

Организация ЭВМ и систем 2 курс 2 семестр / УМК_Орг_ЭВМ / Лек7_ОЭВМ
.docТема 3. Функциональная и структурная организация процессора.
Лекция 7. Повышение производительности вычислений
1. Конвейеризация вычислений в архитектуре процессора
2. Суперскалярные процессоры.
1. Конвейеризация вычислений в архитектуре процессора
Идея использования конвейера при организации вычислений заключается в следующем (рис. .1).
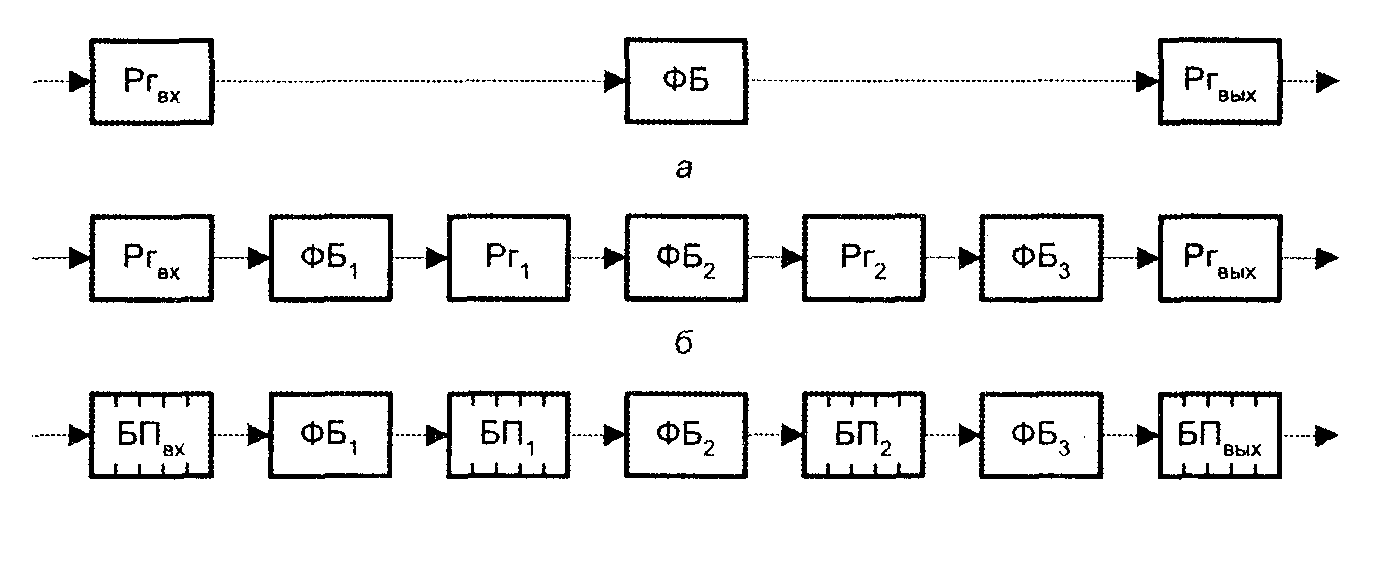
Рис. 1. Принцип работы конвейера
Исходные данные помещаются во входной регистр Ргвх, обрабатываются в функциональном блоке, а результат обработки фиксируется в выходном регистре Ргвых. Если максимальное время обработки в ФБ равно Tmax, то новые данные могут быть занесены во входной регистр Ргвх не ранее, чем спустя Ттax.
Функции, выполняемые в функциональном блоке ФБ, иогут быть разделены между тремя последовательными независимыми блоками: ФБ1, ФБ2 и ФБ3, причем так, чтобы максимальное время обработки в каждом ФБ, было одинаковым и равнялось Тmax/3. Между блоками размещаются буферные регистры Рг, предназначенные для хранения результата обработки в ФБ, на случай, если следующий за ним функциональный блок еще не готов использовать этот результат. В рассмотренной схеме данные на вход конвейера могут подаваться с интервалом Tmax/3(т.е. втрое чаще), и хотя задержка от момента поступления первой единицы данных в Ргвх до момента появления результата ее обработки на выходе Ргвых по-прежнему составляет Ттах, последующие результаты появляются на выходе Ргвых уже с интервалом Tmax/3.
На практике редко удается добиться того, чтобы задержки в каждом ФБ, были одинаковыми. Как следствие, производительность конвейера снижается, поскольку период поступления входных данных определяется максимальным временем их обработки в каждом функциональном блоке. Для устранения этого недостатка или, по крайней мере, частичной его компенсации каждый буферный регистр Рг заменяется буферной памятью БП, способной хранить множество данных и организованной по принципу FIFO – «первым вошел – первым вышел». Обработав элемент данных, ФБ заносит результат в БП извлекает из БП новый элемент данных и приступает к очередному циклу обработки, причем эта последовательность осуществляется каждым функциональным блоком независимо от других блоков.
По способу синхронизации работы ступеней конвейеры могут быть синхронными и асинхронными. Для традиционных ВМ характерны синхронные конвейеры. Связано это, прежде всего, с синхронным характером работы процессоров. Ступени конвейеров в процессоре обычно располагаются близко друг от друга, благодаря чему тракты распространения сигналов синхронизации получаются достаточно короткими и фактор «перекоса» сигналов становится не столь существенным. Асинхронные конвейеры оказываются полезными, если связь между ступенями не столь сильна, а длина сигнальных трактов между разными ступенями сильно рознится. Примером асинхронных конвейеров могут служить систолические массивы (процессоры построенные на основе БИС).
