

ФЕДЕРАЛЬНОЕ ГОСУДАРСВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ «МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ АГРОИНЖЕНЕРНЫЙ УНИВЕРСИТЕТ им. В.П. ГОРЯЧКИНА»
Кафедра «Ремонт и надежность машин»
Расчетная работа
по дисциплине «Ремонт и надежность машин»
на тему:
«Методика обработки отказов автотракторных двигателей»
Вариант №120
Выполнил:
студент 45 группы
факультета ТС в АПК
Левин Ю.А.
Проверил: к.т.н. Чепурин А.В.
Москва 2012
Методика обработки полной информации
Рассмотрим методику обработки полной информации по показателям надежности на примере доремонтного ресурса двигателя типа CМД. Информацию обрабатывают в следующем порядке:
1. Составление сводной таблицы информации в порядке возрастания показателя надежности.
|
Номер двигателя |
Доремонтный ресурс |
Номер двигателя |
Доремонтный ресурс |
Номер двигателя |
Доремонтный ресурс |
Номер двигателя |
Доремонтный ресурс |
|
1 |
1200 |
8 |
1480 |
15 |
1780 |
22 |
2000 |
|
2 |
1220 |
9 |
1510 |
16 |
1800 |
23 |
2020 |
|
3 |
1260 |
10 |
1518 |
17 |
1850 |
24 |
2100 |
|
4 |
1310 |
11 |
1590 |
18 |
1870 |
25 |
2150 |
|
5 |
1330 |
12 |
1600 |
19 |
1900 |
26 |
2340 |
|
6 |
1420 |
13 |
1620 |
20 |
1950 |
27 |
2380 |
|
7 |
1430 |
14 |
1690 |
21 |
2000 |
28 |
2560 |
|
|
|
|
|
|
|
29 |
2900 |
Таблица 1. Сводная таблица по отказам показателей.
2. Составление статистического ряда исходной информации.
Для упрощения дальнейших расчетов составляют статистический ряд в том случае, когда повторность информации N>25. ЕслиN<25 статистический ряд не составляют.
В нашем примере повторность информации N=29>25 следовательно, целесообразно составить статистический ряд. При этом информацию разбивают наn-равных интервалов. Каждый из последующий должен прилегать к предыдущему без разрывов. Обычно число интервалов принимают 6…10. При увеличении их числа повышается точность расчетов, но одновременно возрастает их трудоемкость. Число интервалов статистического ряда определяется по формуле:
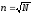 +1
+1
где +1 означает округление до ближайшего большего числа.
В данном примере:
n
=
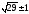 = 6
= 6
Принимаем n= 6.
Длина интервала:
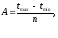
где tmax, tmin-наибольшее и наименьшее значение показателя надежности из сводной таблице информации.
В данном примере:
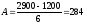 мото-ч
мото-ч
Обычно за начало первого интервала принимают наименьшее значение надежности t1 =tmin=1200 мото-ч. Статистический ряд представлен в следующем виде:
Таблица 2 – Статистический ряд
|
Интервал , мото-ч |
1200…1484 |
1484…1768 |
1768…2052 |
2052…2336 |
2336…2620 |
2620…2904 |
|
опытная частота, mi |
8 |
6 |
9 |
2 |
3 |
1 |
|
Опытная вероятность, Pi |
0,28 |
0,21 |
0,31 |
0,07 |
0,10 |
0,03 |
|
Накопленная
опытная вероятность,
|
0,28 |
0,48 |
0,79 |
0,86 |
0,97 |
1,00 |
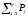
В первой строке указывают границы интервалов в единицах показателя надежности.
Во второй строке указывают число случаев (опытную частоту mi), попадающих в каждый интервал. Если точка информации попадает на границу интервалов, то в предыдущий и последующий интервалы вносят по 0,5 точки.
В третьей строке указывают опытную вероятность Рi.

где – mi опытная частота в i-ом интервале статистического ряда.
В четвертой строке указывают накопленную
опытную вероятность
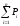 .
.
Накопленную опытную вероятность определяют суммированием опытных вероятностей интервалов статистического ряда.
Опытная вероятность в первом интервале:
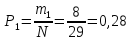
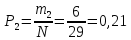
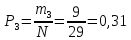
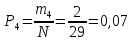

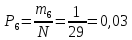
Значения заносятся в таблицу 2.