

Основы биомедицинской статистики
.pdf21
|
P T n m 2 t , |
в |
случае |
б) |
|
P T n m 2 t , где t – расчетное значе- |
|||
|
ние статистики Т; Тn+m-2 – случайная величина, |
|||
|
имеющая распределение Стьюдента с (n+m-2) сте- |
|||
|
пенями свободы |
|
|
|
t критическое одностороннее |
Критическое значение t (α; n+m-2) порядка α рас- |
|||
|
пределения Стьюдента с (n+m-2) степенями свобо- |
|||
|
ды P T n m 2 t ;n m 2 |
|
||
|
|
|
|
|
P(T≤t) двухстороннее |
Значимость P T n m 2 |
t (случай в)) |
|
|
|
|
|||
t критическое двухстороннее |
Критическое значение t (α/2; |
n+m-2) порядка α/2 |
||
|
распределения Стьюдента с (n+m-2) степенями |
|||
|
свободы |
|
|
|
|
/ 2 P T n m 2 t / 2;n m 2 |
|
||
|
|
|
|
|
Двухвыборочный t-тест с разными дисперсиями. Двухвыборочный t-тест Стьюдента (рис. 24)
используется для проверки гипотезы о равенстве средних для двух выборок данных из разных генеральных совокупностей. Эта форма t-теста предполагает несовпадение дисперсий генеральных совокупностей и обычно называется гетероскедастическим t-тестом. Если тестируется одна и та же генеральная совокупность, используется парный тест.
Рис. 24. Двухвыборочный t-тест с разными дисперсиями
Для определения тестовой величины t используется следующая формула.
|
|
|
|
|
|
|
|
|
|
t |
X |
1 X 2 |
|
||||||
|
|
|
|
|
|
|
|
(52) |
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|||
|
|
|
|
2 |
|
2 |
|||
|
1 |
2 |
|
|
|||||
|
|
|
|
n |
|
|
m |
||
где δ - гипотетическая разность средних; X1 X2 .
Так как результат вычисления обычно не бывает целым числом, значение df округляется до целого для получения порогового значения из t-таблицы. Функция Excel ТТЕСТ по возможности использует вычисленные значения без округления для вычисления значения ТТЕСТ с нецелым значением df. Из-за разницы подходов к определению степеней свободы, результаты функций ТТЕСТ и t-тест будут различаться в случае с разными дисперсиями. Следующая формула используется для вычисления степени свободы df.
Автор: доцент Андаспаева А.А.

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
22 |
|
|
|
|
|
|
|
S12 |
S22 2 |
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
df |
|
|
|
|
n |
|
m |
|
|
(53) |
|||||||
|
|
2 2 |
|
|
|
2 |
|
2 |
|
||||||||
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
S1 |
|
|
|
|
|
S2 |
|
|
|
|
|||
|
n |
|
|
m |
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
n 1 |
|
m 1 |
|
|
||||||||||
Элементы диалогового окна «Двухвыборочный t-тест с различными дисперсиями» совпадают с элементами диалогового окна «Двухвыборочный t-тест с одинаковыми дисперсиями»
Парный двухвыборочный t-тест для средних. Парный двухвыборочный t-тест Стьюдента (рис. 25) используется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные. Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента.
Рис. 25. Парный двухвыборочный t-тест для средних
Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле.
S 2 |
n S 2 |
n S 2 |
|
||
1 1 |
|
2 2 |
(54) |
||
n n |
2 |
||||
|
|
||||
|
1 |
2 |
|
|
|
Элементы диалогового окна «Парный двухвыборочный t-тест для средних» совпадают с элементами диалогового окна «Двухвыборочный t-тест с одинаковыми дисперсиями».
7 Регрессионный анализ
Уравнением регрессии Y от X называют функциональную зависимость у=f(x), а ее график – линией регрессии.