Идея конвейера команд была предложена в 1956 году академиком С. А. Лебедевым. Как известно, цикл команды представляет собой последовательность этапов. Возложив реализацию каждого из них на самостоятельное устройство и последовательно соединив такие устройства, получаем классическую схему конвейера команд. Например, цикл машинной команды состоит из шести этапов:
-
Выборка команды (ВК). Чтение очередной команды из памяти и занесение ее в регистр команды.
-
Декодирование команды (ДК). Определение кода операции и способов адресации операндов.
-
Вычисление адресов операндов (ВА). Вычисление исполнительных адресов каждого из операндов в соответствии с указанным в команде способом их адресации.
-
Выборка операндов (ВО). Извлечение операндов из памяти. Эта операция не нужна для операндов, находящихся в регистрах.
-
Исполнение команды (ИК). Исполнение указанной операции.
-
Запись результата (ЗР). Занесение результата в память.
На рис. 2 показан конвейер с шестью ступенями, соответствующими шести этапам цикла команды. В диаграмме предполагается, что каждая команда обязательно проходит все шесть ступеней, хотя этот случай не совсем типичен. Так, команда загрузки регистра не требует этапа ЗР. Кроме того, здесь принято, что все этапы могут выполняться одновременно. Без конвейеризации выполнение девяти команд заняло бы 9 * 6 = 54 единицы времени. Использование конвейера позволяет сократить время обработки до 14 единиц.
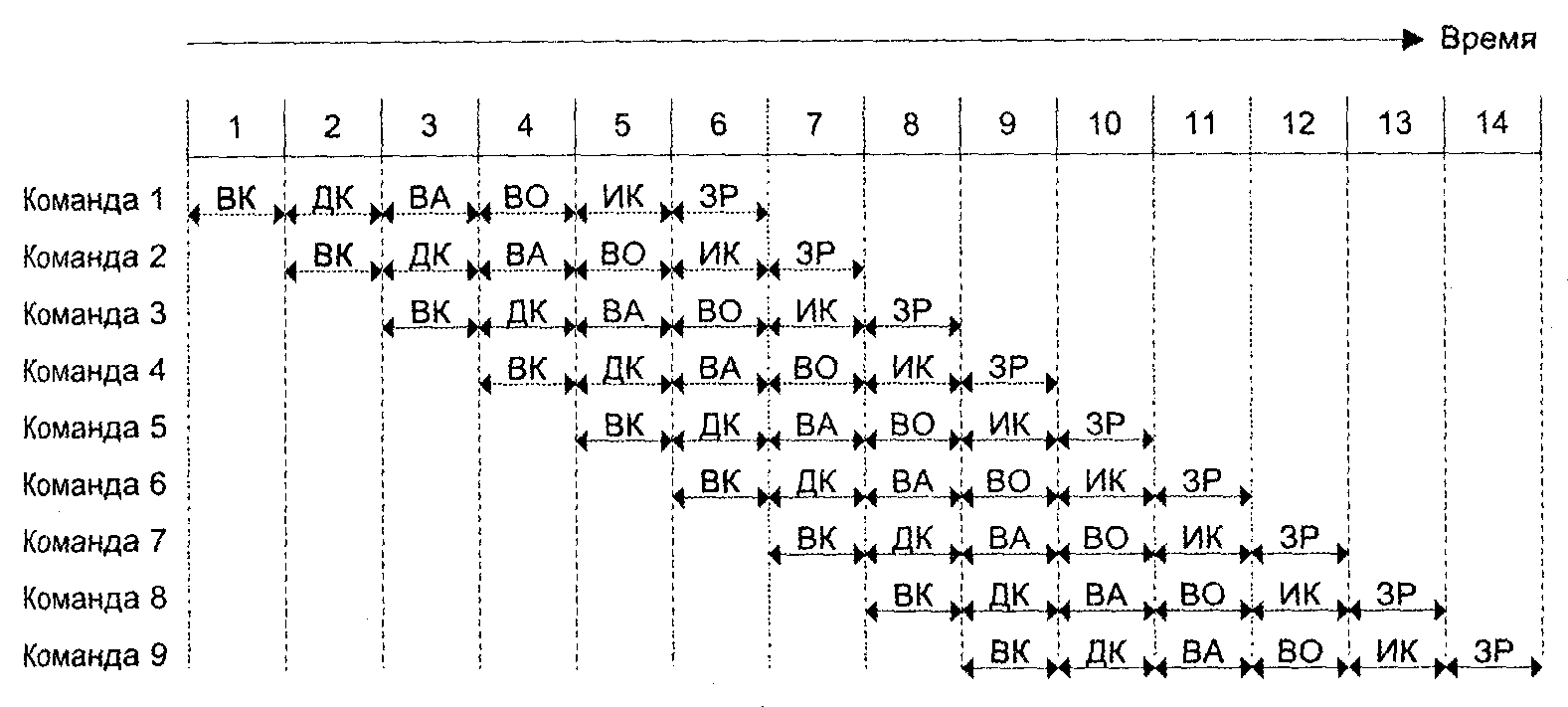
Рис. 2. Конвейерная обработка команд
Конфликты в конвейере команд
Полученное в примере число 14 характеризует лишь потенциальную производительность конвейера команд. На практике в силу возникающих в конвейере конфликтных ситуаций достичь такой производительности не удается. Конфликтные ситуации в конвейере принято обозначать термином риск, а обусловлены они могут быть тремя причинами:
попыткой нескольких команд одновременно обратиться к одному и тому же ресурсу ВМ (структурный риск);
взаимосвязью команд по данным (риск по данным);
неоднозначностью при выборке следующей команды в случае команд перехода (риск по управлению).
