

Аверянов Основы современной информатики 2007
.pdfсии хорошо известного в научной практике метода представления чисел, когда число записывается в виде произведения, в котором один множитель (мантисса) имеет величину между 0,1 и 1, а другой (порядок) является степенью 10, так 6600 можно записать как 0,66 104, а 66 – как 0,66 102. Такое представление удобно в научных расчетах, поскольку часто диапазон величин, входящих в задачу бывает очень большим. В компьютерах принято двоичное представление чисел с плавающей точкой. Для суперкомпьютеров, имеющих длину слова 64 разряда, 49 разрядов отводится под ман-
тиссу и 15 разрядов под показатель степени, что позволяет работать в диапазоне 10-2466 до 102466 с точностью 15 десятичных разря-
дов мантиссы. К операциям с плавающей точкой относятся сложение, вычитание, умножение и деление двух операторов.
Выполнение таких операций требует несколько большего времени, чем соответствующие действия над числами с фиксированной точкой и целыми.
При определении быстродействия суперкомпьютера время, затрачиваемое на извлечение операндов из оперативной памяти и запись в оперативную память, входит в продолжительность операции.
В начале 90-х годов производительность машин этого класса достигает нескольких миллиардов операций в секунду, а позже уже десятков и сотен миллиардов. Суперкомпьютеры стали обязательным атрибутом парка вычислительной техники всех информацион- но-развитых стран. С их помощью решаются не только научнотехнические, но и комплексные стратегические задачи.
Они предназначаются для выполнения наиболее сложных (требующих большой производительности) вычислений и обработки информации большого объема. Это многопроцессорные системы, включающие все виды параллельной и последовательной обработки информации и многоуровневую иерархическую структуру запоминающих устройств, имеющих электронную кэш-память большого объема.
Разработчики суперкомпьютеров являются пионерами развития архитектуры компьютеров. Компьютеры следующих уровней по мере удешевления электронных компонентов с некоторой задержкой повторяют все новации в архитектуре, применяемые в суперкомпьютерах.
71
Первоначальный этап развития суперкомпьютеров связан с созданием так называемых матричных структур, реализующих SIMDархитектуру. Это группа процессоров, разделяющих общую память и выполняющих один поток инструкций, способных выполнять операции над матрицами, как примитивные инструкции. Количество процессоров, входящих в группу, может составлять 1000 и более.
Одним из важнейших вопросов для параллельных структур был вопрос обмена множества процессоров с модулями ОП (рис. 2.11).
Разделение памяти позволяет всем процессорам параллельной системы иметь доступ к глобальным, или общим модулям памяти. В простой схеме разделения памяти (см. рис. 2.11, а) каждый процессор непосредственно соединяется с каждым банком памяти. Недостаток здесь в том, что процессоры и банки памяти должны иметь очень большое количество соединительных линий. Другое решение (см. рис. 2.11, б) дает «шина» – общий канал связи, по которому каждый процессор посылает запросы к банкам памяти, а последние выдают данные. Такая «шина» может быть перегружена (и, следовательно, работать медленно), когда требуется передавать много сообщений. Еще одно решение представляет собой так называемая «сеть омега» (см. рис. 2.11, в), в ней процессоры связываются с модулями памяти коммутирующими устройствами, у каждого из которых два входных и два выходных канала. В такой сети каждый процессор может напрямую связываться с каждым модулем памяти, однако здесь нет нужды в таком большом количестве линий связи, которого требует настоящая система с прямыми связями.
Преимущества сети становятся все более очевидными по мере роста числа процессоров и модулей памяти. Недостаток ее в том, что иногда сообщения проходят через множество коммутирующих станций, прежде чем достигают абонента.
Наиболее перспективным способом обмена с ОП является подключение к каждому процессору локальных блоков памяти, с которыми он непосредственно взаимодействует, так называемых систем распределенной памяти. Способы возможного взаимодействия процессоров приведены на рис. 2.12.
