

Сборник проектов Питер
.pdfОдним из вариантов решения подобной проблемы является разбиение исходной области пласта на множество областей меньшего размера и выделение кластеров внутри каждой из них. При этом внутри каждой такой области имеет смысл сохранять только центры масс выделенных кластеров, не учитывая в дальнейшем исходные точки. На основе подобной информации можно будет построить наглядную модель, произведя повторную кластеризацию (на этот раз для всей области целиком), но используя в качестве исходных данных найденные в ходе предыдущего шага «ключевые» точки.
В первую очередь опишем, каким образом производится разбиение исходной области.
Было решено разделить область на одинаковые параллелепипеды, имеющие фиксированные параметры – длину, ширину и высоту. Выделение кластеров и расчет «ключевых» точек (центров масс кластеров) будут выполняться в каждом из них независимо друг от друга. Для обеспечения гибкости построения окончательных кластеров решено определить такие параметры, как шаг между параллелепипедами по оси X (по длине пласта) и шаг по оси Y (по ширине). Таким образом, параллелепипеды могут как находиться друг от друга на заданном расстоянии, не охватывая некоторые участки исходной области, так и накладываться друг на друга. Логично, что во втором случае количество «ключевых» точек по завершении просмотра всех параллелепипедов будет больше (будет больше и число самих параллелепипедов).
При проведении окончательной кластеризации, когда «ключевые» точки уже определены, необходимо выбрать призабойную область, точки которой не будут учитываться при дальнейших построениях. О необходимости выделения такой зоны уже было сказано в разделе 3. Определив параметры (длину и ширину) области вокруг забоя, можно переходить к завершающему этапу, выделяя окончательные кластеры и строя модель трещины.
Блок-схема описанного алгоритма приведена на рисунке 4.1.
Методы иерархической кластеризации будут применяться как при выделении кластеров внутри параллелепипедов, так и на окончательном этапе, при определении геометрии трещин. Наиболее важные вопросы, сопутствующие иерархической кластеризации, – выбор метрик для вычисления расстояний между объектами и расстояний между кластерами, а также вопрос определения оптимального числа кластеров на основе построенного разбиения.
4.2. Способы определения оптимального количества кластеров
4.2.1. Подход с использованием «жизненных циклов»
Одним из распространенных подходов к определению оптимального числа кластеров является метод, основанный на вычислении «жизненных циклов»
(«lifetimes») кластеров [8].
51

Представим, что некоторый кластер был создан объединением двух объектов, находящихся на расстоянии d1 друг от друга. Следующий кластер был создан на основе объектов, имеющих между собой дистанцию d2, большую, чем d1, но при этом минимальную среди остальных дистанций. Тогда «жизненным циклом» первого кластера называют величину, равную (d2-d1).
Суть метода заключается в нахождении на иерархическом дереве кластеров максимального «жизненного цикла». Количество кластеров, существующих одновременно в течение него, и является оптимальным. При этом величиной порога для «среза» кластерного дерева может быть любое значение из найденного «жизненного цикла».
Пример дендрограммы с указанием «жизненных циклов» некоторых кластеров приведен на рисунке 4.2. На рисунке 4.3 представлен результат кластеризации.
Рисунок 4.2 – Пример дендрограммы с указанием «жизненных циклов» некоторых кластеров
Из рисунка 4.2 видно, что наибольший жизненный цикл имеет кластер, образованный вблизи отметки «2». Данный «lifetime» обозначен как L2, поскольку в течение данного жизненного цикла имеет место наличие двух кластеров.
В качестве порога логично взять середину «жизненного цикла», хотя в принципе можно взять и любое другое значение. Таким образом, оптимальным количеством кластеров в данном случае является число 2.
52

Рисунок 4.3 – Результат кластеризации с использованием метода «жизненных циклов»
Данный метод прост в реализации, однако он порождает следующий вопрос: невозможно определить «жизненный цикл» самого крупного кластера. Ведь существует вариант, что разбивать исходную область на кластеры не следует вовсе, определив все точки в один кластер?