Структурный риск (конфликт по ресурсам) имеет место, когда несколько команд, находящихся на разных ступенях конвейера, пытаются одновременно использовать один и тот же ресурс, чаще всего – память. Так, в типовом цикле команды сразу три этапа (ВК, ВО и ЗР) связаны с обращением к памяти. Диаграмма (рис. 2) показывает, что все три обращения могут производиться одновременно, однако на практике это не всегда возможно. Подобных конфликтов частично удается избежать за счет модульного построения памяти и использования кэш-памяти. При чем кэш-память может разделяться на кэш-память команд и кэш-память данных. В целом, влияние структурного риска на производительность конвейера по сравнению с другими видами рисков сравнительно невелико.
Риск по данным, в противоположность структурному риску – типичная и регулярно возникающая ситуация. Для пояснения сущности взаимосвязи команд по данным положим, что две команды в конвейере (i и j) предусматривают обращение к одной и той же переменной х, причем команда i предшествует команде j. В общем случае между i и j ожидаемы три типа конфликтов по данным (рис. 3):
«чтение после записи» (ЧПЗ): команда j читает х до того, как команда i успела записать новое значение х, то есть j ошибочно получит старое значение x вместо нового;
«запись после чтения» (ЗПЧ): команда j записывает новое значение х до того, как команда i успела прочитать х, то есть команда i ошибочно получит новое значение х вместо старого;
«запись после записи» (ЗПЗ): команда j записывает новое значение х прежде, чем команда i успела записать в качестве х свое значение, то есть х ошибочно содержит i-e значение х вместо j-го.
Возможен и четвертый случай, когда команда j читает х прежде команды i. Этот случай не вызывает никаких конфликтов, поскольку как i, так j получат верное значение х.
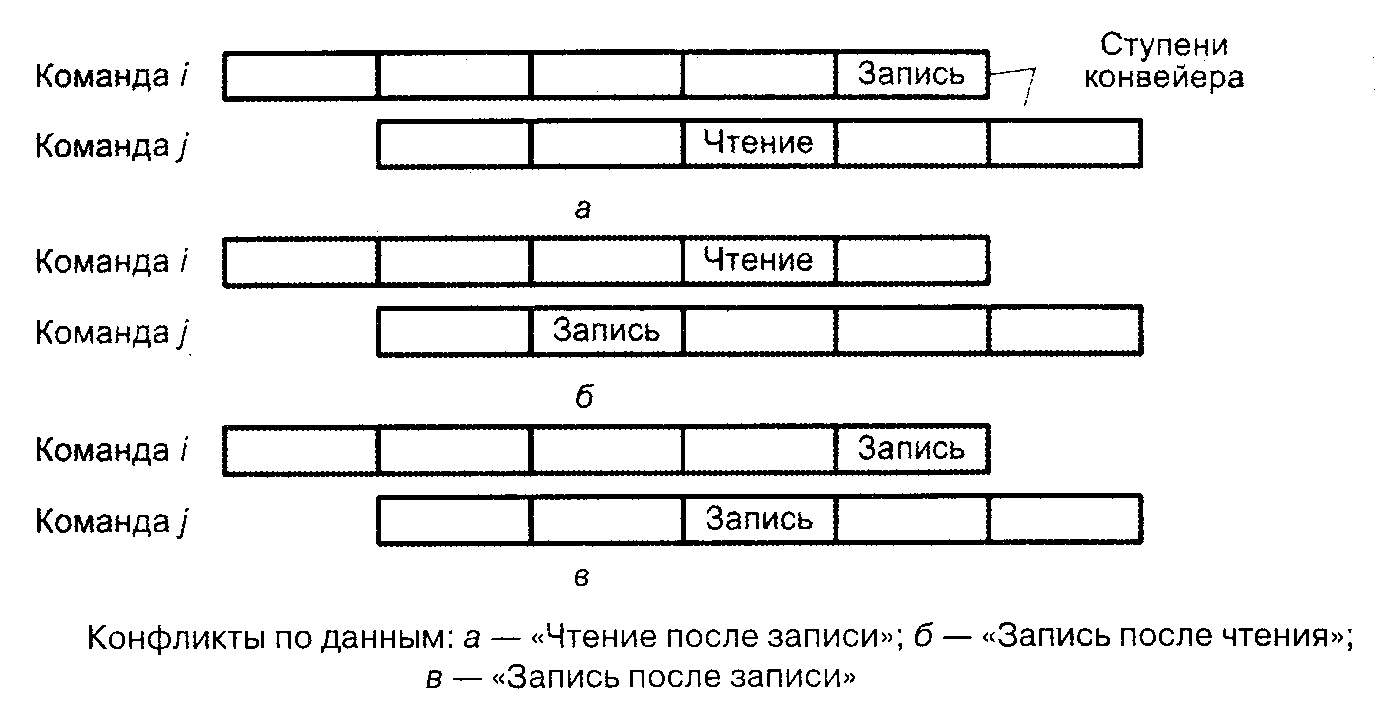
Рис. 3. Виды конфликтов в конвейере команд
Наиболее частый вид конфликтов по данным – ЧПЗ, поскольку операция чтения в цикле команды (этап ВО) предшествует операции записи (этап ЗР). По той же причине конфликты типа ЗПЧ большой проблемы не представляют.