72
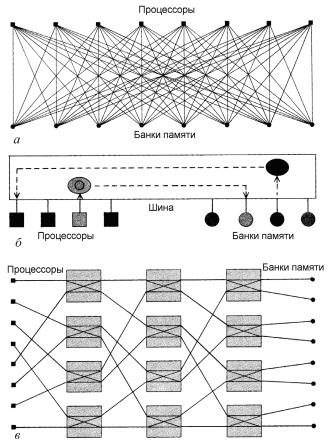
Рис. 2.11. Различные варианты обмена информацией для параллельных структур
В системах распределенной памяти устанавливаются соединения между процессорами, каждый из которых монопольно владеет некоторым количеством памяти. Простейшие схемы соединения процессоров – «кольцо» (см. рис. 2.12, а) и «решетка» (см. рис. 2.12, б). Более специализированная структура связей – «двоичное дерево» (см. рис. 2.12, г). Особенно эффективна она в так называемых экспертных системах, в которых последовательности принятия решений могут быть представлены в виде «дерева». Можно
73
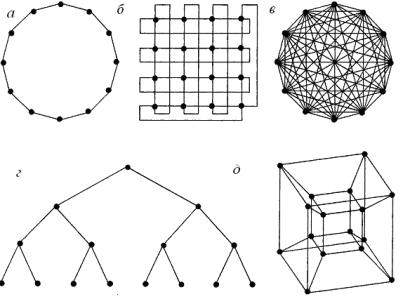
также соединить каждый процессор с каждым (см. рис. 2.12, в), но для этого потребуется нереально большое количество соединений. Одна из новых схем соединения, которая все шире распространяется, основана на топологии гиперкуба (см. рис. 2.12, д), в этой схеме процессоры играют роль вершин многомерного куба и соединены его ребрами (в показанном примере они находятся в вершинах четырехмерного куба). В такой системе каждый процессор может посылать сообщения любому другому процессору по сравнительно короткому пути, при этом процессоры не перегружаются слишком большим количеством соединений.
Рис. 2.12. Способы возможного взаимодействия процессоров:
а – «кольцо»; б – «решетка»; в – каждый с каждым; г – «дерево»; д – гиперкуб
Оптимальным с точки зрения связей считается гиперкуб, реализованный в первом проекте американского суперкомпьютера. Основные проблемы использования матричных структур (SIMD) были связаны с их программированием и высокой стоимостью технической реализации.
74
Значительно изменил ситуацию переход к векторно-конвейер- ной архитектуре, представляющей пространственно-временное распараллеливание процессов обработки, внедрение которой связывают с именем Сеймура Крея, основателя фирмы Cray Research Inc., которая до 90-х годов лидировала в производстве суперкомпьютеров. И хотя на современном этапе эта архитектура в чистом виде уже не применяется в новых разработках, однако она оказала значительное влияние на развитие вычислительной техники и некоторые черты этой архитектуры уже в новом технологическом воплощении присутствуют и в современных архитектурах. Принцип конвейерной архитектуры позволяет использовать традиционное последовательное программирование.
В терминах вычислительной математики вектор – это, по существу, упорядоченный массив независимых чисел. Такие массивы и называются векторами, поскольку в геометрии они могли бы представлять набор значений координат: например, массив из трех чисел может представлять точку или направление в трехмерном пространстве, а массив из четырех чисел – точку или направление в четырехмерном пространстве. В вычислительном контексте вектора могут насчитывать тысячи элементов, не имея никакой геометрической интерпретации. Часто бывает, что одна и та же операция должна быть выполнена над каждым элементом вектора (например, сложение, вычитание, умножение и т.п. двух векторов). При скалярном выполнении, например, операции умножения двух векторов первый элемент одного вектора умножается на первый элемент другого, второй умножается на второй и т.д. Векторный вариант выполнения предполагает одновременное выполнение этой операции над каждой парой векторов (с помощью параллельно работающих процессоров). Реализация этой операции осуществляется с помощью SIMD-структуры со всеми вытекающими последствиями.
Конвейерная обработка – метод повышения быстродействия одиночного процессора – подобно линии сборки автомобиля на конвейере (рис. 2.13). Идея, впервые использованная Генри Фордом, оказалась весьма перспективной и в области вычислительной техники.