7.1Построение графиков
Excel позволяет создавать диаграммы и графики довольно приемлемого качества. Excel имеется специальное средство — Мастер диаграмм, под руководством которого пользователь проходит все четыре этапа процесса построения диаграммы или графика.
Как правило, построение графика начинают с выделения диапазона, содержащего данные, по кото-
Автор: доцент Андаспаева А.А.

23
рым он должен быть построен. Такое начало упрощает дальнейший ход построения графика. В Excel 2007 находим вкладку ВСТАВКА (рис. 28).
Рис. 28. МАСТЕР ДИАГРАММ в Excel 2007
Наиболее просто выделить диапазон исходных данных, в котором эти данные находятся в смежных рядах (столбцах или строках), — надо щелкнуть по левой верхней ячейке диапазона и затем протащить указатель мыши до правой нижней ячейки диапазона. При выделении данных, находящихся в несмежных рядах, указатель мыши перетаскивают по выделяемым рядам при нажатой клавише Ctrl. Если один из рядов данных имеет ячейку с названием, остальные выделенные ряды также должны иметь соответствующую ячейку, даже если она пустая.
Для проведения регрессионного анализа лучше всего использовать диаграмму типа Точечная (рис. 30). При ее построении Excel воспринимает первый ряд выделенного диапазона исходных данных как набор значений аргумента функций, графики которых нужно построить (один и тот же набор для всех функций). Следующие ряды воспринимаются как наборы значений самих функций (каждый ряд содержит значения одной из функций, соответствующие заданным значениям аргумента, находящимся в первом ряду выделенного диапазона).
В Excel 2007 названия осей ставятся во вкладке меню МАКЕТ (рис. 29).
Рис. 29. Настойка названий осей графика в Excel 2007
7.2Линейная функция
Функция аргумента х, имеющая вид у=ах+b, где а и b – некоторые заданные числа, называется линейной. Ее графиком является прямая линия, которая наклонена к оси х под углом φ, тангенс которого равен а и смещенная по оси у на величину b от начала координат (рис. 30).
y
|
φ |
y=ax+b |
x |
b
x
y=ax–b
Рис. 30. График линейной функции
7.3. Логарифмическая, степенная и экспоненциальная функции
Экспоненциальная функция
Автор: доцент Андаспаева А.А.

24
y=a.ebx
где a и b – расчетные коэффициенты,
e – основание натурального логарифма. Логарифмическая функция
y=a.lnx+b
где a и b – расчетные коэффициенты,
ln – функция натурального логарифма.
Логарифмическая функция является обратной к экспоненциальной функции.
Степенная функция
y=a.хb
где a и b – расчетные коэффициенты.
Графики экспоненциальной и логарифмической функций приведены на рис. 31.
y
y=a.ebx
x
y=a.lnx+b
Рис. 31. Графики экспоненциальной и логарифмической функций
Примечание
Основные статистические характеристики
Выборка – группа элементов, выбранная для исследования из всей совокупности элементов. Задача выборочного метода состоит в том, чтобы сделать правильные выводы относительно всего собрания объектов, их совокупности. Например, врач делает заключения о составе крови пациента на основе анализа ее нескольких капель.
При статистическом анализе, прежде всего, необходимо определить характеристики выборки, и важнейшей является среднее значение.
Среднее значение (Хс, М) – центра выборки, вокруг которого группируются элементы выборки.
Медиана – элемент выборки, число элементов выборки со значениями больше которого и меньше которого – равно.
Дисперсия (D) – параметр, характеризующий степень разброса элементов выборки относительного среднего значения. Чем больше Дисперсия, тем дольше отклоняются значения элементов выборки от среднего значения.
Важной характеристикой выборки является мера разброса элементов выборки от среднего значения. Такой мерой является среднее квадратическое отклонение или стан-
дартное отклонение.
Стандартное отклонение (среднее квадратическое отклонение) – параметр, ха-
рактеризующий степень разброса элементов выборки от среднего значения. Стандартное отклонение обычно обозначается буквой “σ “ (сигма).
