

1 курс летняя сессия / Экономическая информатика / ЭкИнф / БД
.pdfЛекция. Базы данных
1.1. Общие сведения
Теория управления БД как самостоятельная дисциплина начала развиваться с начала 50-х годов и это было связано с развитием экономики, усложнением решаемых задач и возрастанием объемов обрабатываемых данных. Ответом на сложившееся положение стало появление первых информационных систем (ИС).
ИСвзаимосвязанная совокупность средств, методов и персонала, используемых для хранения, обработки и выдачи информации в интересах достижения поставленной цели.
Ядром ИС являются хранимые в ней данные в виде определенной структуры, т.е. БД.
Введем основные понятия.
База данных (БД)― это:
― структурированный набор данных, описывающих характеристики какой-либо физической или виртуальной системы.
—реализованная с помощью компьютера информационная структура (модель), отражающая состояние объектов и их отношения.
—поименованная совокупность структурированных данных, относящихся к определенной предметной области.
Под предметной областью понимают часть реального мира, подлежащую изучению с целью организации управления в этой сфере и последующей автоматизации процесса управления. Предметная область представляет собой некоторую совокупность реальных объектов, каждый из которых обладает определенным набором качественных и количественных свойств (атрибутов). Между информационными объектами в БД может существовать связь. Совокупность объектов и связей между ними образуют структуру БД (или ИЛМ- информационнологическую модель).
Определений баз данных существует огромное количество. Но с точки зрения прикладного программиста главное в базе данных то, что ему совсем не обязательно знать особенности физического хранения данных на диске. Файлы, блоки, сегменты и др. - программист, работающий с базой данных, может вообще не задумываться об этих подробностях. Он работает с информацией на логическом уровне, оперируя такими понятиями, как таблица, запись, поле.
«Базой данных» часто упрощѐнно или ошибочно называют СУБД. Набор данных (собственно БД) и программное обеспечение, предназначенное для организации и ведения баз данных (СУБД)- это разные вещи. СУБД является связующим звеном между данными, размещенными на носителях и пользователями. Основная задача СУБД обрабатывать все запросы пользователя к данным, хранящимся в БД, скрывая все детали на уровне АО.
Требования к СУБД:
1.хранение данных,
2.обеспечение доступа к данным
3.наличие пользовательских привилегий
4.защита от несанкционированного доступа
5.наличие API (это инструмент, или набор функций, который позволит разработчику в случае необходимости написать программу, которая сможет общаться с БД)
6.наличие универсального языка формулирования запросов
7.эффективный доступ к данным (быстрый поиск)
8.возможность резервного копирования и восстановления данных
9.наличие интерфейса администратора БД
10.наличие механизма сжатия данных
2
11.распределенное хранение данных (если много клиентов требуют доступа единовременно).
2.2.Структура БД. Модель данных
В классической теории баз данных, модель данных есть формальная теория представления и обработки данных в СУБД, которая включает:
1)структуру: методы описания типов и логических структур данных (что логически представляет база данных);
2)манипуляции: методы манипулирования данными (способы перехода между состояниями базы данных и способы извлечения данных из базы данных);
3)целостность: методы описания и поддержки целостности базы данных (средства описаний кор-
ректных состояний базы данных).
Каждая БД строится на основе некоторой модели данных. СЛАЙД 2
Процесс создания ИЛМ начинается с определения требований к БД ее будущих пользователей. Единое обобщенное представление об этих требованиях называют концептуальной моделью. При построении концептуальной модели основные усилия разработчиков сосредотачиваются на структуризации данных.
Версия концептуальной модели, которая может быть реализована конкретной СУБД, называется логической моделью. Логическая модель, отражающая логические связи между атрибутами (свойствами) объектов вне зависимости их содержания и среды хранения, может быть сетевой, иерархической и реляционной. Физическая модель, отображает размещение данных, методы доступа к ним. На уровне физической модели электронная БД представляет собой файл или их набор в формате TXT, CSV, Excel, DBF, XML либо в специализированном формате конкретной СУБД.
СЛАЙД 3
|
Логическая |
|
|
Концептуальная |
модель |
Физическая |
|
• иерархическая |
|||
модель |
модель |
||
|
•сетевая
•реляционная
Каждая СУБД функционирует в конкретной языковой среде, т.е. используется специальный язык, на котором оформляются запросы к БД, с помощью которого представляются данные, разрабатываются прикладные программы для конкретной СУБД. Для программиста эти языковые средства представлены в виде команд языка, а для пользователей в виде средств диалога (меню, например), которые в конечном итоге интерфейсная система СУБД переводит в те же самые команды. Язык СУБД включает две категории средств:
язык описания данных и язык манипулирования данными.
