

2.3. Статистическая обработка результатов прямых равноточных наблюдений (определений)
Все измерения в метрологии делятся на прямые и косвенные.
При прямых непосредственных измерениях числовое значение измеряемой величины х получают непосредственным сравнением этой величины с эталоном (например, массы предмета при взвешивании на чашечных весах – с массой разновесок, объема раствора – с проградуированной шкалой бюретки и т. п.). Обычно результаты таких измерений получают сразу из показаний измерительного прибора.
Результат каждого прямого измерения включает случайную погрешность, которая зависит от большого числа случайных факторов.
Если отклонения, вызванные случайными факторами, сравнимы по абсолютному значению с чувствительностью прибора, то они обнаруживаются приборами, и при n измерениях одной и той же величины получаются результаты x1, x2, xi, xn, которые могут отличаться друг от друга в пределах чувствительности данных измерений.
В описание результатов, полученных при параллельных (replicate) измерениях (определениях), следует включать следующие характеристики: число измерений, среднее арифметическое, стандартное отклонение, границы доверительного интервала и, если известно, истинное значение, а также оценку границ систематической погрешности.
Число измерений (number of observations, n) – общее число полученных данных в серии, объем выборки (sample size). Это число необходимо указывать всегда. В случае, если рассматривается генеральная совокупность, используют обозначение N.
Число степеней свободы (degrees of freedom, f) – статистическая величина, показывающая число переменных, которые могут быть присвоены произвольно при характеристике выборки; в наиболее простом случае, когда имеют n измерений (определений) и один исследуемый параметр (среднее значение) – f = n – 1.
Уровень доверительной вероятности (confidence level), или доверительная вероятность, – вероятность того, что ожидаемая величина исследуемого параметра лежит внутри некоторого интервала (P = 1 – α). Доверительная вероятность (Р) – доля случаев, в которых среднее (х) при данном числе определений будет лежать в определенных пределах. Доверительная вероятность связана с двусторонней – верхней и нижней – границей разброса среднего значения выборки. С точки зре- ния математической статистики надежность полученного результата тем выше, чем больше доверительная вероятность. Как правило, поль- зуются доверительной вероятностью Р, равной 0,95, или двухсигмовым критерием (2σ), но в особо важных случаях принимают Р = 0,99 – критерий 3σ. Доверительная вероятность может быть выражена и в процентах.
Комплементарная величина α известна как уровень значимости (significance level). Уровень значимости α = (1 – Р) – максимальная вероятность того, что погрешность превзойдет некое предельное (критическое) значение (+Δхкр), т. е. такое значение, что появление этой погрешности можно рассматривать как следствие значимой (неслучайной) причины. В разных литературных источниках уровень значимости обозначается по-разному: α, β.
Среднее
арифметическое, средняя величина
(arithmetic
mean, average,
![]() )
– сумма всех значений серии (выборки)
наблюдений, деленная на число наблюдений:
)
– сумма всех значений серии (выборки)
наблюдений, деленная на число наблюдений:
![]() (2.13)
(2.13)
Во всех процессах определения суммы (здесь и далее, если это не оговорено особо) пределы суммирования рассматриваются от 1 до n.
Отклонение (deviation, d) – разность между случайной величиной и арифметическим средним выборки, к которой она принадлежит:
![]() (2.14)
(2.14)
Размах (выборки) (range, R) – разность между наибольшей и наименьшей из наблюдаемых величин в выборке:
R = xmax – хmin. (2.15)
Этот параметр особенно удобен для малых выборок (n < 10) как альтернативная мера дисперсии.
Стандартное отклонение (standard deviation) оценивается как положительный квадратный корень величины, получаемой при делении суммы квадратов разностей всех элементов выборки и среднего этой выборки на число степеней свободы (в простейшем случае – число измерений минус единица). Выражается выборочное стандартное отклонение (estimated standard deviation, S) следующей формулой:
![]() (2.16)
(2.16)
Относительное стандартное отклонение (relative standard deviation, Sr) – стандартное отклонение, деленное на среднее выборки:
![]() (2.17)
(2.17)
Относительное стандартное отклонение, выраженное в процентах (percentage standard deviation, Sr (%)), получают умножением величины относительного стандартного отклонения на 100.
Рекомендуется при описании результатов использовать относительное стандартное отклонение, не выраженное в процентах, во избежание путаницы в том случае, когда результаты также выражены в процентах. Термин коэффициент вариации (coefficient of variation) вместо термина относительное стандартное отклонение использовать не рекомендуется.