Отчасти решением данной проблемы является введение некоторой величины, которая бы определяла, выполнить разбиение в данном конкретном случае или нет. Такой величиной может быть, например, половина высоты кластерного дерева. Если максимальный «жизненный цикл», найденный на дендрограмме, превышает это значение, то принимается решение о разбиении. В противном случае разбиение не производится.
4.2.2. Подход, основанный на определении неоднородности между связями
Данный подход использует в качестве исходных данных не высоты кластерного дерева, а значения коэффициента неоднородности.
Как упоминалось выше, каждая связь иерархического кластерного дерева получает в соответствие некоторое значение коэффициента неоднородности. Чем
53
больше это значение, тем существенней различие в кластерах, объединяемых связью. Чем меньше, тем выше сходство между кластерами [9].
Логично, что для поиска среди набора данных естественных «облаков» (кластеров) необходимо учитывать именно максимальное значение коэффициента неоднородности. Таким образом, «линию разбиения» нужно проводить на уровне, предшествующем связи с таким максимальным значением, чтобы два различных друг от друга кластера не успели объединиться в один [10].
Однако зачастую встречается такая ситуация, когда несколько связей иерархического дерева имеют достаточно большие, но при этом близкие значения коэффициента неоднородности. В этом случае имеет место множество потенциальных разбиений, выбрать среди которых оптимальное непросто, а часто вовсе невозможно.
Вподобных ситуациях, когда четкого варианта разбиения нет, рекомендуется отнести весь набор исходных данных к одному кластеру.
Ниже описан алгоритм, реализуемый данным методом.
Впервую очередь, производится вычисление коэффициентов неоднородности для каждой связи иерархического дерева. При вычислении коэффициентов решено учитывать все связи, лежащие ниже текущей (для которой производится расчет). Таким образом, глубина расчета в данном случае является максимальной.
Далее выбираются две связи с наибольшими значениями коэффициента, и вычисляется разница между ними.
Если эта разница превышает заданную пороговую величину, то принимается решение о разбиении на кластеры. «Линия отсечения» проводится на дендрограмме между уровнем с максимальным значением коэффициента и ближайшим снизу уровнем иерархии.
Впротивном случае разбиение не производится, и все данные определяются в единый кластер.
Особенностью данного подхода, как и в предыдущем случае, является необходимость исследователя вносить в алгоритм величину максимально допустимой разницы между значениями коэффициентов. Кроме того, метод имеет высокую трудоемкость, т.к. расчет коэффициентов неоднородности производится для каждой из связей. К достоинствам данного метода можно отнести простоту его реализации.
4.2.3.Подход, основанный на вычислении внутрикластерных
имежкластерных расстояний
Особенность предыдущих методов, как уже было сказано, связана с необходимостью выбора исследователем определенных критериев. Тем не менее, существуют алгоритмы, не требующие от аналитика предварительной настройки. Опишем ниже один из таких методов.
54
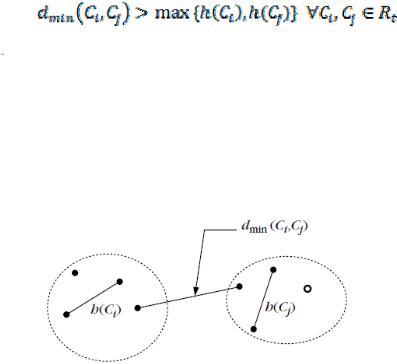
Данный алгоритм называют «внутренним», т.к. в расчет принимается только структура и характеристики исходного набора данных. В соответствии с этим методом, окончательное разбиение Rt должно удовлетворять следующему условию (4.1):
, |
(4.1) |
где  – минимальное расстояние между парой объектов из кластеров Ci и Cj;
– минимальное расстояние между парой объектов из кластеров Ci и Cj;  – максимальное из расстояний среди объектов одного кластера.