Ошибки среднего или стандартная ошибка (m) – параметр, характеризующий сте-
пень возможного отклонения среднего значения, полученного на исследуемой ограниченной выборке, от истинного среднего значения, полученного на всей совокупности элементов.
Нормальное распределение – совокупность объектов, в которой крайние значения некоторого признака – наименьшее или наибольшее – появляются редко; чем ближе значение признака к среднему арифметическому, тем чаще оно встречается. Например, распреде-
Автор: доцент Андаспаева А.А.

25
ление пациентов по их чувствительности к воздействию любого фармакологического агента часто приближается к нормальному распределению.
Коэффициент корреляции (r) – параметр, характеризующий степень линейной взаимосвязи между двумя выборками. Коэффициент корреляции изменяется от -1 (строгая обратная линейная зависимость) до 1 (строгая прямая пропорциональная зависимость). При значении 0 линейной зависимости между двумя выборками нет.
Случайное событие – событие, которое может произойти или не произойти без видимой закономерности.
Случайная величина – величина, принимающая различные значения без видимой закономерности, т.е. случайным образом.
Вероятность (p) – параметр, характеризующий частоту появления случайного события. Вероятность изменяется от 0 до 1, причем вероятность р=0 означает, что случайное событие никогда не происходит (невозможное событие), вероятность р=1 означает, что случайное событие происходит всегда (достоверное событие).
Уровень значимости – максимальное значение вероятности появления события, при котором событие считается практический невозможным. В медицине наибольшее распространение получил уровень значимости равный 0,05. Поэтому если вероятность, с которой интересующее событие может произойти случайным образом р < 0,05, то принято считать это событие маловероятным, и если оно все же произошло, то это не было случайным.
Критерий Стьюдента – наиболее часто используется для проверки гипотезы: «Среднее двух выборок относятся к одной и той же совокупности». Критерий позволяет найти вероятность того, что оба средних относятся к одной и той же совокупности. Если это вероятность р ниже уровня значимости (р < 0,05), то принято считать, что выборки относятся к двум разным совокупностям.
Регрессия – линейный регрессионный анализ заключается в подборе графика и соответствующего уравнения для набора наблюдений. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или более независимых переменных. Например, на степень заболеваемости человека влияют несколько факторов, включая возраст, вес и иммунный статус. Регрессия пропорционально распределяет меру заболеваемости по этим трем факторам на основе данных наблюдаемой заболеваемости. Результаты регрессии впоследствии могут быть использованы для предсказания уровня заболеваемости новой, неисследованной группы людей.
8. Демонстрационные примеры
Пример №1.
Рассмотрим две группы больных тахикардией, одна из которых (контрольная) получала традиционное лечение, другая (исследуемая) получала лечение по новой методике. Ниже приведены частоты сердечных сокращений (ЧСС) для каждой группы (ударов в минуту). А) Определить среднее значение в контрольной группе. В) Определить стандартное отклонения в контрольной группе.
Контроль |
Исследование |
162 |
135 |
156 |
126 |
144 |
115 |
137 |
140 |
125 |
121 |
145 |
112 |
151 |
130 |
Решение А).
Для определения среднего значения в контрольной группе необходимо установить табличный курсор в свободную ячейку. На панели инструментов нажать кнопку Вставка
Автор: доцент Андаспаева А.А.

26
функций (fx). В появившемся диалоговом окне выбрать категорию Статистические и функцию СРЗНАЧ, после чего нажать кнопку ОК. Затем указателем мыши ввести диапазон данных для определения среднего значения. Нажать кнопку ОК. В выбранной ячейке появится среднее значение выборки – 145,714.
Решение В).
