

лекции по СУБД / лекции по СУБД / СУБД_лекции (8,9)
.docРаздел 9. Механизмы, поддерживающие высокую готовность.
Лекция 16. Кластерная организация сервера баз данных
1. Определение и виды кластерных систем
2. Архитектуры хранения данных в кластерных системах
1. Определение и виды кластерных систем
Кластер – это группа вычислительных машин, которые связаны между собою и функционируют как один узел обработки информации и для конечного пользователя выглядят как один компьютер.
Рассмотрим цели кластеризации. Представим, что сервера организации перестали справляться с возложенными на них функциями. Для решения этой проблемы есть два пути.
Во-первых, можно увеличить количество серверов сообразно с количеством задач. Несомненно, это значительно повысит производительность системы в целом. Но дело в том, что загрузка корпоративных вычислительных систем носит ярко выраженный пиковый характер и до 90% времени новый дорогостоящий сервер будет загружен лишь частично (средняя загрузка приблизительно 20%), Кроме того, стоимость обслуживания информационной системы (ИС) при увеличении количества оборудования возрастает по экспоненте.
Но есть и другой выход – можно изменить сам принцип организации корпоративной информационной системы и перейти к применению серверов в кластерной конфигурации.
Создание кластерной системы практически не требует закупки дополнительного оборудования и, при правильном проектировании, способно значительно увеличить такие важные характеристики ИС, как надежность, производительность и масштабируемость.
Кластер - это группа вычислительных машин, которые связаны между собою и функционируют как один узел обработки информации и для конечного пользователя выглядят как один компьютер.
Базовая схема кластера отображена на Рис.1.
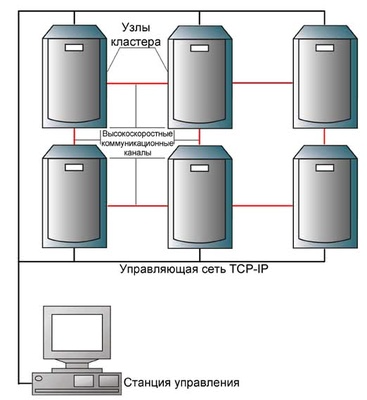
Рис.1. Базовая схема кластера
Отдельные узлы (сервера) объединены при помощи высокопроизводительной шины (например Fibre Channel или InfiniBand) и управляются через обыкновенную TCP-IP сеть. Возможно создание кластеров из практически неограниченного количества серверов.
По своей функциональной классификации, кластеры могут быть поделены на три основные группы:
-
Высокопроизводительные (High Performance) кластеры (Рис. 2).
-
Кластеры высокой готовности (High - Availability) (Рис. 3).
-
Кластеры смешанного типа (Рис. 4).
Высокопроизводительные (High Performance) кластеры
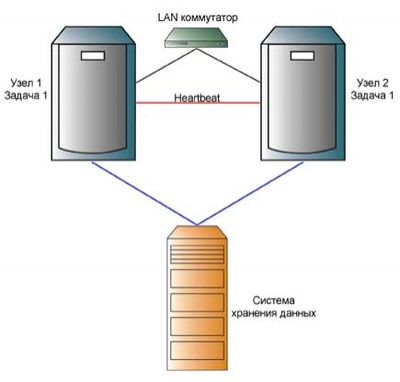
Рис.2. Высокопроизводительные (High Performance) кластеры
Такие системы предназначены в первую очередь для выполнения сложных расчетов. Они применяются для таких операций, как физическое и химическое моделирование, промышленные математические, геологические и другие задачи, рендеринг изображений, видео и звука и многих других.
Для максимальной эффективности используемое программное обеспечение должно поддерживать многопоточную работу.
Основная трудность при создании высокопроизводительных кластерных систем состоит в том, что скорость обмена данными между процессором и локальной оперативной памятью значительно превышает скорость взаимодействия между узлами. Соответственно, применение обычного дешевого Ethernet'a не оправдано и для коммутации кластерных узлов применяется специализированное оборудование стандарта Myrinet и SCI.
Кластеры высокой готовности (High - Availability).
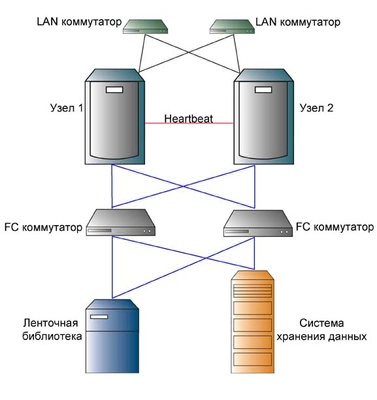
Рис. 3. Кластеры высокой готовности (High - Availability)
Эти кластеры применяются там, где стоимость возможного простоя из-за неполадок значительно превышают стоимость создания отказоустойчивой системы. В таких областях, как биллинговые и банковские системы, электронная коммерция, управление предприятием и т.д.
Особенность таких кластеров – они спроектированы таким образом, что система в целом не имеет точек отказа. Иначе говоря, отсутствуют компоненты, неполадки которых могут повлиять на работоспособность системы в целом. Для достижения этой цели не придумано ничего лучше полного дублирования всех ключевых компонентов кластера (от систем хранения данных до отдельных коммутаторов и хост – адаптеров). Кроме того, при проектировании учитывается возможность быстрой замены вышедших из строя элементов без остановки системы.
Кластеры смешанного типа.

Рис.4. Кластеры смешанного типа
Кластеры этого типа совмещают в себе черты High Performanse и High Availability систем. Узлы объединяются высокопроизводительными каналами передачи данных, все компоненты дублируются.
Такие кластеры – оптимальный вариант для использования в основных data – центрах предприятий (по параметрам надежности, производительности и расширяемости), но отличаются довольно значительной стоимостью создания и поддержки.
