

Поз_сис_сч
.pdf1
Позиционные системы счисления
§1. Перевод числа из десятичной системы счисления в систему счисления с произвольным основанием
Произвольное (n+1)-разрядное целое число может быть представлено в системе счисления с основанием p в виде:
Здесь значащие цифры могут принимать значения Для нас общепринятым значением p является p = 10. Мы проводим все арифметические операции (сложение, умножение) в десятичной системе счисления.
Электронную вычислительную машину гораздо легче сделать, если она будет выполнять арифметические операции в двоичной (бинарной) системе счисления. Это, очевидно, так как для восприятия двоичного числа (бита – binary digit) необходимо только два состояния (например: наличие и отсутствие сигнала), что легче всего реализовать.
Но в то же время чтение информации в двоичной системе счисления, то есть последовательностей нулей и единиц, неудобно для восприятия человеком. Поэтому в качестве компромисса выбирается 16-ричная (hex – гексагональная), так как поскольку 24 = 16, то 4 битам (двоичным разрядам) соответствует одно шестнадцатеричное.
Задание 1: перевести десятичное число n равное год рождения + месяц рождения + день рождения в системы счисления с основаниями p равными 2, 3, 4, 5, 6, 7, 8, 9, 16 и для оснований p = 3, p = 7, p =8, p = 16 сделать проверку.
Пример выполнения задания:
Пусть дата рождения 15 июня 2001 года. Тогда n = 2001 + 6 + 15 = 2022.
Решение:
Поскольку числа 2, 4, 8, 16 – это последовательные степени 2, то эти примеры можно выполнить вместе. Начинать удобнее с основания p = 16. Делим последовательно исходное число и поучающиеся в результате целочисленного деления остатки на p, до тех пор, пока частное не обратится в ноль. Остатки от деления и образуют искомое представление числа.
2022 |
16 |
|
|
|
|
|
|
|
|
|
|
|
16 |
|
|
|
16 |
|
|
|
|
||||
|
|
|
|
|
|
|
||||||
126 |
|
16 |
||||||||||
|
|
|
|
|
|
|||||||
42 |
|
|
|
|
|
|
||||||
|
|
|
|
7 |
||||||||
112 |
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|||||
32 |
|
|
|
|
|
|
|
0 |
||||
|
|
|
0 |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
||||||||
|
|
|
||||||||||
|
14 |
|
|
|||||||||
102 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
7 |
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
||
96 |
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
6
.
Окончательно, выписываем остатки в обратном порядке 7E6 (2022 =7E616), с учётом того, что шестнадцатеричная цифра обозначается буквой E (1410 = E16).

2
Проверка: 7 162 + 14 161 + 6 160 = 1792 + 224 + 6 = 2022.
Для перевода в двоичную систему счисления удобно пользоваться представлением 16-ричных чисел от 0 до F (F16 = 1510) в двоичной системе, где одному 16-ричному числу соответствует одна тетрада (4 бита). 7 = 01112, 14 =11102, 6 = 01102. Тогда:
2022 = 0111111001102.
Для перевода в восьмеричную систему воспользуемся тем, что 23 = 8, то есть трём битам соответствует одна восьмеричная цифра. Поскольку при первом делении на основание определяем младший разряд числа, то биты следует отсчитывать с правого конца. Тогда: 1102 = 68, 1002 = 48, 1112 = 78, 0112 = 38.
2022 = 37468.
Проверка: 3 83 + 7 82 + 4 81 + 6 80 = 1536 + 448 + 32 + 6 = 2022.
Для перевода в четверичную систему воспользуемся тем, что 22 = 4, то есть 2 битам соответствует 1 четверичная цифра. Поскольку при первом делении на основание определяем младший разряд числа, то биты следует отсчитывать с правого конца (0111111001102 – подчёркнуты разряды, соответствующие нечётным четверичным числам).
Тогда: 102 = 24, 012 = 14, 102 = 24, 112 = 34, 112 = 34, 012 = 14.
2022 = 1332124.
Проверка: 1 45 + 3 44 + 3 43 + 2 42 + 1 41 + 2 40 = 1024 + 768 + 192 + 32 + 4 + 2 = 2022.
Видно, что с уменьшением основания число разрядов увеличивается.
Перевод в системы счисления p =3, p =5, p = 6, p = 7, p = 9 выполнить аналогично тому, как приведено в примере для p = 16.