Дисперсия
(variance,
![]() )
– это квадрат стандартного отклонения,
выражающийся формулой
)
– это квадрат стандартного отклонения,
выражающийся формулой
![]() (2.18)
(2.18)
При оценке воспроизводимости полученных результатов вычисляют также дисперсию среднего (выборки) по формуле
![]() (2.19)
(2.19)
и
стандартное отклонение
среднего (![]() ):
):
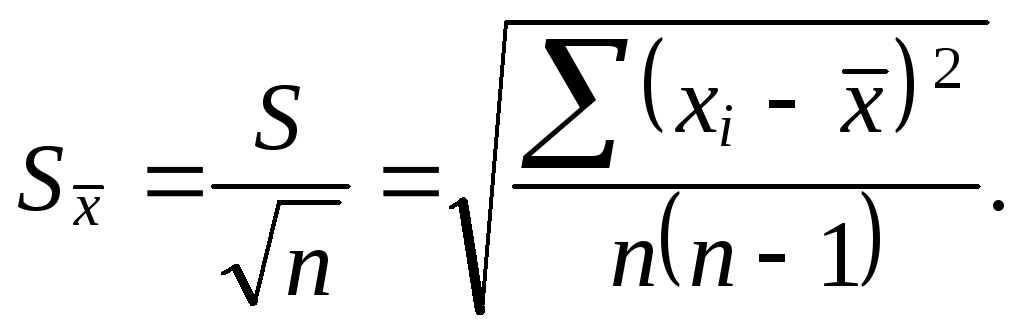 (2.20)
(2.20)
Для обозначения стандартного отклонения среднего в англоязычной литературе используется термин population standard deviation, или стандартная погрешность (standard error), с символом «σ».
Оценка
правильности результата измерения
(анализа). После того,
как осуществлена проверка грубых
погрешностей (в случае отдельных
подозрительных измеренных значений) и
их исключение, производят оценку границ
доверительного интервала (С),
доверительного интервала
![]() и при необходимости – оценку правильности
результата.
и при необходимости – оценку правильности
результата.
Границы доверительного интервала (confidence levels about the mean) – симметричные границы доверительного интервала (+С) для оценки среднего, в который с доверительной вероятностью (Р) попадает математическое ожидание (среднее генеральной совокупности). Численное значение С рассчитывают по уравнению
![]() (2.21)
(2.21)
или
С = tP,j Si, (2.22)
где tP, j – табличное значение t-критерия Стьюдента.
Обычно для расчета границ доверительного интервала пользуются значением P, равным 0,95, но при ответственных измерениях требуется более высокая надежность (P = 0,99).
Необходимо отметить, что если при отработке методики выполняют n параллельных измерений, а методика анализа в дальнейшем предусматривает выдачу результатов из m параллельных измерений (обычно n ≥ 10, m = 2–3), то границы доверительного интервала для рядовых анализов следует рассчитывать по формуле
![]() (2.23)
(2.23)
а не по формулам (2.21) и (2.22) (где S – стандартное отклонение для выборки из n опытов). В противном случае значение С рядового анализа окажется слишком заниженным.
Доверительный
интервал
(confidence
interval)
описывается как
![]() .
Если воспроизводимость измеренных
значений (результатов наблюдений,
определений) характеризуют стандартным
отклонением, то результат (измерения,
анализа) характеризуют доверительным
интервалом. Доверительный интервал
ограничивает область, внутри которой
при отсутствии систематических
погрешностей находится истинное значение
результата (измерения, анализа) с заранее
заданной доверительной вероятностьюР:
.
Если воспроизводимость измеренных
значений (результатов наблюдений,
определений) характеризуют стандартным
отклонением, то результат (измерения,
анализа) характеризуют доверительным
интервалом. Доверительный интервал
ограничивает область, внутри которой
при отсутствии систематических
погрешностей находится истинное значение
результата (измерения, анализа) с заранее
заданной доверительной вероятностьюР:
![]() (2.24)
(2.24)
![]() (2.25)
(2.25)
![]() (2.26)
(2.26)
![]() (2.27)
(2.27)
Из уравнений (2.25–2.27) следует, что значение доверительного интервала зависит от объема выборки, т. е. от числа проведенных опытов: с уменьшением числа измерений увеличивается доверительный интервал (при той же доверительной вероятности) или при заданном доверительном интервале уменьшается надежность измерений.
Значимость
систематической погрешности
характеризует меру
правильности результатов определений.
О значимости систематической погрешности,
т. е. правильности результата анализа,
судят в зависимости от того, попадает
ли истинное значение определяемой
величины в установленный доверительный
интервал или же находится вне его. Если
![]() ,
то можно говорить о значимой систематической
погрешности (∆хс),
интервальное значение которой заключено
в пределах:
,
то можно говорить о значимой систематической
погрешности (∆хс),
интервальное значение которой заключено
в пределах:
![]() (2.28)
(2.28)
В этом случае необходимо выяснить причину появления систематической погрешности. Задача освобождения результатов измерений от систематических погрешностей требует глубокого анализа всей совокупности данных измерений.
Для обнаружения и исключения систематических погрешностей широко применяют также регрессионный и корреляционный анализы.