– максимальное из расстояний среди объектов одного кластера.
Иначе говоря, при окончательном разбиении различие между каждой парой кластеров должно быть больше, чем «самоподобие» каждого из них [11].
Пример разбиения исходной области на два кластера, для которых выполняется описанное условие, приведен на рисунке 4.4.
Рисунок 4.4 – Пример разбиения, удовлетворяющий условию останова
Для того чтобы определить подобное разбиение, требуется просмотреть все возможные разбиения иерархического дерева. Их количество равно (m-1), где m – число объектов исходного набора. Таким образом, на больших объемах данных применение данного метода может вызвать серьезные затруднения, связанные с высокой трудоемкостью.
Отчасти проблему можно решить, если рассматривать только N последних разбиений, т.е. ситуации с количеством кластеров, равным N, N-1, …, 2, 1. Это позволит уменьшить время определения окончательного разбиения, не теряя при этом важной информации. Однако в этом случае на долю исследователя вновь выпадает определения числа N.
Решено реализовать в разрабатываемом алгоритме пространственной фильтрации все три описанных выше метода, предоставив окончательный выбор конечному пользователю.
55

5. Разработка приложения визуализации гидравлического разрыва пласта
5.1. Структурное описание разработки
Приведем краткое описание структурной схемы разработанного приложения. Главная форма приложения представляет собой основное окно для работы
пользователя. Здесь располагается меню, позволяющее выбрать одно из четырех направлений работы: работа с файлами моделей трещины, интерполяция исходных данных, фильтрация и, наконец, визуализация. Кроме того, именно на главной форме находятся средства визуализации – графические объекты, предназначенные для отображения моделей трещины ГРП.
Для начала работы необходимо произвести импорт файлов, содержащих исходные данные. Форма импорта позволяет пользователю выбрать любое число файлов, а также просматривать текущий набор исходных данных в любой момент времени.
Сформировав набор исходных данных, пользователь получает возможность выполнить пространственную фильтрацию и построить модель трещины ГРП. Формы настройки фильтрации и визуализации позволяют производить гибкую настройку параметров соответствующих алгоритмов.
Кроме того, на основании исходного набора может быть произведена интерполяция с целью увеличения числа точек и заполнения интервалов между слоями.
Построенные модели пользователь может сохранять и использовать в дальнейшем. Для этого служат методы создания, открытия и сохранения файлов, содержащих наборы «ключевых» точек. Взаимодействие с пользователем при выполнении данных действий осуществляется посредством стандартных диалоговых окон среды MATLAB.
Главная форма приложения
|
Работа с файлами |
|
|
|
|
Интерполяция |
|
Пространственная |
|
|
|
Визуализация |
||||||
|
моделей трещины |
|
|
исходных данных |
|
|
|
|
фильтрация |
|
|
|
модели |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Создание файла |
|
|
|
|
Форма выбора |
|
|
|
|
Форма импорта |
|
Форма настройки |
||
|
|
|
|
|
|
|||||||||||||
|
|
|
|
Открытие |
|
|
|
|
выходного файла |
|
|
|
|
исходных файлов |
|
визуализации |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Форма настройки |
|
|
|||
|
|
|
|
файла |
|
|
|
|
|
|
|
|
|
|
Модуль |
|||
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
Сохранение |
|
|
|
|
|
|
|
|
|
фильтрации |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
Модуль |
|
|
|
|
|
визуализации |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
файла |
|
|
|
|
интерполяции |
|
|
|
|
Модуль |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
фильтрации |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
Рисунок 5.1 – Структурная схема разрабатываемой системы |
|
|
|||||||||||
56
Описанная структура позволит пользователю получать доступ ко всем модулям и формам приложения непосредственно из главного меню, а выделение тематических разделов облегчит навигацию внутри приложения.