В борьбе с конфликтами по данным выделяют два аспекта: своевременное обнаружение потенциального конфликта и его устранение. Признаком возникновения конфликта по данным между двумя командами i и j служит невыполнение хотя бы одного из трех условий Бернстейна:
для ЧПЗ: Oi I(j) = ;
для ЗПЧ: I(i) O(j) = ;
для ЗПЗ: Oi O(j) = ,
где O(k) – множество ячеек, изменяемых командой k; I(l) – множество ячеек, читаемых командой l; – операция пересечения множеств.
Соблюдение соотношений является достаточным, но не необходимым условием, поскольку в ряде случаев коллизий может и не быть.
Для борьбы с конфликтами по данным применяются как программные, так и аппаратные методы. Программные методы ориентированы на устранение самой возможности конфликтов еще на стадии компиляции программы. Оптимизирующий компилятор пытается создать такой объектный код, чтобы между командами, склонными к конфликтам, находилось достаточное количество нейтральных в этом плане команд. Если такое не удается, то между конфликтующими командами компилятор вставляет необходимое количество команд типа «Нет операции».
Фактическое разрешение конфликтов возлагается на аппаратные методы. Наиболее очевидным решением является остановка команды j на несколько тактов с тем, чтобы команда i успела завершиться или, по крайней мере, миновать ступень конвейера, вызвавшую конфликт.
Предсказание переходов является одним из наиболее эффективных способов борьбы с конфликтами по управлению. Идея заключается в том, что еще до момента выполнения команды условного перехода или сразу же после ее поступления на конвейер делается предположение о наиболее вероятном исходе такой команды (переход произойдет или не произойдет). Последующие команды подаются на конвейер в соответствии с предсказанием. Для иллюстрации рассмотрим пример (рис. 4), где команда 3 является командой условного перехода (УП).
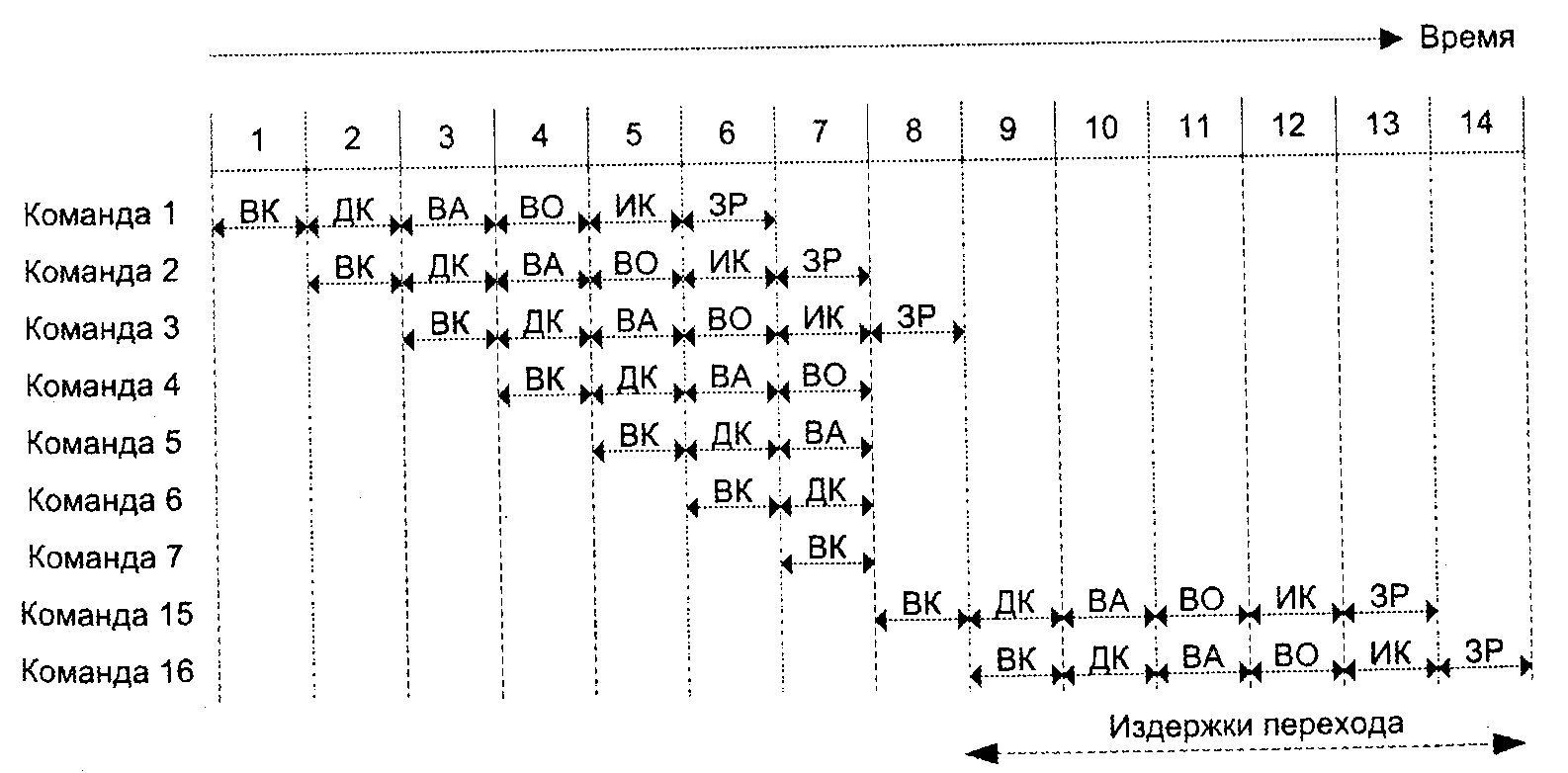
Рис. 4. Пример обнаружения конфликтов в конвейере
Пусть для команды 3 предсказано, что переход не произойдет. Тогда вслед за командой 3 на конвейер будут поданы команды 4-6 и т. д. Если предсказан переход, то после команды 3 на конвейер подаются команды 15-17, … При ошибочном предсказании конвейер необходимо вернуть к состоянию, с которого началась выборка «ненужных» команд (очистить начальные ступени конвейера), и приступить к загрузке, начиная с «правильной» точки, что по эффекту эквивалентно приостановке конвейера. Цена ошибки может оказаться достаточно высокой, но при правильных предсказаниях крупен и выигрыш — конвейер функционирует ритмично без остановок и задержек, причем выигрыш тем больше, чем выше точность предсказания. Термин «точность предсказания» характеризует процентное отношение числа правильных предсказаний к их общему количеству. В практике используется следующая оценка: чтобы снижение производительности конвейера из-за его остановок но причине конфликтов по управлению не превысило 10%, точность предсказания переходов должна быть выше 97,7%.