75
Любая вычислительная операция распадается на ряд шагов, выполняемых специализированными компонентами процессора (реализующими его систему команд). В обычном процессоре (см. рис. 2.13, а) пока одна компонента работает, остальные бездействуют (простаивают). На рис. 2.13 операция умножения распадается на следующие шаги: извлечение из памяти порядка и мантиссы обоих чисел и выделение этих частей, сложение порядков, умножение мантисс и представление результатов в требуемой форме. Процессор с конвейерной организацией действует аналогично автомобильному конвейеру, по выполнении шага операций над одной парой чисел другая пара поступает для выполнения того же шага, не дожидаясь, пока первая пара пройдет все этапы операции. Естественно, что любая конвейерная обработка имеет смысл при массовом производстве и эффект от нее наступает после заполнения конвейера вновь поступающими данными (мертвое время конвейера). При этом скорость конвейерной обработки зависит от длины конвейера. Так, если длина конвейера равна N компонентам, то после заполнения такой процессор будет работать в N раз быстрее обычного процессора последовательной обработки. Выбор длины конвейера – вопрос достаточно сложный, поскольку любая параллельная обработка (в том числе и векторная) предполагает соблюдение двух основных требований – независимость потока команд и независимость потока данных. Большие сложности при работе конвейеров представляют ветвящиеся алгоритмы. Хотя разработчики принимают немалые усилия для преодоления этих трудностей (сцепление конвейеров, «спекулятивное» выполнение инструкций, эвристическое предсказание переходов и т.п.).
Начало конвейерной обработке положила поточная обработка в первых суперкомпьютерах с разделением процессоров на процессоры команд (осуществляющие доставку и дешифровку команд данных) и процессоры обработки данных, производящие непосредственную обработку. При этом для исключения потерь времени на доставку дешифровка следующей команды осуществляется процессором команд во время выполнения текущей команды процессорами обработки данных. Эта процедура в настоящее время реализована практически во всех современных микропроцессорах (на-
чиная с Intel 8086).
76
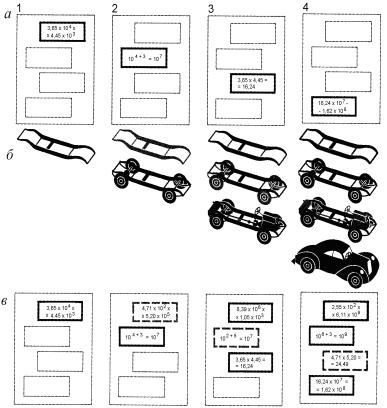
Рис. 2.13. Принцип конвейерной архитектуры
Примерно до середины 90-х годов XX в. основное направление развития суперкомпьютерных технологий было связано с построением специализированных многопроцессорных систем из массовых микросхем. Один из сформировавшихся подходов – SMP (Symmetric Multi Processing), подразумевал объединение многих процессоров с использованием общей памяти, что сильно облегчало программирование, но предъявляло высокие требования к самой памяти. Использовалась как поточная, так и векторная обработка. Сохранить быстродействие таких систем при увеличении количества узлов до десятков было практически невозможно. Кроме того, этот подход оказался самым дорогим в аппаратной реализации. На порядок более дешевым и практически бесконечно масштабируемым оказался способ MPP (Massively Parallel Processing), при котором независимые специализированные вычислительные модули объединяются специализированными каналами связи, причем те и другие создавались под конкретный компьютер и ни в каких других целях не применялись.
Идея создания кластерных рабочих станций явилась фактически развитием метода MPP, поскольку логически МРР не сильно отличается от обычной локальной сети. Локальная сеть стандартных персональных компьютеров при соответствующем программном обеспечении, использовавшаяся как многопроцессорный суперкомпьютер, и стала прародительницей современного кластера. Сейчас слова кластер и суперкомпьютер в значительной степени синонимы (хотя традиционные кластеры по-прежнему имеют широкое распространение). Эта идея получила воплощение, когда благодаря оснащению персональных компьютеров высокоскоростной шиной PCI и появлению дешевой, но быстрой сети Fast Ethernet кластеры стали догонять специализированные МРРсистемы по коммуникационным возможностям. Это означало, что современную МРР-систему можно создать из стандартных серийных компьютеров при помощи серийных коммуникационных технологий, причем такая система обходится дешевле, в среднем, на два порядка.