Централизованный характер управления данными в БД предполагает необходимость существования некоторого лица, на которое возлагаются функции администрирования данными, хранимыми в БД.
Общие принципы хранения данных в БД:
•целостность и непротиворечивость данных, под которыми понимается как физическая со-
хранность данных, так и предотвращение неверного использования данных, поддержка допустимых сочетаний их значений, защита от структурных искажений и несанкционированного доступа.
•минимальная избыточность данных обозначает, что любой элемент данных должен храниться
вбазе в единственном виде, что позволяет избежать необходимости дублирования операций, производимых с ним.
Итак, модель данных- это набор принципов, определяющих организацию логической структуры хранения данных в базе. Это совокупность структур данных и операций их обработки. В теории СУБД по способу установления связей между данными выделяют три основные типа моделей данных: иерархический, сетевой и реляционный.

3
Первыми появились иерархические базы данных. СЛАЙД 4. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений предок/потомок. Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных - невозможность реализовать отношения "многие ко многим", а также ситуации, когда запись имеет несколько предков.
СЛАЙД 5. Сетевая структура баз данных появилась как развитие иерархической. Термин "сетевая" подчеркивает модель связей данных в базе, когда каждая запись может находиться в отношениях "многие ко многим" с другими записями, что делает графическую модель базы похожей на рыбацкую сеть. Разрабатывать серьезные приложения в рамках сетевой модели базы данных довольно трудно, причем сложность разработки при усложнении задач возрастает в геометрической прогрессии.
Настоящий прорыв в развитии баз данных произошел тогда, когда возросшая мощность компьютеров позволила в полной мере реализовать реляционную модель данных. Теория реляционных баз данных была разработана доктором Коддом в начале 70-х годов 20 века. В реляционных базах данные хранятся в виде таблиц, состоящих из строк и столбцов. Столбцы таблиц реляционной базы могут содержать скалярные данные фиксированного типа - числа, строки, даты... Таблицы в реляционной базе данных могут быть связаны отношениями "один к одному" или "один ко многим".
СЛАЙД 6. Реляционные базы данных занимают сейчас доминирующее положение. Не будет большим преувеличением сказать, что иерархическая и сетевая структуры баз данных ушли в прошлое, уступив свое место реляционным базам. MS SQL Server и MS Access, InterBase и FoxPro, PostgreSQL и Paradox... Все они построены на реляционной модели данных. Реляционной базой в чистом виде является и MySQL.
Объектно-ориентированные базы данных (ООБД) появились совсем недавно как естественное развитие объектно-ориентированных языков программирования. На сегодняшний день ООБД пока не имеют сколько-нибудь широкого распространения, но, несомненно, они в ближайшее время будут бурно развиваться. Это подтверждает и тот факт, что разработчики многих реляционных БД включают в свои базы средства работы с объектными типами данных. Такие базы данных получили название объектно-реляционных. По этому пути, в частности, развивается и Oracle. Бывшая ранее чисто реляционной базой, Oracle начиная с 8 версии поддерживает возможность хранения и обработки объектов и может быть отнесена к объектнореляционному классу баз данных.
2.3. Реляционная модель
Реляционная база данных (РБД)- это такая база данных, в которой вся информация представлена в виде двумерных таблиц. Данные в таблицах РБД должны быть структурированы специальным образом.
СЛАЙД 7. Любая таблица состоит из строк и столбцов. В теории РБД строки таблиц называют "кортежи", а столбцы - "атрибуты". Но в русском компьютерном языке, как среди программистов, так и среди пользователей баз данных, эти мудреные словечки не прижились. Иногда употребляются термины "запись" и "поле", н о чаще всего строки так и называют строками, а столбцы - столбцами.
Каждый столбец любой таблицы в реляционной базе данных должен иметь конкретный тип и размер. Все содержимое ячеек столбца должно соответствовать его типу. СЛАЙД 8(типы данных).
Главное отличие БД от простого набора электронных таблиц - информация в разных таблицах должна быть взаимосвязана, и в БД имеются средства для организации этих взаимосвязей: первичные и внешние ключи и специальный язык SQL, предназначенный для манипулирования данными.