К кластерам смешанного типа можно отнести и системы с балансировкой нагрузки. Задача таких кластеров – обработка значительного числа клиентских запросов при использовании технологии клиент – сервер. Это применимо, например, при работе с корпоративными базами данных, поддержке HTTP и FTP серверов и т.д.
Типы реализации High Availability кластеров
На сегодняшний день на российском рынке самой большой популярностью пользуются именно High Availability решения. На возможных вариантах их реализации мы остановимся поподробнее.
Схема active-active
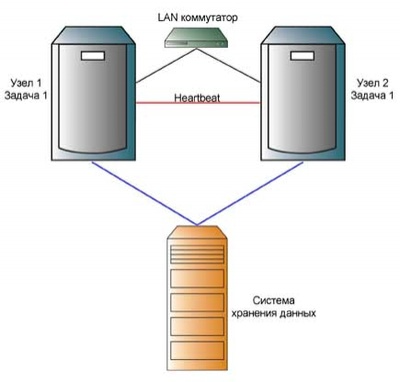
Рис. 5. Схема active-active
При такой реализации задача выполняется одновременно несколькими узлами кластера, что значительно повышает и производительность и, до некоторой степени, отказоустойчивость.
Недостаток схемы в том, что реального повышения производительности можно добиться только используя специальное, ориентированное на многопоточность, программное обеспечение.
Схема active-passive
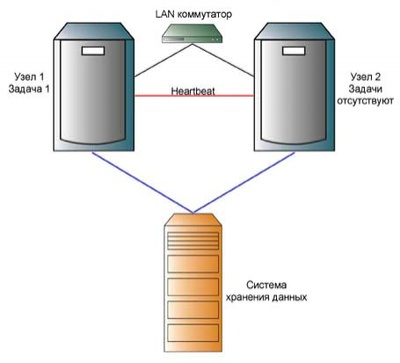
Рис. 6. Схема active-passive
Эта схема применяется в тех случаях, когда необходимо использовать отказоустойчивый кластер для поддержки приложений, для кластерной архитектуры не предназначенных. При такой схеме выполнением задач занят только один из узлов кластера. На втором узле поддерживается полная копия данных первого и при сбое главного узла второй берет на себя его функции.
Схема обеспечивает высокий уровень надежности, но может достаточно финансово затратной, так как вычислительные ресурсы второго узла постоянно не используются
Схема псевдо-активный-активный
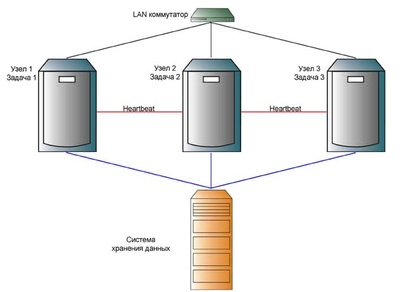
Рис. 7. Схема псевдо-активный-активный
Такая схема применяется для тех задач, выполнение которых можно разбить на несколько групп. Как правило, в рамках информационной системы предприятия это могут быть, например, бухгалтерия, склад, маркетинг и другие. При такой реализации каждый узел выполняет свою задачу, которая в случае выхода сервера из строя, переходит к другим узлам. К недостаткам этой схемы можно отнести достаточно высокую сложность реализации.
2. Архитектуры хранения данных в кластерных системах
Существует две основных схемы организации хранения данных в кластерных системах. Первый (Рис. 8), и самый частый, подразумевает подключение к кластерной системе внешних дисковых (и, при необходимости, ленточных) накопителей, соединенных в сеть (сети) хранения данных SAN.
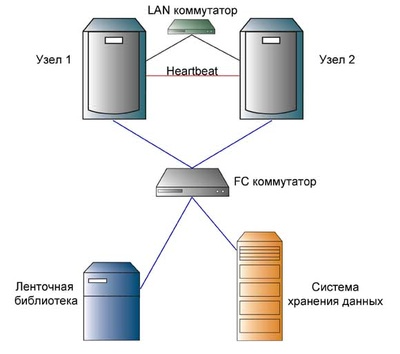
Рис. 8. Подключение к кластерной системе внешних дисковых накопителей
Это позволяет каждому узлу кластера в любой момент времени получить доступ к данным, расположенным на любом носителе. Впрочем, для этого необходимо использование специальной файловой системы, например GFS (для Linux систем). Такая архитектура часто используется в кластерах смешанного типа для получения максимально возможной производительности и надежности.
В довольно редких случаях, когда в рамках одной задачи возможно разделить данные так, чтобы некоторое количество запросов можно было обработать, используя только часть имеющихся данных, бывает целесообразно использовать раздельную схему хранения данных.
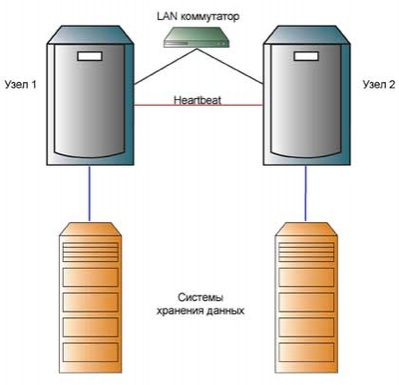
Рис. 9. Раздельную схему хранения данных
Необходимо, впрочем, учитывать, что такая архитектура приводит либо к снижению отказоустойчивости системы хранения данных, либо к дополнительным затратам на зеркалирование систем хранения.
Использование внутренних накопителей узлов крайне нежелательно по следующим причинам: недостаточная надежность встраиваемых RAID – контроллеров, затратность вычислительных ресурсов серверов на поддержку и организацию доступа к внутренним данным, сложность мониторинга и управления ресурсами хранения.