

ЛЕКЦИЯ 8.
ПОНЯТИЕ ИЗБЫТОЧНОСТИ – ОСНОВА ПРИМЕНЕНИЯ МЕТОДОВ СЖАТИЯ ИНФОРМАЦИИ.
ЦЕЛЬ ЛЕКЦИИ: На основе меры информации изложить математическое содержание задачи сжатия информации, рассмотреть варианты классификации и дать анализ существующих методов сжатия.
Всякая вещь есть форма проявления беспредельного разнообразия.
Козьма Прутков
В материалах лекции 3 в терминах математической теории связи мы охарактеризовали термин “сжатие” как свойство некоторого источника, определяемое относительной энтропией данного источника при ограниченном наборе символов. Там же было введено понятие “избыточность” в рамках статистического подхода. Рассмотрим оба понятия несколько шире, распространив их на источники случайных непрерывных сигналов, представляющих собой функции времени. Математическая теория связи рассматривает подобные случайные непрерывные сигналы как источники, характеризующиеся непрерывным распределением с известной функцией плотности распределения [см. 1. стр. 290 – 305]. Приняв выводы теории за основу, отметим, что в случае, когда статистики сигналов являются объектом исследования, необходим несколько иной подход к определению количества информации в сообщении. Кроме того, практическое использование выводов затруднено из-за сложности расчетов при проектировании устройств телекоммуникационных систем вследствие того, что:
- уже при первичном преобразовании в результат обработки вносятся погрешности;
- методы первичной обработки выбираются с учетом требований реального канала связи.
Пусть имеется некоторый источник случайного непрерывного сигнала f(t), вероятностные характеристики которого нам не известны. Вполне корректно считать, что амплитудные значения сигнала в случайные моменты времени равновероятны, т. е. pi = 1/n. С целью определения реализации процесса произведем n отсчетов в моменты времени t1, t2, ..,tn. Подставим в формулу энтропии значение pi = 1/n.
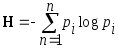
В результате преобразований получим выражение
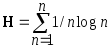
Если выборки квантуются по уровню, и N – число уровней квантования, то, принимая основание кода m = 2, получим
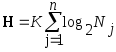
Полученное выражение характеризует количество информации о случайном процессе, описываемом функцией времени f(t), подвергнутом операциям дискретизации по времени и квантования по уровню. Выражение сходно с выражением для аддитивной меры количества информации, введенным в 1928 году американским инженером Р. Хартли. Вполне очевидно, что в данном случае количество информации определяется числом бит. С точки зрения получателя данная мера определяет конкретную последовательность двоичных единиц, которой может быть описан случайный сигнал при восстановлении его на приемной стороне. В этом случае более подходящим является понятие объема данных.
Объем данных – это количество двоичных единиц (бит) в информационном сообщении, включающем, в том числе, все виды служебных данных, характеризующих сообщение.
Исходя из приведенного определения, следует отметить, что с точки зрения количества информации, содержащейся в сообщении, избыточность является характеристикой той части сообщения, исключение которой из общего объема данных не уменьшает количества информации в сообщении.
Таким образом, математический аспект сокращения избыточности заключается в определении ее доли в сообщении и последующей минимизации объема сообщения при сохранении количества информации в данном объеме.
Математическое содержание задачи сжатия данных заключается:
-
В представлении сообщения совокупностью существенных выборок (кодовых слов) с помощью оператора представления, реализуемого преобразователем.
-
В восстановлении сообщения по совокупности существенных выборок (кодовых слов) без потерь или с требуемой верностью воспроизведения оператором восстановления, реализуемым обратным преобразователем.
В общем случае применение оператора восстановления может быть не обязательным, так как в каждом конкретном случае представление сжатого сообщения определяется требованиями получателя информации и выбранным методом сжатия данных.
Эффективность сжатия характеризуется степенью минимизации объема сообщения. Числовой мерой сжатия является коэффициент сжатия. Обозначим Iv - объем данных на входе преобразователя, реализующего алгоритм обработки данных с целью сокращения избыточности, а Iv min – объем данных на выходе преобразователя. Тогда коэффициент сжатия К может быть найден из следующего выражения
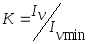
Коэффициент сжатия определяется отношением исходного объема данных на входе преобразователя к объему данных, полученных в результате выполнения операции сжатия.
Коэффициент сжатия является числовой характеристикой методов сжатия данных.
Рассмотрим первую часть задачи сжатия данных - представление сообщения преобразователем.
Система передачи
информации со сжатием (кодек) представлена
на рисунке.