При классификации схем предсказания переходов обычно выделяют два подхода: статический и динамический в зависимости от того, когда и на базе какой информации делается предсказание
Статическое предсказание переходов
Статическое предсказание переходов осуществляется на основе некоторой априорной информации о подлежащей выполнению программе. Предсказание делается на этапе компиляции программы и в процессе вычислений уже не меняется. Различие между известными механизмами статического прогнозирования заключается в виде информации, используемой для предсказания. Исходная информация может быть получена двумя путями: на основе анализа кода программы или в результате ее профилирования.
Известные стратегии статического предсказания для команд УП можно классифицировать следующим образом:
переход происходит всегда (ПВ);
переход не происходит никогда (ПН);
предсказание определяется по результатам профилирования;
предсказание определяется кодом операции команды перехода;
предсказание зависит от направления перехода;
при первом выполнении команды переход имеет место всегда.
В первом из перечисленных вариантов предполагается, что каждая команда условного перехода в программе обязательно завершится переходом, и, с учетом такого предсказания, дальнейшая выборка команд производится, начиная с адреса перехода.
В основе второй стратегии лежит прямо противоположный подход: ни одна из команд условного перехода в программе никогда не завершается переходом, поэтому выборка команд продолжается в естественной последовательности.
Интуитивное представление, что обе стратегии должны приводить к верному предсказанию в среднем в 50% случаев, на практике не подтверждается. Так, по результатам тестирования, предсказание об обязательном переходе оказалось правильным в среднем для 76% команд УП.
Практика показывает, что успешность стратегии ПВ существенно зависит от характера программы и методов программирования, что, естественно, можно рассматривать как недостаток.
Схожая ситуация характерна и для стратегии ПН, где предполагается, что ни одна из команд УП в программе никогда не завершается переходом. Несмотря на схожесть с ПВ, процент правильных исходов здесь обычно ниже, особенно в программах с большим количеством циклов.
В третьем из перечисленных способов статического предсказания назначение командам УП наиболее вероятного исхода производится по результатам профилирования подлежащих выполнению программ. Под профилированием подразумевается выполнение программы при некотором эталонном наборе исходных данных, сопровождающееся сбором информации об исходах каждой команды условного перехода. Тем командам, которые чаще завершались переходом, назначается стратегия ПВ, а всем остальным — ПН. Выбор фиксируется в специальном бите кода операции. Некоторые компиляторы самостоятельно проводят профилирование программы и по его результатам устанавливают этот бит в формируемом объектном коде. При выполнении программы поведение конвейера команд определяется после выборки команды по состоянию упомянутого бита в коде операции. Основной недостаток этого образа действий связан с тем, что изменение набора исходных данных для профилирования может существенно менять поведение одних и тех же команд условного перехода.
Средняя вероятность правильного предсказания, полученная на программах тестового набора SPEC_92, составила 75%.
При предсказании на основе кода операции команды перехода для одних команд предполагается, что переход произойдет, для других — его не случится. Например, для команды перехода по переполнению логично предположить, что перехода не будет. На практике назначение разным видам команд УП наиболее вероятного исхода чаще производится по результатам профилирования программ. Эффективность предсказания зависит от характера программы. Данная стратегия приводит к успеху в среднем более чем в 75% - 86,7%.
Достаточно логичным представляется предсказание исходя из направления перехода. Если указанный в команде адрес перехода меньше содержимого счетчика команд, говорят о переходе «назад», и для такой команды назначается стратегия ПВ. Переход к адресу, превышающему адрес команды перехода, считается переходом «вперед», и такой команде назначается стратегия ПН. В основе рассматриваемого подхода лежит статистика по множеству программ, согласно которой большинство команд УП в программах используются для организации циклов, причем, как правило, переходы происходят к началу цикла (переходы «назад»). Для команд, выполняющих переход «назад», фактический переход имеет место в 85% случаев. Для переходов «вперед» эта цифра составляет 65%. Таким образом, для команд условного перехода «назад» логично принять, что переход происходит всегда. Рассматриваемую стратегию иногда называют «Переход назад происходит всегда. Эта стратегия используется в качестве вторичного механизма в схемах динамического прогнозирования переходов.