§2.Числа Фибоначчи
Числа Фибоначчи – последовательность чисел, получаемых по рекуррентной формуле
Где обычно принимают F1 =1, F2 = 1. Следующее число ряда равно сумме двух предыдущих.
n |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
Fn |
1 |
1 |
2 |
3 |
5 |
8 |
13 |
21 |
34 |
55 |
89 |
144 |
233 |
377 |
610 |
987 |
1597 |
Число в системе Фибоначчи записывается в двоичном (бинарном коде) виде:
где an = {0 1}, значащие цифры, принимающие значение 0 или 1.
3
Задание 2: перевести десятичное число n равное год рождения + месяц рождения + день рождения в систему счисления Фибоначчи. Пусть, как и в предыдущем задании, исходное число
2022.
Находим число меньшее исходного числа и наиболее близкое к нему. Это 1597. Вычитаем 1597 из исходного. 2022 – 1597 = 425. Для 425 наиболее близкое меньшее число из ряда Фибоначчи 377.
425 – 377 = 48. И так далее: 48 – 34 =14; 14 – 13 =1.
В итоге: 2022 = 1597 + 377 + 34 + 13 + 1. Разложение исходного числа на числа Фибоначчи.
2022 = 1001000010100001f. Где в позиции (2, 7, 9, 14, 17 – отсчёт с правого края) соответствующие числам Фибоначчи должны быть вписаны 1. Но поскольку вначале ряда Фибоначчи подряд две единицы, то для записи числа одна из них лишняя, и мы номера позиций уменьшаем на 1. В итоге единицы следует вписать в позиции 1, 6, 8, 13, 16.
Отметим, что система Фибоначчи является избыточной в том смысле, что для некоторых чисел существует несколько представлений, так как 011f = 001f + 010f = 100f (следующее равно сумме двух предыдущих). Но, если потребовать чтобы в записи числа не было двух единиц подряд (каждый раз пользоваться указанным соотношением), то каждое число может быть представлено только единственным способом.
Арифметические операции требуют отдельного изучения, поэтому чтобы их произвести следует перевести исходные числа в 10-ную систему счисления произвести необходимые операции, а затем результат снова перевести в код Фибоначчи. Эта система может быть использована для шифрования чисел.
Непозиционные системы счисления
§3. Код Грея (самостоятельно)
Задание 3: перевести десятичное число n равное год рождения + месяц рождения + день рождения в код Грея.
§4. Сжатие данных. Архиваторы
При сжатии данных существует два различных подхода. Сжатие без потерь, что характерно для текстовой, звуковой информации, и с потерями, что характерно для графики и видео. Во втором случае после сжатия мы не можем восстановить исходную информацию точно. Мы будем разбирать сжатие без потери информации, которое заключается в её перекодировании так, чтобы она занимала меньший объём. В первую очередь это связано с тем, что при кодировании информации (например: текстовой в коде ASCII или Unicode) возникает избыточность. То есть кодирование данных большим числом битов чем это необходимо.
В схеме на рис 1. Представлено прохождение сигналов в компьютере. Это может быть обмен данными между жёстким диском и внешним накопителем. Данные, которые необходимо переслать сначала обрабатывает программа «моделировщик». Она формирует модель, по которой затем программа «кодировщик» создаёт выходной поток данных. Эти данные вместе с моделью передаются по каналу связи (проводам, оптоволоконному кабелю, воздуху) принимающему устройству. Эти данные декодируются по соответствующей модели, и мы получаем в приёмнике исходные данные.

4
Источник |
|
Моделировщик |
|
Кодировщик |
Канал |
Декодировщик |
|
Приёмник |
данных |
|
|
|
данных |
||||
|
|
|
|
связи |
|
|
||
|
|
|
|
|
|
|
|
|
Рис. 1.
Само сжатие требует затрат машинного времени процессора (проигрыш), но зато, если удастся сократить объём кода данных, то их можно передать за более короткое время и для их хранения требуется меньше памяти (выигрыш). Как правило, чем более сложные алгоритмы сжатия и больший объём вычислений, тем лучше сжатие.
К основным видам сжатия без потерь относят:
Статическое сжатие. В этом случае модель известна и «моделировщик» по существу не требуется. Оно реализовано в алгоритме RLE (run length encoding), что означает кодирование отрезками.