Входной
с
Входной преобразователь
Кодовая таблица




Канал
В
Обратная кодовая таблица
Обратный преобразователь ыходной
ыходной
сигнал s’(n) g(n)



Входной сигнал системы цифровой передачи информации представляет собой последовательность отсчетов, выраженных дискретной величиной, принадлежащей фиксированному алфавиту возможных значений. Обозначим входной сигнал последовательностью отсчетов s(0), s(1), s(2), …,s(n). Эти отсчеты могут быть объединены в блоки. Входной преобразователь преобразует эту последовательность в другую, g(n), причем функция преобразования может как иметь однозначную обратную ей функцию (в этом случае производится преобразование кодированием без потерь), так и не иметь (в этом случае следует говорить о передаче с потерями). Входной преобразователь производит такое изменение статистических свойств сигнала, при котором следующий блок – кодовая таблица – обеспечивает максимальное сокращение битового потока, передаваемого в канал связи. Разработка кодека сводится к правильному выбору кодовой таблицы и функции преобразования, которые были бы оптимальны по отношению к принятой модели входного воздействия.
В процессе проектирования должны быть решены два вопроса:
1) Какими свойствами должен обладать входной сигнал кодовой таблицы g(n), чтобы оказалось возможным создать таблицу, обеспечивающую в среднем минимальное количество бит на отсчет входного сигнала.
2) Какое преобразование должен производить входной преобразователь с учетом свойств входного сигнала s(n), чтобы преобразованный сигнал g(n) имел свойства, обозначенные в п. 1).
Рассмотрим простейшую модель кодека, не имеющую ни входного, ни выходного преобразователя, и состоящую из кодирующей и декодирующей таблиц, т. е. s(n) = g(n). Пусть входной сигнал является изображением, которое представлено совокупностью отсчетов яркостей его элементов. При этом каждое из значений s(i) принадлежит алфавиту конечного объема А = {s1, s2, …,sN}. При квантовании на 256 уровней этот объем N равен 256. Будем считать, что вероятности появления отсчетов яркости p(si) постоянны и известны для всех i [0,…,255). При подаче каждого входного символа на кодовую таблицу, она генерирует код длиной в Кi бит, причем длина этого кода может быть различной для различных символов. При подаче всей входной последовательности, содержащей большое количество символов, происходит усреднение этих длин, причем средняя длина кодового слова может быть определена как

В случае, если для любого i длина Кi = К, т.е. кодирование ведется кодом постоянной длины, имеем
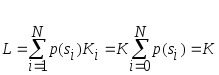
Именно значение средней длины кодового слова и определяет величину передаваемого потока данных.
В материалах лекции
3 было показано, что передача данных от
источника возможна со средней длиной
кодового слова L
![]() H,
где H
– энтропия источника, или величина его
информационного содержания. Видно, что
энтропия определяет нижнюю границу
длины кодового слова. Следовательно,
выбор модели сигнала, генерируемого
источником, и алгоритмов преобразования
исходного сигнала представляется важной
задачей, результатом решения которой
является минимизация энтропии сообщения.
Так при кодировании отсчетов яркости
изображения (N
= 256), приняв
их равновероятными, получим максимальное
значение энтропии Н
= 8 бит/отсчет.
В реальном изображении распределение
вероятностей яркостей точек изображения
далеко от равномерного. Элементы со
“средними” значениями яркостей боле
вероятны, чем очень темные или светлые.
Соответственно меньше и значение
энтропии, составляющее около 7. Если же
учитывать корреляционные связи между
отдельными элементами, использовать
межкадровую разность и т. п., можно
существенно уменьшить величину энтропии.
Но в любом случае средняя длина кодового
слова не может быть меньше энтропии.
H,
где H
– энтропия источника, или величина его
информационного содержания. Видно, что
энтропия определяет нижнюю границу
длины кодового слова. Следовательно,
выбор модели сигнала, генерируемого
источником, и алгоритмов преобразования
исходного сигнала представляется важной
задачей, результатом решения которой
является минимизация энтропии сообщения.
Так при кодировании отсчетов яркости
изображения (N
= 256), приняв
их равновероятными, получим максимальное
значение энтропии Н
= 8 бит/отсчет.
В реальном изображении распределение
вероятностей яркостей точек изображения
далеко от равномерного. Элементы со
“средними” значениями яркостей боле
вероятны, чем очень темные или светлые.
Соответственно меньше и значение
энтропии, составляющее около 7. Если же
учитывать корреляционные связи между
отдельными элементами, использовать
межкадровую разность и т. п., можно
существенно уменьшить величину энтропии.
Но в любом случае средняя длина кодового
слова не может быть меньше энтропии.