Некоторым промежуточным архитектурным решением представляется разработанный фирмой IBM суперкомпьютер SP (Scal-
78

able POWERparallel), получивший широкое распространение. Он представляет так называемую MSIMD-архитектуру, которую иногда называют массивно параллельной обработкой по схеме неразделяемых ресурсов, а иногда масс-процессорной макроконвейерной или динамической сетевой архитектурой. Компьютер построен на основе фактически автономных рабочих станций этой фирмы RS-6000, на базе 64-разрядного RISC-процессора POWER*. Модули объединяются с помощью специализированной коммуникационной матрицы. Система построена по модульному принципу, расширяется от 16 до 152 узлов, структура коммуникационной матрицы может настраиваться на конкретное приложение.
Мощный толчок развитию кластерных технологий дал быстрый рост производительности вновь выпускаемых массовых процессоров. Это сделало высокопроизводительные решения доступными даже для отечественных производителей и привело к появлению отечественных суперкомпьютеров на уровне западных и японских моделей. Самый мощный кластер в России на 2005 – 2006 гг. МВС 15000 БН с реальной производительностью 5,3 TFlops, построен из вычислительных узлов компании IBM на базе процессоров POWER PC и системной сети Myrinet.
Доля кластеров в списке суперкомпьютеров за период с 2000 до 2004 г. увеличилась с 2,2 до 60,8 %. При этом более 71,5 % процессоров, используемых для создания суперкомпьютеров, – массово выпускаемые процессоры компаний Intel и AMD.
Кластерные технологии используются и в новейших суперкомпьютерных разработках ведущих изготовителей: например, в самом мощном на 2005 г. суперкомпьютере IBM BlueGene/L с производительностью более 136 TFlops использовались многие элементы кластерной архитектуры.
Сфера применения кластерных систем сейчас нисколько не меньше, чем суперкомпьютеров с другой архитектурой. Суперкомпьютерное моделирование может во много раз удешевить и ускорить выход на рынок новых продуктов, а также улучшить их качество. Так, вместо того, чтобы создавать дорогостоящие тестовые
* POWER – P(erformance) O(ptimization) W(ith) E(nhanced) R(ISC).
79
модели новых автомобилей и проводить натурные испытания для исследования их безопасности (разбивать их о стенку), можно быстрее и точнее все посчитать на компьютерных моделях. Благодаря этому многим западным автомобильным концернам удалось сократить срок разработки новых моделей автомобиля в пять раз, с 10 до 2-х лет.
Компьютерная обработка геофизических данных позволяет создавать высокодетализированные модели нефтяных и газовых месторождений, обеспечивая более эффективную, безопасную и дешевую разработку скважин. В табл. 2.1 и 2.2 представлены сравнительные данные по различным областям использования суперкомпьютеров и сравнительные данные их производительности в этих областях (данные 2005 г.).
Несколько слов об архитектуре суперкомпьютеров на базе кластерных систем, как наиболее перспективном направлении развития подобного вида компьютеров. Как уже указывалось, кластер состоит из вычислительных узлов на базе стандартных процессоров. Большинство таких систем высшего уровня (Тор 500) выпол-
нены на процессорах Intel (Xeon, Xeon EM64, Itanium 2). Часто ис-
пользуются процессоры POWER 2 и POWER 2 PC компании IBM. В последнее время популярностью пользуются процессоры АМD (Operton и его двухъядерная версия).
Каждый узел работает под управлением своей копии операционной системы, в большинстве случаев – Linux. Состав и мощность узлов могут быть разными в рамках одного кластера, однако чаще они строятся из однородных компонентов.
Кластер – сложный программно-аппаратный комплекс, и задача построения кластера не ограничивается объединением большого количества процессоров в один сегмент. Использование тех или иных компонентов и выбор конкретной коммуникационной среды зависит от многих факторов и, прежде всего, от типа задач, для которых строится кластер. Для некоторых хорошо распараллеливаемых задач (таких, как компоновка независимых сюжетов в видео-
80