В последней из рассматриваемых статических стратегий при первом выполнении любой команды условного перехода делается предсказание, что переход обязательно будет. Предсказания на последующее выполнение команды зависят от правильности начального предсказания. Стратегию можно считать статической только частично, поскольку она однозначно определяет исход команды лишь при первом ее выполнении. Точность прогноза в соответствии с данной стратегией выше, чем у всех предшествующих. Однако, при больших объемах программ вариант практически нереализуем из-за того, что нужно отслеживать слишком много команд условного перехода.
Динамическое предсказание переходов
В динамических стратегиях решение о наиболее вероятном исходе команды УП принимается в ходе вычислений, исходя из информации о предшествующих переходах (истории переходов), собираемой в процессе выполнения программы. В целом, динамические стратегии по сравнению со статическими обеспечивают более высокую точность предсказания.
Идея динамического предсказания переходов предполагает накопление информации об исходе предшествующих команд УП. История переходов фиксируется в форме таблицы, каждый элемент которой состоит из т битов. Нужный элемент таблицы указывается с помощью k-разрядной двоичной комбинации – шаблона (pattern). Этим объясняется общепринятое название таблицы предыстории переходов – таблица истории для шаблонов (PHT, Pattern History Table).
Для описания динамических схем предсказания переходов используются модели на основе автоматов Мура, при этом содержимое элементов РНТ трактуется как информация, отображающая текущее состояние автомата.
В большинстве известных процессоров используются двухразрядные автоматы Мура, на основе счетчиков, работающих с насыщением (m= 2). Логика предсказания переходов применительно к двухразрядным счетчикам известна как алгоритм Смита. Алгоритм предполагает четыре состояния счетчика:
00 — перехода не будет (сильное предсказание);
01 — перехода не будет (слабое предсказание);
-
— переход будет (слабое предсказание);
-
— переход будет (сильное предсказание).
Логику предсказания можно описать диаграммой состояний двухразрядного автомата A3 (рис. 5).
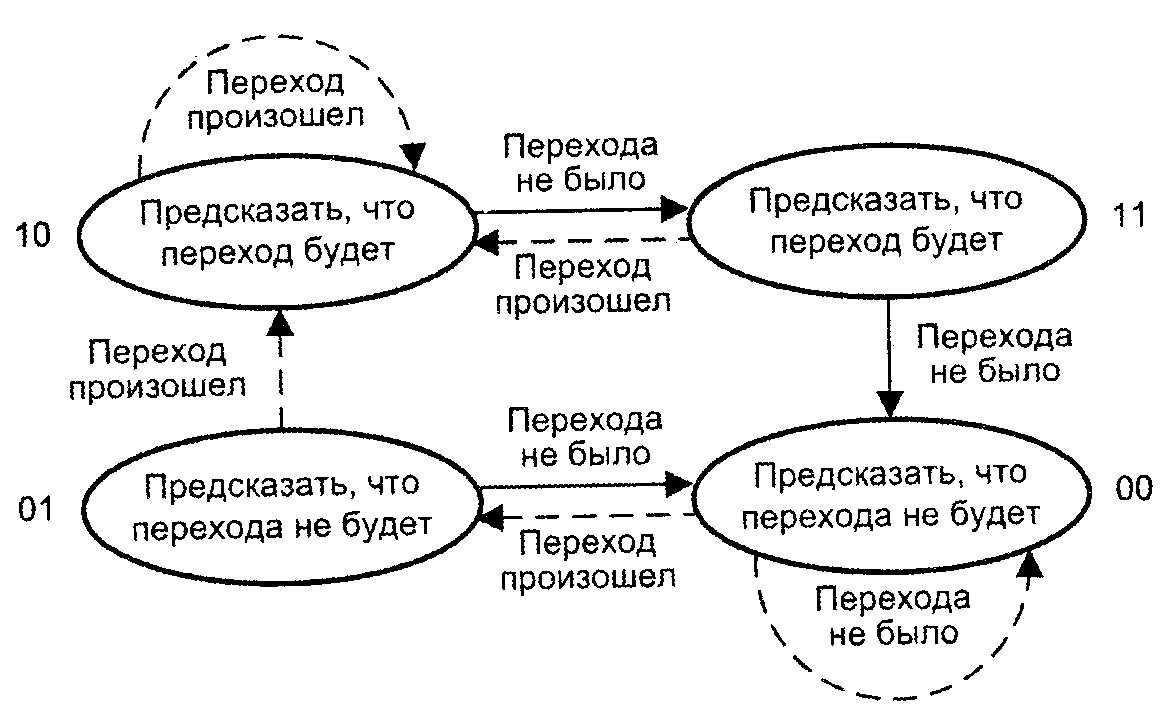
Рис. 5. Модель автомата Мура на счетчиках с насыщением
После определения способов учета истории переходов и логики предсказания необходимо остановиться на особенностях использования таблицы, в частности на том, какая информация выступает в качестве шаблона для доступа к РНТ и какого рода история фиксируется в элементах таблицы. Именно различия в способах использования РНТ определяют ту или иную стратегию предсказания. В качестве шаблонов для доступа к РНТ могут быть взяты:
адрес команды условного перехода;
регистр глобальной истории;
регистр локальной истории;
комбинация предшествующих вариантов.