Приступая к созданию БД сначала надо решить, что будет храниться в базе, то есть определиться со структурой полей, их типами и размерностью, смыслом хранимой в них информации. Важнейший принцип организации информации в РБД - нормализация таблиц. Ее проведение снимает множество будущих проблем, могущих возникнуть при работе с БД. Согласно теории нормализации выделяются шесть нормальных форм, пять из которых так и называются: первая, вторая, третья, четвертая, пятая нормальная форма, а также нормальная форма Бойса-Кодда, лежащая между третьей и четвертой.
База данных считается нормализованной, если ее таблицы (по крайней мере, большинство таблиц) представлены как минимум в третьей нормальной форме.
4
Главная цель нормализации базы данных - устранение избыточности и дублирования информации. В идеале при нормализации надо добиться, чтобы любое значение хранилось в базе в одном экземпляре, причем значение это не должно быть получено расчетным путем из других данных, хранящихся в базе.
Основные требования, которым должна удовлетворять каждая из нормальных форм
Первая нормальная форма (1НФ)
запрещает повторяющиеся столбцы (содержащие одинаковую по смыслу информацию)
запрещает множественные столбцы (содержащие значения типа списка и т.п.)
требует определить первичный ключ для таблицы, то есть тот столбец или комбинацию столбцов, которые однозначно определяют каждую строку
Вторая нормальная форма (2НФ)
Вторая нормальная форма требует, чтобы неключевые столбцы таблиц зависели от первичного ключа в целом, но не от его части.
Примечание: если таблица находится в 1НФ и первичный ключ у нее состоит из одного столбца, то она автоматически находится и во 2НФ.
Третья нормальная форма (3НФ)
Чтобы таблица находилась в 3НФ, необходимо, чтобы неключевые столбцы в ней не зависели от других неключевых столбцов, а зависели только от первичного ключа.
Самая распространенная ситуация в данном контексте - это расчетные столбцы, значения которых можно получить путем каких-либо манипуляций с другими столбцами таблицы. Для приведения таблицы в третью нормальную форму такие столбцы из таблиц надо удалить.
Главное, чего мы добьемся, проведя нормализацию базы данных - это устранение (или, по крайней мере, серьезное сокращение) избыточности, дублирования данных. Как следствие, значительно сокращается вероятность появления противоречивых данных, облегчается администрирование базы и обновление информации в ней, сокращается объем дискового пространства.
Наличие взаимосвязей, перекрестных ссылок между таблицами - это одно из фундаментальных свойств, отличающих РБД от простого набора таблиц. Для реализации таких взаимосвязей почти все СУБД позволяют определять в таблицах первичные и внешние ключи и имеют в своем составе механизмы поддержания ссылочной целостности.
Первичный ключ
Первичный ключ - это столбец или группа столбцов, однозначно определяющие запись. Первичный ключ по определению уникален: в таблице не может быть двух разных строк с одинаковыми значениями первичного ключа. Столбцы, составляющие первичный ключ, не могут иметь значение NULL. Для каждой таблицы первичный ключ может быть только один.
Уникальный ключ
Уникальный ключ - это столбец или группа столбцов, значения (комбинация значений для группы столбцов) которых не могут повторяться. Отличия уникального ключа от первичного - в том, что:
уникальных ключей для одной таблицы может быть несколько (правила какой нормальной формы при этом будут нарушены?)
уникальные ключи могут иметь значения NULL, при этом если имеется несколько строк со значениями уникального ключа NULL, такие строки согласно стандарту SQL 92 считаются различными (уникальными).
Внешний ключ

5
Внешние ключи - это основной механизм для организации связей между таблицами и поддержания целостности и непротиворечивости информации в базе данных.
Внешний ключ - это столбец или группа столбцов, ссылающиеся на столбец или группу столбцов другой (или этой же) таблицы. Таблица, на которую ссылается внешний ключ, называется родительской или главной таблицей, а столбцы, на которые ссылается внешний ключ - родительским ключом. Родительский ключ должен быть первичным или уникальным ключом, значения же внешнего ключа могут повторяться хоть сколько раз. То есть с помощью внешних ключей поддерживаются связи "один ко многим". Типы данных (а в некоторых СУБД и размерности) соответствующих столбцов внешнего и родительского ключа должны совпадать.
И самое главное. Все значения внешнего ключа должны совпадать с каким-либо из значений родительского ключа. Появление значений внешнего ключа, для которых нет соответствующих значений родительского ключа, недопустимо. Вот тут-то мы переходим к понятию ссылочной целостности.
