|
1 |
|
|
|
|||||||
|
|
|
|
Tпос |
|
Tпар |
|
|
|||
|
N |
|
|
||||||||
|
|
|
|
N |
|||||||
|
|
|
|
|
|
|
|
||||
36
Список литературы
1.http://parallel.ru/tech/tech_dev/mpi.html
2.Антонов А.С. Параллельное программирование с использованием MPI, 2004г.
3.Пересветов В.В. Программирование параллельных вычислений в стандартах OpenMP и MPI : сб. лаб. работ. – Хабаровск: Изд-во ДВГУПС, 2009. – 80с. (лаб. №4).
4.MPI Standard 2.2 (Sep. 2009).
37