Структурная схема системы, построенная на основе описанных выше модулей и форм, приведена на рисунке 5.1.
5.2. Краткое описание интерфейса приложения
Основными элементами главной формы приложения являются меню операций, панель инструментов и два графических объекта, предназначенных для визуализации моделей трещин ГРП. Наличие двух графиков обусловлено тем, что зачастую требуется сравнить результаты, полученные с использованием различных параметров алгоритма фильтрации.
Вид главной формы приложения приведен на рисунке 5.2. Укрупненное изображение главного меню и панели инструментов приведено на рисунке 5.3.
Рисунок 5.2 – Главное окно приложения
Рисунок 5.3 – Укрупненное изображение главного меню и панели инструментов
57
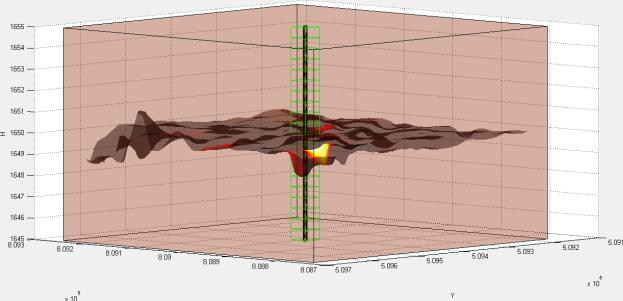
5.3. Пример визуализации трещины ГРП
Пример модели трещины гидроразрыва, построенной с использованием разработанных алгоритма и программного комплекса, приведен на рисунке 5.4.
Рисунок 5.4 – Модель трещины гидроразрыва
Заключение
Знание геометрии трещины, возникающей при гидравлическом разрыве пласта, позволяет специалистам правильно спланировать ряд мероприятий по работе со скважиной. Однако построение модели трещины ГРП является сложной задачей, и существующие системы сейсмического мониторинга зачастую не справляются с ней.
Одним из методов, позволяющим производить обработку микросейсмических данных для построения модели трещины ГРП, является пространственная фильтрация.
В данной работе было проведено детальное исследование предметной области, выявлены подходы к фильтрации сейсмических данных. Были рассмотрены методы кластерного анализа данных и определены достоинства и недостатки каждого из них.
Разработан алгоритм пространственной фильтрации, основанный на методах иерархической кластеризации. В процессе разработки неоднократно приходилось иметь дело с проблемами, не имеющими универсальных решений, что определило исследовательский характер работы. Одной из таких проблем стал вопрос определения оптимального числа кластеров в наборе данных.
Были рассмотрены, реализованы и протестированы три метода, основанные на различных критериях оптимальности. Особенность двух из них заключается в том, что они позволяют конечному пользователю настраивать «строгость» фильтрации, т.е.
58
стимулировать алгоритм либо к выделению кластеров, либо, наоборот, к отнесению всех данных в одну группу.
Однако выбор метода для выделения кластеров и настройка «строгости» фильтрации – не единственные доступные пользователю опции. Разработанный алгоритм имеет большое количество входных параметров, позволяющих производить его гибкую настройку.
Наиболее «удачным» методом с точки зрения применимости в задаче определения трещины ГРП был выбран метод «жизненных циклов». В целом, результаты, полученные с использованием данного метода, совпадают с представлением о пространственном расположении трещины.
Программные модули алгоритма реализованы с помощью среды разработки MATLAB. Произведено тестирование алгоритма на различных объемах исходных данных, сформированы оценки трудоемкости для каждого из трех вариантов реализации.
Разработан программный комплекс, предоставляющий пользователю возможность фильтрации сейсмических данных и визуализации модели трещины, а также широкий спектр настроек параметров алгоритмов. Наличие двух графических окон, а также набора специальных инструментов, таких как синхронное вращение графиков, позволяет пользователю приложения сравнивать построенные модели трещин ГРП.
Таким образом, в полном объеме решены все поставленные задачи, достигнута поставленная цель.