Полуадаптивное сжатие. Сначала «моделировщик» формирует модель исходных данных, а затем «кодировщик» по этой модели кодирует данные. Представителями данного вида являются алгоритм Лемпеля-Зива – кодирование со словарём, и алгоритм Хаффмана, по которому для заданного текста строится модель в виде графа (дерева). Приёмнику закодированная информация передаётся вместе с моделью.
Адаптивное сжатие. В этом случае «кодировщик» не ждёт пока «моделировщиком» будет создана модель данных, а работает с ним синхронно. Пример: арифметическое кодирование.
Более подробно разберём алгоритм Хаффмана, поскольку он представляет иерархическую структуру данных, характерную для хранения данных на внешних накопителях (дискетах, жёстких дисках).
Один из первых алгоритмов эффективного кодирования информации был предложен Д. А. Хаффманом в 1952 году. Идея алгоритма состоит в следующем: зная вероятности символов в сообщении, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов.
Свойства алгоритма: а) символам с большей вероятностью (которые встречаются в тексте часто) ставятся в соответствие более короткие коды, и наоборот; б) коды Хаффмана обладают свойством префиксности (то есть ни одно кодовое слово не является префиксом другого), что позволяет однозначно их декодировать.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н- дерево).
Символы входного алфавита образуют список свободных узлов (листов). Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в исходное (сжимаемое) сообщение.
1)Предлагается листы упорядочить в порядке их убывания слева направо. Выбираются два свободных узла дерева с наименьшими весами (крайние правые), они считаются потомками.
5
2)Создается их родитель с весом, равным их суммарному весу.
3)Родитель добавляется в список свободных узлов, в порядке убывания весов (если есть с таким же весом, то его следует ставить среди них на крайнее справа место), а два его потомка удаляются из этого списка (мысленно).
4)Одной дуге, входящей в родителя, ставится в соответствие бит 1, другой — бит 0.
Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева (корневым узлом).
После того, как построим «дерево» для каждого символа (листа «дерева») укажем путь. Путь – последовательность дуг (кода дуги 0 или 1), начинающаяся от корневого узла. Этот путь и есть код символа для последующего кодирования. Закодировав сообщение мы можем определить коэффициент сжатия kсж = Vсж/Vисх. Где Vисх это объём исходного текста в битах равный числу символов умноженных на 8 (8 бит – размер кода в системе ACSII), а Vсж объём сжатого текста равному сумме произведений количества вхождений символа в текст на длину его кода по дереву Хаффмана (количеству дуг от корневого узла до листа).
Также рассчитать количество информации содержащейся в тексте по формуле Шеннона:
Где n – число разных символов в тексте с учётом пробела, pi – вероятность вхождения символа в сообщение.
Задание 4. Для заданного текста построить дерево Хаффмана. Определить коэффициент сжатия и количество информации по формуле Шеннона. Закодировать первое слово текста. В качестве исходного текста выбрать скороговорку, содержащую не менее 30 символов. Скороговорки выбираются, потому что в них есть часто встречающиеся символы для небольшого фрагмента текста.
Пример выполнения задания.
Выберем скороговорку: Карл у Клары украл кораллы, а Клара у Карла украла кларнет.
Рассмотрим работу «моделировщика».
А) Вычислим количество вхождений каждой буквы в текст. Данные представим в виде таблицы.
символы |
к |
а |
р |
л |
пробел |
у |
ы |
о |
н |
е |
т |
|
||||||||||||||||||||||
вхождения |
8 |
|
12 |
|
8 |
|
9 |
|
10 |
|
4 |
|
2 |
|
2 |
|
1 |
|
1 |
|
1 |
|
57 |
|||||||||||
частоты |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Расположим буквы в таблице порядке убывания частот.
символы |
а |
пробел |
л |
к |
р |
у |
ы |
о |
н |
е |
т |
|
вхождения |
12 |
10 |
9 |
8 |
8 |
4 |
2 |
1 |
1 |
1 |
1 |
57 |
Б) Построим граф в виде дерева Хаффмана. Из каждого узла выходит по одной дуге (ветви), а в каждый узел входит две дуги. Данный граф отражает иерархическую структуру данных. В корневом узле получим наследуемую сумму равную сумме символов в тексте с учётом пробелов.