Схема, где для доступа к РНТ выбран адрес команды условного перехода (содержимое счетчика команд), позволяет учитывать поведение каждой конкретной команды УП. При многократном выполнении большинства команд условного перехода наблюдается повторяемость исхода: переход либо, как правило, происходит, либо, как правило, не происходит (имеет место бимодальное распределение исходов). Индексация РНТ с помощью адреса команды УП дает возможность отделить первые от вторых и, соответственно, повысить точность предсказания. Каждой команде условного перехода в РНТ соответствует свой счетчик. Когда команда завершается переходом, содержимое счетчика увеличивается на единицу, а в противном случае – уменьшается на единицу (естественно, с соблюдением логики счета с насыщением). В качестве шаблона для поиска в РНТ служат младшие k-разрядов содержимого счетчика команд (рис. 6).
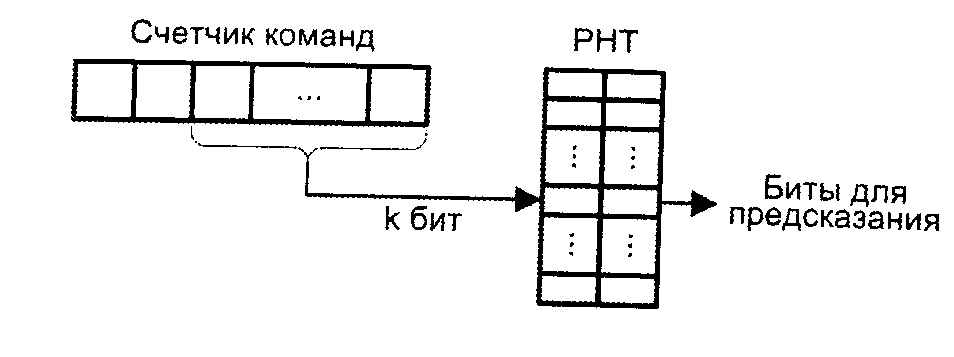
Рис. 6. Использование счетчика команд для формирования бита
предсказания перехода
При k-разрядном индексе таблица может содержать 2k элементов. Схема обеспечивает достаточно высокий процент правильных предсказаний для тех команд УП, которые в ходе вычислений выполняются многократно, например предназначены для управления циклом. В то же время в любой программе имеется достаточно много команд перехода, выполняемых лишь однократно или малое число раз. Исход для таких команд в значительной мере зависит от поведения предшествующих им команд УП, связь которых с рассматриваемой командой не столь очевидна. Иными словами, между исходами команд условного перехода в программе существует известная взаимосвязь, учет которой дает возможность повысить долю правильных предсказаний. Эта идея реализуется схемой с регистром глобальной истории.
Регистр глобальной истории (GHR, Global History Register) представляет собой l-разрядный сдвиговый регистр (рис. 7).

Рис. 7. Использование регистра глобальной истории для формирования бита предсказания перехода
После выполнения очередной команды условного перехода содержимое регистра сдвигается на один разряд, а в освободившуюся позицию заносится единица (если исходом команды был переход) или ноль (если перехода не было). Следовательно, кодовая комбинация в GHR (РГИ) отражает историю выполнения последних l команд условного перехода. Под индексирование массива предикторов (элементов механизма предсказания) выделяются k младших разряда GHR (чаще всего l = k). Каждой k-разрядной комбинации исходов последовательно выполнявшихся команд УП в массиве дескрипторов соответствует свой счетчик. Таким образом, счетчик РНТ определяется тем, какая комбинация исходов имела место в k предшествовавших командах перехода. Содержимое счетчика используется для предсказания исхода текущей команды перехода и впоследствии модифицируется по результату фактического выполнения команды.
Регистр локальной истории (LHR, Local History Register) по логике работы аналогичен регистру глобальной истории, но предназначен для фиксации последовательных исходов одной и той же команды УП. В схемах предсказания с LHR присутствует так называемая таблица локальной истории, представляющая собой массив регистров локальной истории (рис. 8).
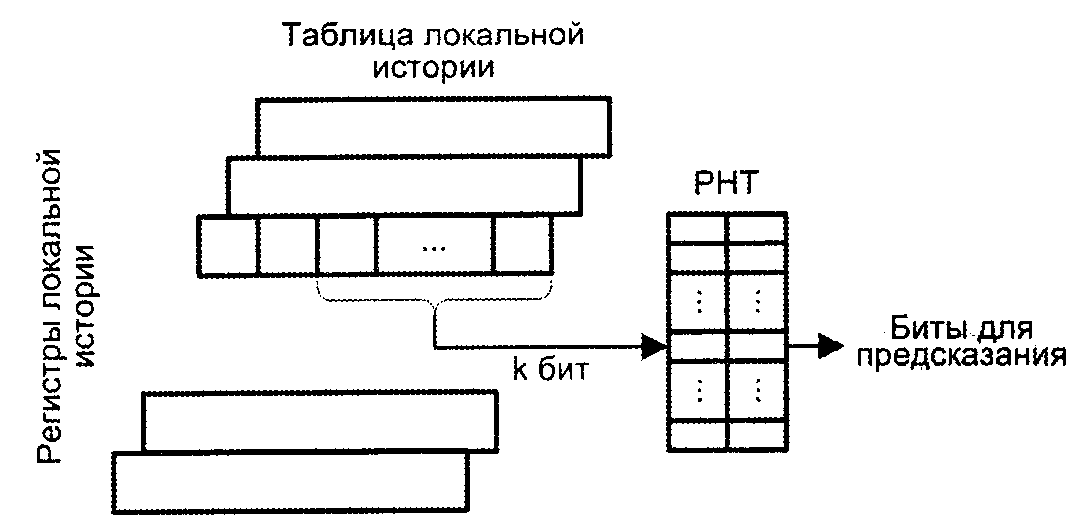
Рис. 8. Использование регистров локальной истории для формирования бита предсказания перехода
Как и в схеме с адресом команды перехода, каждый счетчик в РНТ фиксирует историю исхода только одной команды УП, но базируясь на более детальных знаниях, отражающих к тому же и последовательность исходов.