Для определения стандартного отклонения в контрольной группе необходимо установить табличный курсор в свободную ячейку. На панели инструментов нажать кнопку Вставка функций (fx). В появившемся диалоговом окне выбрать категорию Статистические и функцию СТАНДОТКЛОН, после чего нажать кнопку ОК. Затем указателем мыши ввести диапазон данных для определения стандартного отклонения, после чего нажать кнопку ОК. В выбранной ячейке появится стандартное отклонение выборки – 12, 298.
Пример №2.
Даны значения процента содержания Na в интактных зубах у пациентов: 0,48; 0,56; 0,54; 0,57; 0,47; 0,5; 0,59; 0,6; 0,67; 0,68; 0,7; 0,69; 0,74; 0,75; 0,53; 0,58; 0,86; 0,51; 0,88; 0,6; 0,87; 0,65; 0,69; 0,71; 0,68; 0,5; 0,61; 0,76; 0,77; 0,61; 0,85; 0,59; 0,88; 0,64; 0,51; 0,86; 0,91; 0,78; 0,52; 0,49; 0,81; 0,55; 0,62; 0,63; 0,73; 0,72; 0,72; 0,66; 0,8; 0,79; 0,82; 0,84; 0,75; 0,83; 0,84; 0,83; 0,72; 0,73; 0,73; 0,62; 0,67; 0,81; 0,63; 0,84; 0,64; 0,66; 0,67; 0,67; 0,66; 0,68; 0,71; 0,76; 0,63; 0,66; 0,64; 0,66; 0,65; 0,68; 0,76; 0,78; 0,77; 0,68; 0,72; 0,73; 0,74; 0,79; 0,78; 0,77; 0,76; 0,7; 0,69; 0,72; 0,73; 0,69; 0,71; 0,68; 0,7; 0,71; 0,75; 0,69.
Определите основные статистические показатели.
Решение: В пакете анализа выберем пункт «Описательная статистика» (см. рис 22.). В появившееся диалоговое окно введем данные входного интервала (интервал ячеек А1-А100). Устанавливаем флажок Выходной интервал и вводим адрес ячейки, начиная с которой будет производиться вывод результата (например, $C$2). Адреса лучше вводить не вручную, а указывать на них левой кнопкой мыши. Обязательно устанавливаем флажок в поле Итоговая статистика, нажимаем ОК.
Результаты анализа появятся в ячейках электронной таблицы.
Пример электронной таблицы |
Таблица 15 |
Пример №3.
Исследованы данные в интактных зубах 6 пациентов до и после принятия фторированного молока. Переменные 1 – 25,1%; 24,5%; 24,8%; 25,2%; 25,3%, 24,3%. Переменные 2 – 26,7%; 25,2%.
25,6%; 26,3%. 26,5; 25,3%. Необходимо определить достоверности различий средних арифметических двух выборок.
Решение: Введем в столбец А переменные 1 и в столбец В переменные 2.
В пакете анализа выберем пункт «Парный двухвыборочный t-тест для средних» (см. рис 22.). Введем адрес интервала переменной 1 и интервала переменной 2. Установим флажок в выходной интервал и введем адрес вывода информации. Доверительная вероятность нулевой гипотезы (Альфа) устанавливается по умолчанию равной 0,05.
Автор: доцент Андаспаева А.А.

27
Рис.30. Использование Парного двухвыборочного t-теста для средних
В результате анализа получили таблицу (рис.31.).
Рис.31. Результирующее окно «Парного двухвыборочного t-теста для средних»
В ячейку F4 введем вручную формулу для вычисления относительного изменения содержания Са: =(E4—D4)/E4. Переведем результат в процентный формат, щелкнув кнопку (%) на вкладке Главная - группа команд Число – пиктограмма Процентный.
Результат расчетов показывает, что экспериментальный t – критерий (9,53, оценивается модуль значения) превышает табличное (t критическое двухстороннее) значение критерия Стьюдента (2,57), следовательно, прием фторированного молока вызвал достоверное увеличение содержание кальция в интактных зубах на 4% с вероятностью нулевой гипотезы 0,00022 (Р<0,05).