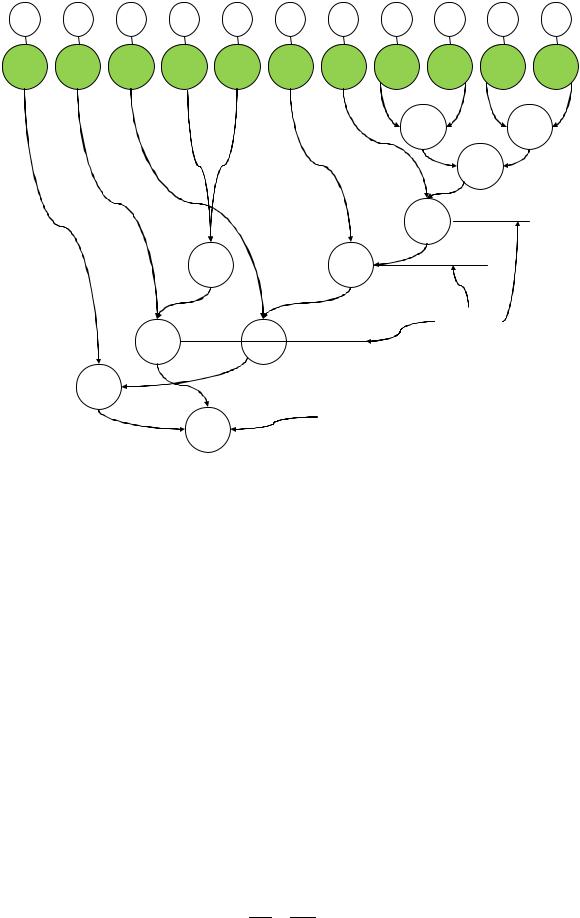
6
а |
|
л |
|
к |
р |
у |
ы |
о |
|
н |
е |
т |
12 |
10 |
9 |
|
8 |
8 |
4 |
2 |
1 |
|
1 |
1 |
1 |
|
|
|
|
|
|
|
1 |
0 |
|
1 |
|
0 |
|
|
|
|
|
|
|
|
1 |
|
|
||
|
|
|
|
|
|
|
|
2 |
|
|
2 |
|
|
|
1 |
|
|
|
|
|
|
|
|
||
|
|
|
1 |
0 |
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|||
|
|
|
|
|
|
|
|
|
4 |
|
0 |
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|
|
|
16 |
|
|
10 |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
уровни |
|
|
|
|
|
|
26 |
|
|
19 |
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
31 |
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
57 |
|
|
Корневой узел |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В) С помощью графа закодируем каждый символ (лист). По окончании построения графа подпишем каждую ветвь: левые ветви 1, а правые ветви 0 (необязательно все левые 1, а правые 0, можно чередовать). Для каждого символа укажем путь, начиная от корневого узла. Последовательность нулей и единиц, стоящих у соответствующих ветвей и будет являться кодом данного символа.
Символы |
а |
пробел |
л |
к |
р |
у |
ы |
о |
н |
е |
т |
|
Вхождения ni |
12 |
10 |
9 |
8 |
8 |
4 |
2 |
1 |
1 |
1 |
1 |
57 |
Код |
11 |
01 |
101 |
001 |
000 |
1001 |
10001 |
1000010 |
1000011 |
1000001 |
1000000 |
|
Хаффмана |
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Длина кода |
2 |
2 |
3 |
3 |
3 |
4 |
5 |
7 |
7 |
7 |
7 |
|
в битах li |
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
ni li |
24 |
20 |
27 |
24 |
24 |
16 |
10 |
7 |
7 |
7 |
7 |
173 |
Из таблицы видно, что ни один код не является началом другого, то есть построенный код является префиксным. Также видим, что чем чаще встречается код в тексте, тем более короткий код он получает.
Кодировщик будет кодировать текст в соответствии с деревом:
К |
а |
р |
л |
|
у |
к |
|
001 |
11 |
000 |
101 |
01 |
1001 |
001 |
и так далее. |
Объём исходного текста равен числу символов умноженных на длину кода в системе кодирования ASCII, и равной 8 битам. Vисх = 57 8 = 456 бит. Объём сжатого текста без учёта модели Vсж = 173 бит.

7
Вычислим количество информации, содержащееся в тексте:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
= –(–0,473 – 0,441 – 0,420 – 2 0,398 – 0,269 – 0,170 – 4 0,102) = 2,977 бита.
Вообще говоря, 3 битами можно закодировать 23 = 8 символов. У нас же 11 символов и требуется 4 бита, но с учётом того, что символы встречаются разное количество раз это число можно уменьшить.