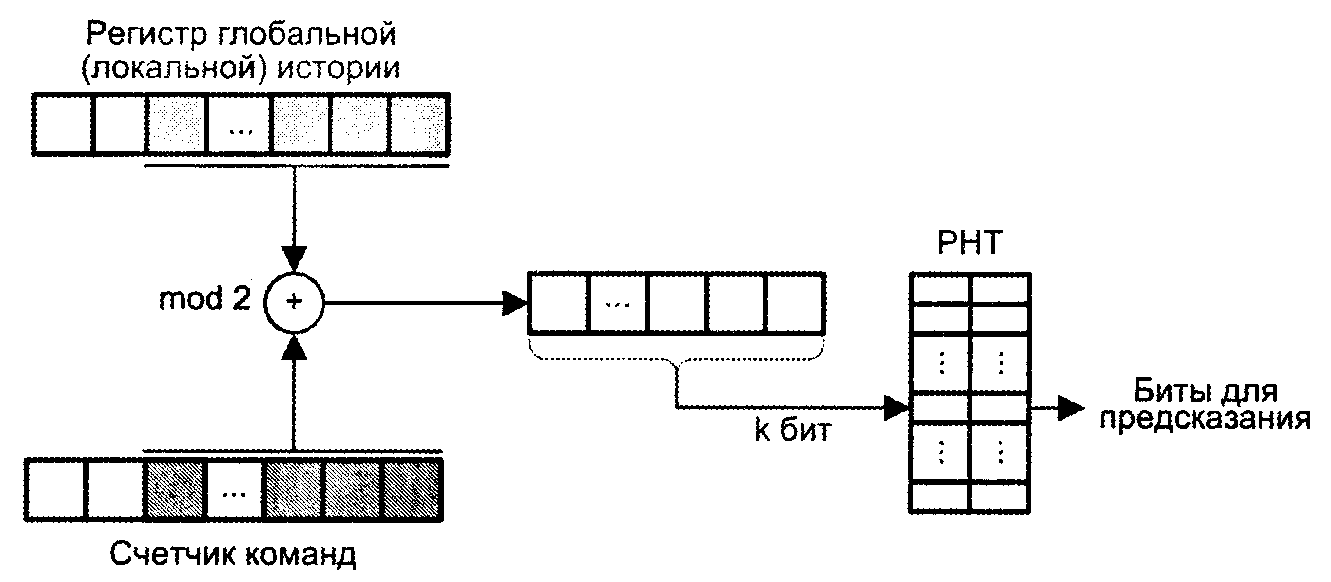
Действие команды условного перехода зависит не только от результатов предшествующих выполнений данной команды, но и от исхода других команд перехода. Учет обоих факторов позволяет повысить точность предсказаний. С этой целью в ряде динамических методов предсказания шаблон для доступа к РНТ формируется путем объединения адреса команды перехода и содержимого GHR (либо LHR), при этом используется одна из двух операций: конкатенация (сцепление) и сложение по модулю 2 («исключающее ИЛИ»).
При конкатенации k-разрядный шаблон для обращения к РНТ образуется посредством взятия q младших битов из одного источника, к которым пристыковываются k—q младших разрядов, взятых из второго источника (рис. 9(а)).

а)
б)
Рис. 9. Комбинированные схемы формирования бита
предсказания перехода
Эффективность предсказания на основе подобного шаблона зависит от соотношения количества разрядов (q и k-q), выбранных от каждого из двух источников. Здесь многое определяется и характером программы.
Вариант со сложением по модулю 2 предполагает побитовое применение операции «Исключающее ИЛИ» к обоим источникам (рис. 9 (б)). В качестве шаблона используются k младших разрядов результата. Сформированный шаблон содержит больше полезной информации для предсказания, чем каждый из источников по отдельности.
Суперконвейерные процессоры
Эффективность конвейера находится в прямой зависимости от того, с какой частотой на его вход подаются объекты обработки. Добиться n-кратного увеличения темпа работы конвейера можно двумя путями:
разбиением каждой ступени конвейера на п «подступеней» при одновременном повышении тактовой частоты внутри конвейера также в п раз;
включением в состав процессора п конвейеров, работающих с перекрытием.
Первый из этих подходов получил название суперконвейеризация (рис. 10).
Каждая из шести ступеней стандартного конвейера разбита на две более простые подступени, обозначенные индексами 1 и 2. Выполнение операции в подступенях занимает половину тактового периода. Тактирование операций внутри конвейера производится с частотой, вдвое превышающей частоту «внешнего» тактирования конвейера, благодаря чему на каждой ступени конвейера можно в пределах одного «внешнего» тактового периода выполнить две команды.

Рис. 14. Принцип работы сурепконвейера
В сущности, суперконвейеризация сводится к увеличению количества ступеней конвейера, как за счет добавления новых ступеней, так и путем дробления имеющихся ступеней на несколько простых подступеней. Главное требование — возможность реализации операции в каждой подступени наиболее простыми техническими средствами, а значит, с минимальными затратами времени. Вторым, не менее важным, условием является одинаковость задержки во всех подступенях.
Критерием для причисления процессора к суперконвейерным служит число ступеней в конвейере команд. К суперконвейерным относят процессоры, где таких ступеней больше шести (табл.1).