Пример №4.
Определим, достоверна ли разница в концентрации Са в интактных зубах у детей, употребляющих фторированное молоко. Введем данные для 5 детей, принимающих фторированное молоко, и семи детей, не принимающих, в ячейки электронной таблицы.
Решение: Введем в столбец А переменные 1 и в столбец В переменные 2.
В пакете анализа выберем пункт «Двухвыборочный t-тест с одинаковыми дисперсиями» (см. рис 22.). Введем адреса интервала переменной 1 и интервала переменной 2. Установим флажок в выходной интервал и введем адрес вывода информации. Доверительная вероятность нулевой гипотезы (Альфа) устанавливается по умолчанию равной 0,05.
Автор: доцент Андаспаева А.А.

28
Рис.32. Ввод данных для Двухвыборочного t - теста с одинаковыми дисперсиями
Результат анализа выводится в таблицу (рис.33).
Рис.33. Результаты расчета Двухвыборочного t - теста с одинаковыми дисперсиями
Расчеты показывают, что экспериментальный t – критерий (3,74) превышает табличное значение (2,228). Разница средних достоверна с вероятностью нулевой гипотезы Р=0,0038, cследовательно, по данным проведенного исследования можно утверждать, что при приеме детьми фторированного молока произошло увеличение концентрации Са в интактных зубах на 10% (Р<0.01).
Пример №5.
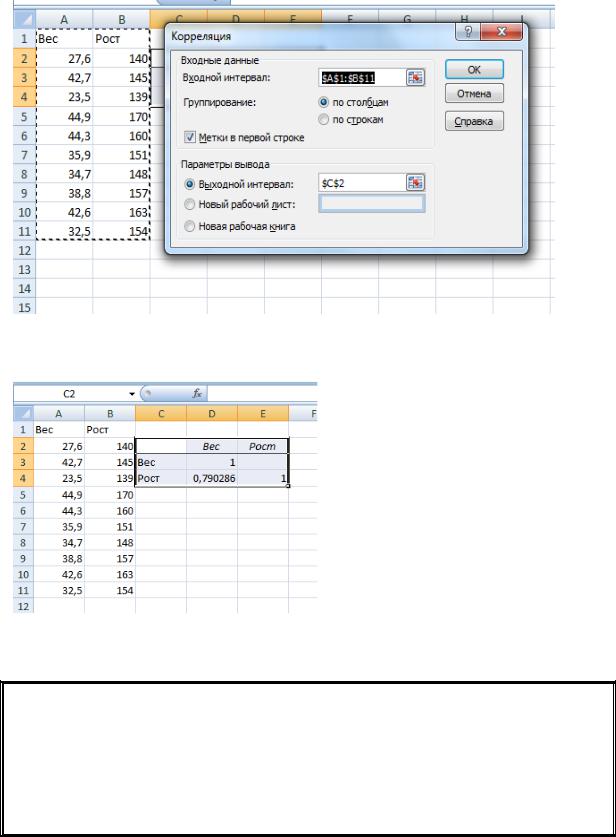
Дана выборка - Веса: 27,6; 42.7; 23.5; 44.9; 44.3; 35,9; 34,7; 38,8; 42,6; 32,5 и Роста: 140; 145; 139; 170; 160; 151; 148; 157; 163; 154 школьников школы №138 г. Алматы. Проведите корреляционный анализ.
Решение: Введем в столбец А переменные 1(Вес) и в столбец В переменные 2 (Рост) школь-
ников.
В пакете анализа выберем пункт «Корреляция» (см. рис 22.). Введем адреса интервала переменной 1 и интервала переменной 2. Установим флажок в выходной интервал и введем адрес вывода информации (см. рис.34).
Автор: доцент Андаспаева А.А.
29
Рис.34. Ввод данных для Корреляции
В результате анализа получили таблицу (рис.35.).
Рис.35. Результаты расчета Корреляции
Расчеты показывают линейную корреляцию между весом и ростом детей 0,79.