Ссылочная целостность
Первое из правил ссылочной целостности: в таблице не допускается появления (неважно, при добавлении или при модификации) строк, внешний ключ которых не совпадает с каким-либо из имеющихся значений родительского ключа.
Более интересные моменты возникают, когда мы удаляем или изменяем строки родительской таблицы. Как при этом не допустить появления "болтающихся в воздухе" строк дочерней таблицы? Для этого существуют функции СУБД (на примере Access), которые будут контролировать ситуацию:
каскадное обновление связанных полей
каскадное удаление связанных записей
обеспечение целостности данных
SQL СЛАЙД 9.
Язык SQL (Structured Query Language - структурированный язык запросов) - это основное средство общения с РБД. Более того: для большинства реляционных СУБД использование языка SQL - это единственный способ выборки и модификации информации в базе.
Язык SQL был разработан в 1970 году компанией IBM и достаточно быстро получил широкое признание. Разработчики реляционных СУБД один за другим включали SQL в свои продукты, но диалекты языка в разных СУБД достаточно сильно отличались.
Массовое распространение SQL в различных, довольно сильно отличающихся диалектах привело к необходимости его стандартизации. В 1986 году ISO (Международная организация по стандартизации) и ANSI (Американский национальый институт стандартов) опубликовали стандарт SQL 86, который затем дважды - в 1989 и в 1992 годах - пересматривался. Стандарт SQL 92 действует по сей день.
Основные принципы языка SQL
SQL - непроцедурный язык. В SQL не записываются шаг за шагом все инструкции, а просто говорится, что нужно сделать. Например: выбрать все строки таблицы Пользователи, в которых ФИО = "Иванов И. И.". Как это будет делаться, в каком порядке блоки данных будут считываться с диска, какие циклы надо организовать для обработки запроса и т.п. - это уже забота СУБД, а не программиста.
Язык SQL предназначен только для взаимодействия с базой данных. Средств разработки законченных программ (организации красивых экранных форм, печати отчетов и т.п.) в нем нет.
Составные части языка SQL
Традиционно выделяют две основных части языка SQL (хотя деление это во многом условное):

6
DDL - Data Definition Language - Язык определения данных. DDL включает в себя операторы создания, модификации, удаления объектов (Create, Alter, Drop...). К DDL обычно также относят операторы управления правами пользователей (Grant, Revoke).
DML - Data Manipulation Language - Язык манипулирования данными. DML предназначен для ведения (добавления, модификации, удаления) и выборки информации из базы данных. Основные операторы DML - Select, Insert, Update и Delete.
Транзакции - одно из фундаментальных понятий, отличающих базу данных от обычной файловой системы и от простого набора таблиц.
Транзакция - это группа последовательно выполняемых операторов SQL, которые либо должны быть выполнены все, либо не должен быть выполнен ни один из них. Главная задача транзакций - обеспечить целостность данных в случаях, когда несколько SQL-операторов выполняют зависящие друг от друга изменения данных.
Что будет, если первый оператор выполнится, а второй по какой-то причине - нет (сбой сервера, неправильный номер счета, переполнение... - мало ли какая может быть ошибка)? Деньги с одного счета списаны, а на другой не поступили...
Механизм транзакций как раз и позволяет корректно выходить из подобных ситуаций. Объединив эти два оператора UPDATE в одну транзакцию, мы обеспечим выполнение (или невыполнение) их обоих как одного целого.
Преимущества РМД
наличие развитой теории = реляционной алгебры (в ее рамках действия над данными могут быть сведены к операциям реляционной алгебрыобъединение, пересечение, вычитание, выборка, проекция, соединение, деление),
наличие аппарата сведения двух других моделей к РМД,
наличие ускоренного доступа к данным,
наличие стандартизованного высокоуровневого языка запросов к БД, позволяющего манипулировать ими без знания конкретной физической организации БД во внешней памяти.
Пример1. СЛАЙД 10.
Рассмотрим отношение СТУДЕНТЫ, содержащее информацию о студентах вуза:
СТУДЕНТ (№ студ_билета, ФИО, Дата_рожд, Спец-ть, Группа)
В нашем примере используются три типа данных - текстовый (ФИО), дата/время (дата_рожд) и числовой (№ студ билета).
Домен наименьшая единица данных РМД - допустимое множество значений данного типа. В нашем примере можно для каждого столбца таблицы определить домен, например домен для Группа Э1, Э2, И1, Ф1.