Рассмотрим некоторые варианты классификации методов сжатии данных. Классификация методов сжатия данных представляется важной стороной анализа эффективности методов сжатия, поскольку предоставляет разработчику аппаратуры телекоммуникационных систем возможность оптимального выбора метода обработки в условиях конкретной задачи. Развитие технологии производства микропроцессорной техники, элементной базы преобразования и обработки данных привело к совершенствованию телекоммуникационных технологий, а применение цифровой техники способствовало широкому применению существующих и разработке новых методов сжатия информации. Следует отметить, что стремление дать всеобъемлющую классификацию методов сжатия является довольно сложной задачей, поскольку приходится учитывать такие факторы, как эффективность, сложность реализации (объем математических операций), оценка качества результатов реализации метода, цена. Вариант классификации методов сжатия приведен в [3].
За основу классификации принято положение о разделении избыточности сообщения на естественную и искусственную Естественная избыточность – это избыточность конкретного алфавита символов (языка).. Искусственная избыточность – избыточность, вносимая в сообщение при использовании алгоритмов преобразования и обработки информации, кодировании символов. Естественная избыточность подразделяется на семантическую и статистическую составляющие. Статистическая избыточность, как мы уже знаем, определяется не равновероятностным распределением качественных признаков первичного алфавита символов, его корреляционными свойствами.
Классификация методов сжатия по виду информации выглядит следующим образом:
1.Посимвольное сжатие
2.Сжатие слов и словосочетаний
3. Сжатие и свертывание текста
4. Сжатие массивов чисел
5. Сжатие графической информации.
Рассмотрим первый из них. Посимвольное сжатие осуществляется применением:
- оптимального кодирования (в том числе применением кодов Хаффмана);
- блочного кодирования;
- перехода к кодированию с другим основанием кода:
с основанием 2 K равен log32/log2=5;
с основанием 3 K равен log32/log3=3.15.
Код Хаффмана подробно рассмотрен в материалах лекции 4. Напомним, что существо алгоритма кодирования кодом Хаффмана заключается в сопоставлении более длинных комбинаций кода символам текста с меньшей вероятностью появления и, обратно, коротких кодов символам текста с большей вероятностью появления.
Блочное кодирование.
Обратимся к методу блочного кодирования. Возможности метода рассмотрим на следующем примере.
Пусть имеются две буквы алфавита А и В, определяемые вероятностями появления 0,9 и 0,1 соответственно. Закодируем их в двоичном коде следующим образом: А ~ 0, B ~ 1. Средняя длина кода при этом будет равна одному биту К = 1x0,9 + 1x0,1 = 1бит/буква, а энтропия
Н = - 0,9 x log0,9 – 0,1 x log0,1 = 0,47.
Избыточность, таким образом, составляет 0,53 %.
Теперь закодируем двухбуквенные сочетания – блоки. Для этого определим перемножением совместные вероятности их появления, вычислим энтропию на символ нового алфавита и закодируем кодом Хаффмана. Результат представлен в таблице 1.
Таблица 1
|
AA |
0.81 |
0 |
------ |
------ |
0 |
|
AB |
0.09 |
1 |
0 |
------ |
10 |
|
BA |
0.09 |
1 |
1 |
0 |
110 |
|
BB |
0.01 |
1 |
1 |
1 |
111 |
Значение энтропии на символ алфавита Н = 1,41, избыточность составляет 0,59. Средняя длина кода на одну букву 0,705. Избыточность кодирования при этом снизилась до примерно 30%. Очевидным является тот факт, что с увеличением длины блоков можно сколь угодно близко подойти к оптимальному значению эффективности данного метода.
Блочное кодирование эффективно при устранении избыточности кодирования десятичных цифр. При передаче десятичных цифр двоичным кодом максимальную длину кода дают те символы вторичного алфавита, которые являются целочисленными степенями основания кода. Для передачи других цифр средняя длина кода может быть короче. Например, для передачи цифры 5 необходимо log5/log2 = 2,32 бит. Однако, это значение следует округлять до ближайшего большего значения 3. Появляется искусственная избыточность округления L`, которая составляет L` = 1 – (2,32/3) = 0,227. Избыточность округления может быть устранена применением блокового кодирования.
В таблице 2 приведены данные о средней длине кода при кодировании десятичных цифр различных порядков. Таблица 2
|
0 – 9 |
4 |
4 |
|
00 – 99 |
7 |
3,5 |
|
000- 999 |
10 |
3,3 |
Не отвлекаясь на анализ методов сжатия слов и словосочетаний, сжатия и
свертывание текста, которые в данной классификации относятся к
семантическим методам, рассмотрим метод сжатия графической
информации, основанный на кодировании нулей и единиц на основе кодовой
таблицы (см. таблицу 3). Из таблицы следует, что кодирование
производится первыми восемью позициями двоичного кода. При этом три
последних позиции используются в качестве признака градаций 5, 10 и 15
нулей. В процессе кодирования признак градации дополняется кодом числа
нулей, превышающих уровень градации.