Разработанный продукт рекомендуется использовать для определения геометрии трещины, возникающей в ходе ГРП, на основе данных, прошедших предварительную фильтрацию (например, частотно-временную).
В заключение, сделаем вывод относительно дальнейших перспектив пространственной фильтрации.
При разработке алгоритма были использованы методы кластеризации как одного из направлений интеллектуального анализа данных. Однако, технология data mining, о которой было сказано в работе, предоставляет большое количество других методов, позволяющих обнаруживать закономерности в наборах данных, многие из которых были разработаны в рамках теории искусственного интеллекта. Таким образом, для повышения точности моделей трещины ГРП имеет смысл рассмотреть эти методы и, в случае применимости их к данной задаче, добавить их реализацию к уже существующему алгоритму.
ЛИТЕРАТУРА:
1. Салимов О. В. Совершенствование методов проектирования и анализа результатов гидравлического разрыва пластов: Автореф. дис. … канд. техн. наук. / О. В. Салимов. –
Бугульма, 2009. – 25 с.
59
2.Чубукова И. А. Data Mining: учебное пособие. / И. А. Чубукова. – М.: Интернетуниверситет информационных технологий: БИНОМ: Лаборатория знаний, 2006. – 382 с.
3.Дюк В. А. Data Mining: учебный курс. / В. А. Дюк, А. П. Самойленко – СПб: «Питер», 2001. – 368 с.
4.Кузнецов Д. Ю. Кластерный анализ и его применение [Электронный ресурс]: учебное пособие // Ярославский педагогический вестник, 2006. – URL: http://vestnik.yspu.org/releases/uchenue_praktikam/33_4/, свободный.
5.Николенко С. И. Алгоритмы кластеризации [Электронный ресурс] // Машинное обучение – ИТМО, 2006. – URL: http://logic.pdmi.ras.ru/~sergey/teaching/ml/11-cluster.pdf,
свободный.
6.Воронцов К. В. Лекции по алгоритмам кластеризации и многомерного шкалирования
[Электронный |
ресурс] |
// |
Машинное |
обучение, |
2010. |
– |
URL: |
http://www.machinelearning.ru/wiki/images/c/ca/Voron-ML-Clustering.pdf, свободный. |
|
|
|||||
7.MATLAB: Statistics Toolbox [Электронный ресурс] / ред. Мищенко З. В. – Электрон.
дан. – М.: Центр компетенций MathWorks, 2005. – URL: http://matlab.exponenta.ru/statist/index.php, свободный.
8.Fred L. N. Combining Multiple Clusterings Using Evidence Accumulation / L. N. Fred, A. K. Jain. // IEEE Transactions on Pattern Analysis and Machine Intelligence. – 2005. – Vol. 27, No. 6. – p. 7-11.
9.Bailey M. Automated Classification and Analysis of Internet Malware / M. Bailey, J. Oberheide, J. Andersen. // Recent Advances in Intrusion Detection. – 2007. – pp. 188-194.
10.Korenius T. Hierarchical clustering of a Finnish newspaper article collection with graded relevance assessments / T. Korenius, J. Laurikkala, M. Juhola. // Information Retrieval. – 2006. – Vol. 9, No. 1. – pp. 9-38.
11.Theodoridis S. Pattern Recognition / S. Theodoridis, K. Koutroumbas. - Academic Press, Inc. USA, 2009. – 494 pp.
12.Буреева Н. Н. Многомерный статистический анализ / Н. Н. Буреева – Нижний Новгород, 2007. – 112 с.
13.Луценко Е. В. Метод когнитивной кластеризации или кластеризация на основе знаний / Е. В. Луценко, В. Е. Коржаков // Научный журнал КубГАУ. – 2011. - № 71(07). - с. 9-12.
14.Белкина В. А. Основы компьютерных технологий решения геологических задач / В. А. Белкина. – Тюмень, 2006. – 34 с.
60