Схема отношения
СТУДЕНТ (№ студ_билета, ФИО, Дата_рожд, Код группы)
Поскольку отношение с математической точки зрения является множеством, а множества по определению не содержат совпадающих элементов, то никакие две строки не могут быть дубликатами друг друга. Т.о. в таблице всегда должен присутствовать атрибут (столбец) (или набор атрибутов), однозначно определяющий каждую строку отношения и обеспечивающий уникальность строк таблицы. Такой атрибут, или набор атрибутов называется первичным ключом отношения.
Вреальных БД названия не делают ключами из-за их длины, замедляющей процесс поиска.
Взависимости от количества атрибутов, входящих в первичный ключ, различают простые и сложные (составные) ключи. Простой ключ - ключ, содержащий только один атрибут. Составной ключ содержит

7
несколько атрибутов. В зависимости от того, содержит ли атрибут, являющийся первичным ключом какуюлибо информацию, различают искусственные и естественные ключи.
Искусственный ключ - ключ, созданный самой СУБД, который сам по себе не содержит никакой информации. Естественный ключ - ключ, в который включены значимые атрибуты и который, т.о, содержит информацию. В нашем примере в качестве первичного ключа можно использовать № студ_билета. Причем этот ключ простой и естественный.
Вторичные ключи – это комбинация атрибутов, отличная от комбинации, составляющей первичный ключ. Вторичные ключи не обязательно обладают свойством уникальности.
СЛАЙД 11. В РМД данные представляются в виде совокупности взаимосвязанных таблиц. Взаимоотношения таблиц называются связями. Отношение СТУДЕНТЫ может быть связано с другим отношением ГРУППА (Код группы, Специальность, Год образования).
Внешний ключ - это атрибут (или множество атрибутов) одного отношения, являющийся ключом другого (или того же самого) отношения. Внешние ключи используются для установления логических связей между отношениями.
Связь между таблицами СТУДЕНТЫ и ГРУППА установлена по атрибуту «Код группы». В нашем примере атрибут «Код группы» присутствует в обеих таблицах. Он является внешним ключом.
2.4. Типы связей между таблицами
При установлении связи между таблицами одна из них будет являться главной, другая- подчиненной. Изменение записи главной таблицы повлечет за собой изменение множества доступных записей подчиненной таблицы, а изменение записи в подчиненной таблице не вызовет никаких изменений ни в одной из таблиц.
У главной таблицы может быть несколько подчиненных, но у подчиненной таблицы может быть только одна главная.
Различают 4 типа связей между таблицами:
1-1 -каждой записи одной таблицы соответствует только одна запись другой таблицы,
1-∞ - одной записи главной таблицы могут соответствовать несколько записей подчиненной таблицы,
∞-1 - нескольким записям главной таблицы может соответствовать одна и та же запись подчиненной таблицы,
∞-∞ - одна запись главной таблицы связана с несколькими записями подчиненной таблицы, а одна запись подчиненной таблицы связана с несколькими записями главной таблицы.
Различие между типами связей 1-∞ и ∞—1 зависит от того, какая таблица выбирается в качестве главной, а какая в качестве подчиненной.
Для РБД возможны лишь связи 1-1 и 1-∞.
Пример2. СЛАЙД 12.:
Студент (№ ст.бил., ФИО, Дата рождения, код группы)
Стипендия (№ ст.бил., Размер стипендии, доплата)
Группа (код группы, специальность, год образования)
Типы связей:
Студент-Стипендия 1:1 Группа-Студент 1:∞
Чтобы пользователь чувствовал себя комфортно, время ожидания ответа на запрос к БД не должно превышать нескольких секунд. В связи с этим требованием специально разрабатываются методы ускорения выборки, позволяющие обойтись без полного перебора строк при выполнении реляционных операций модификации отношений и отбора данных.
8
Наиболее эффективны методы индексирования значений ключей отношения.
Индексирование — логическая сортировка строк таблицы — заключается в создании вспомогательных файлов, содержащих упорядоченные списки значений ключей отношения со ссылками на строку отношения, в которой они находятся. Индексные файлы занимают дополнительную память, но резко ускоряют поиск благодаря применению метода половинного деления. Для одного отношения может быть создано несколько индексов. Кроме того, можно создать индекс для нескольких отношений, если они содержат одинаковые атрибуты, что позволит ускорить выполнение операций соединения этих отношений.
Индексы позволяют находить строки, в которых значения ключевых полей совпадают с заданным значением или принадлежат заданному интервалу.