Таблица 3
|
0 |
000 |
|
00 |
001 |
|
000 |
010 |
|
0000 |
011 |
|
00000 |
100 |
|
больше 5-ти нулей |
101 |
|
больше 10-ти нулей |
110 |
|
больше 15-ти нулей |
111 |
Примеры: код одиннадцати нулей 110000; код восемнадцати нулей 111010.
Анализ приведенной классификации алгоритмов устранения избыточности
позволяет сделать вывод, что группирующим признаком классификации методов
сжатия информации следует считать область применения. Так, например, блочное
кодирование используется в компьютерных форматах кодирования изображений
TIFF, PCX, FLI и др., кодирование методом Хаффмана, LZW – сжатие используется в
форматах GIF и TIFF и т. д. Широко используются в вычислительной среде методы
сжатия при архивации данных такими программами-упаковщиками, как WINZIP, RAR,
WINRAR, ARJ, PAK, ARC другие. Поэтому в рамках читаемого курса
остановимся на классификации, приведенной ниже [4].
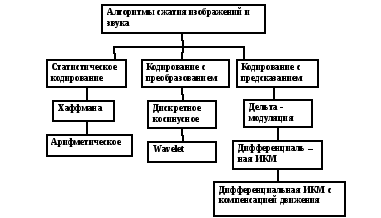
Кратко охарактеризуем методы, приведенные в данной классификации.
Статистическому кодированию (в том числе методу Хаффмана) были посвящены материалы предыдущих лекций (3 –й и 4 – й). Следует отметить, что методы статистического кодирования обеспечивают невысокую эффективность. Поэтому они, как правило, применяются в сочетании с другими методами.
Метод арифметического кодирования.
Рассмотрим несколько подробнее реализацию метода арифметического кодирования. До начала кодирования сообщению ставится в соответствие интервал [0,1]. Каждому символу в сообщении отводится интервал, ширина которого равна вероятности появления этого символа. В сумме длины всех участков составляют 1. Поступающие символы уменьшают размер интервала в соответствии с моделью вероятности символов. Результатом кодирования является число Х с высокой точностью его определения. На приемной стороне формируется исходная шкала вероятностей на интервале [0,1] и переданное число Х попадает на интервал, характеризующий символ, поступивший в кодер на данном этапе. Метод наиболее эффективен среди статистических методов. Однако использование нецелочисленной арифметики затрудняет его практическое использование. Рассмотрим реализацию метода на примере. Перед началом работы соответствующий тексту интервал есть [0; 1). При обработке очередного символа его ширина сужается за счет выделения этому символу части интервала. Hапpимеp, применим к тексту "eaii!" алфавита { a,e,i,o,u,! } модель с постоянными вероятностями, заданными в Таблице 4.
Таблица 4: Пpимеp постоянной модели для алфавита { a,e,i,o,u,! }
|
Символ |
Вероятность |
Интервал |
|
a |
0.2 |
[0.0; 0.2) |
|
e |
0.3 |
[0.2; 0.5) |
|
i |
0.1 |
[0.5; 0.6) |
|
o |
0.2 |
[0.6; 0.8) |
|
u |
0.1 |
[0.8; 0.9) |
|
! |
0.1 |
[0.9; 1.0) |
И кодировщику, и декодиpовщику известно, что в самом начале
интервал есть [0; 1). После пpосмотpа первого символа "e", кодировщик сужает интервал до [0.2; 0.5), который модель выделяет этому символу. Второй символ "a" сузит этот новый интервал до первой его пятой части, поскольку для "a" выделен фиксированный интервал [0.0; 0.2). В результате получим рабочий интервал [0.2; 0.26), т.к. предыдущий интервал имел ширину в 0.3 единицы и одна пятая от него есть 0.06. Следующему символу "i" соответствует фиксированный интервал [0.5; 0.6), что применительно к рабочему интервалу [0.2; 0.26) суживает его до интервала [0.23, 0.236). Продолжая в том же духе, имеем:
В начале [0.0; 1.0 ) После пpосмотpа "e" [0.2; 0.5 ) -"-"-"- "a" [0.2; 0.26 ) -"-"-"- "i" [0.23; 0.236 ) -"-"-"- "i" [0.233; 0.2336) -"-"-"- "!" [0.23354; 0.2336)
Предположим, что все что декодиpовщик знает о тексте, это конечный интервал [0.23354; 0.2336). Он сразу же понимает, что первый закодированный символ есть "e", т.к. итоговый интервал целиком лежит в интервале, выделенном моделью этому символу согласно Таблице 4. Теперь повторим действия кодировщика: Сначала:[0.0;1.0) После пpосмотpа "e" [0.2; 0.5)
Отсюда ясно, что второй символ - это "a", поскольку это приведет к интервалу [0.2; 0.26), который полностью вмещает итоговый интервал [0.23354; 0.2336). Продолжая работать таким же образом, декодиpовщик извлечет весь текст.