Примечание: r=-1 – строгая обратная линейная зависимость;
r=0 – линейной зависимости между двумя выборками нет;
r>\0,95\- то принято считать, что между параметрами существует практически линейная зависимость (прямая при положительном r и обратная при отрицательном r;
0,6< r<0,8 – говорят о наличии линейной связи между параметрами;
r<0,4 – обычно считают, что линейную взаимосвязь между параметрами выявить не удалось.
Пример №6.
Рассмотрим две группы больных тахикардией, одна из которых (контрольная) получала традиционное лечение, другая (исследуемая) получала лечение по новой методике. Ниже приведены частоты сердечных сокращений (ЧСС) для каждой группы (ударов в минуту). Можно ли по этим данным сделать вывод о большей эффективности нового препарата?
Автор: доцент Андаспаева А.А.
|
30 |
Контроль |
Исследование |
162 |
135 |
156 |
126 |
144 |
115 |
137 |
140 |
125 |
121 |
145 |
112 |
151 |
130 |
Задачей статистического анализа в рассматриваемом примере является сравнение данных исследуемой группы с контрольной. Сопоставляя средние значения ЧСС контрольной группы больных (145,7) и исследуемой (125,6), можно видеть, что они отличаются. Можно ли по этим данным сделать вывод о большей эффективности нового препарата?
Для оценки достоверности отличий по критерию Стьюдента принимается нулевая гипотеза, что средние выборок равны между собой. Затем вычисляется значение вероятности того, что изучаемые события (ЧСС больных в обеих выборках) произошли случайным образом. Для этого табличный курсор устанавливается в свободную ячейку. На панели инструментов необходимо нажать кнопку Вставка функций (fx). В появившемся диалоговом окне Мастер функции выбрать категорию Статистические и функцию ТТЕСТ, после чего нажать на кнопку ОК. В появившемся диалоговом окне ТТЕСТ указателем мыши ввести диапазон данных контрольной группы в поле Массив 1. В поле Массив 2 ввести диапазон данных исследуемой группы. В поле хвосты всегда вводится цифра «2» (без кавычек), в поле Тип с клавиатуры введем цифру «3».Нажать на кнопку ОК. В выбранной ячейке появится значение вероятности – 0,006295.
Поскольку величина вероятности случайного появления анализируемых выборок (0,006295) меньше уровня значимости (р=0,05), то нулевая гипотеза отвергается. Следовательно, различия между выборками не случайные и средние выборок считаются достоверно отличающимися друг от друга. Поэтому на основании применения критерия Стьюдента можно сделать вывод о большей эффективности нового препарата (р<0,05).
Пример 7.
Имеются результаты наблюдений частоты сердечных сокращений (ударов в минуту) и частоты дыхания (вдохов в минуту) у группы больных с определенной патологией:
ЧСС |
ЧД |
120 |
20 |
84 |
15 |
105 |
18 |
92 |
16 |
113 |
19 |
90 |
16 |
80 |
15 |
Необходимо определить, имеется ли взаимосвязь между частотой сердечных сокращений и частотой дыхания при исследуемой патологии.
Решение.
Для выявления степени взаимосвязи, прежде всего, необходимо ввести данные в рабочую таблицу. Для вычисления значения коэффициента корреляции между выборками, табличный курсор нужно установить в свободную ячейку. На панели инструментов необходимо нажать кнопку Вставка функции(fх). В появившемся диалоговом окне Мастер функции выбрать категорию Статистические и функцию КОРРЕЛ, после чего нажать кнопку ОК. Указателем мыши ввести диапазон данных ЧСС в поле Массив1. В поле Массив2 ввести диапазон данных ЧД. Нажать кнопку ОК. В выбранной ячейке появится значение коэффициента корреляции – 0,995493. Значение коэффициента корреляции больше чем 0,95. Значит, можно
Автор: доцент Андаспаева А.А.