2.5. Этапы проектирования баз данных
На этапе проектирования базы данных разработчик должен определить, из каких таблиц должна состоять база данных, какие данные нужно поместить в каждую таблицу и как связать таблицы. Следовательно, в результате проектирования определяются логическая структура базы данных, т. е. состав реляцион ных таблиц, их структура и межтабличные связи.
Для создания базы данных необходимо располагать описанием выбранной предметной области, охватывающим реальные объекты и процессы, а также определить все необходимые источники информации для удовлетворения предполагаемых запросов пользователей и потребности в обработке данных. На основе такого описания определяются состав и структура данных предметной области, которые должны находиться в базе и обеспечивать выполнение необходимых запросов и задач пользователей. Структура данных предметной области может отображаться информационно-логической моделью, на основе которой легко создается реляционная база данных.
Этапы проектирования и создания базы данных:
1.построение информационно-логической модели данных предметной области;
2.определение логической структуры реляционной базы данных;
3.конструирование таблиц базы данных;
4.создание схемы данных;
5.ввод данных в таблицы (создание записей);
6.разработка необходимых форм, запросов, макросов, модулей, отчетов;
7.разработка пользовательского интерфейса.
Впроцессе разработки модели данных необходимо выделить информационные объекты, соответствующие требованиям нормализации данных, и определить связи между ними. Полученная модель позволит создать реляционную базу данных без дублирования, в которой обеспечиваются однократный ввод данных при первоначальной загрузке и корректировках, а также целостность данных при внесении изменений.
Процесс выделения информационных объектов предметной области, отвечающих требованиям нормализации, может производиться на основе интуитивного или формального подхода. Теоретические основы формального подхода разработаны известным американским ученым Дж. Мартином и изложены в его монографиях по организации баз данных.
При интуитивном подходе легко выявить информационные объекты, соответствующие реальным объектам, однако получаемая при этом информационно-логическая модель, как правило, требует дальнейших преобразований. При таком подходе в случае отсутствия достаточного опыта возможны существенные ошибки. Последующая проверка выполнения требований нормализации обычно показывает необходимость уточнения информационных объектов.
Рассмотрим формальные правила выделения информационных объектов:
на основе описания предметной области выявить документы и их атрибуты, подлежащие хранению в базе данных;

9
определить функциональные зависимости между атрибутами;
выбрать все зависимые атрибуты и указать для каждого все его ключевые атрибуты, т.е. атрибуты, от которых он зависит;
сгруппировать атрибуты, одинаково зависимые от ключевых атрибутов. (Полученные группы зависимых атрибутов вместе с их ключевыми атрибутами образуют информационные объекты.)
При определении логической структуры реляционной базы данных на основе модели каждый информационный объект адекватно отображается реляционной таблицей, а связи между этими таблицами соответствуют связям между информационными объектами.
В процессе создания БД сначала конструируются таблицы, соответствующие информационным объектам построенной модели данных. Далее может создаваться схема данных, в которой фиксируются существующие логические связи между таблицами, соответствующие связям информационных объектов. В схеме данных могут быть заданы параметры поддержания целостности базы данных, если модель была разработана в соответствии с требованиями нормализации. Целостность данных означает, что в БД установлены и корректно поддерживаются взаимосвязи между записями разных таблиц при загрузке, добавлении и удалении записей в связанных таблицах, а также при изменении значений ключевых полей.
После формирования схемы данных осуществляется ввод непротиворечивых данных из документов предметной области.
На основе созданной базы формируются необходимые запросы, формы, макросы, модули, отчеты, производящие требуемую обработку данных и их представление.
С помощью встроенных средств и инструментов базы данных создается пользовательский интерфейс, позволяющий управлять процессами ввода, хранения, обработки, обновления и представ ления информации.
Рис. 1. Пример нормализации
10
2.6. Технологические реализации СУБД
По технологии обработки данных СУБД подразделяются на централизованные и распределенные. Централизованная (локальная) база данных хранится в памяти одной вычислительной системы. Распределенная база данных состоит из нескольких, возможно, пересекающихся или даже дублирующих друг друга частей, которые хранятся на различных компьютерах вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД). Для всех современных баз данных можно организовать сетевой доступ с многопользовательским режимом работы.
Централизованные базы данных с сетевым доступом могут иметь следующую архитектуру:
файл-сервер;
клиент-сервер базы данных;
трехуровневая архитектура ("тонкий клиент" - сервер приложений - сервер базы данных).
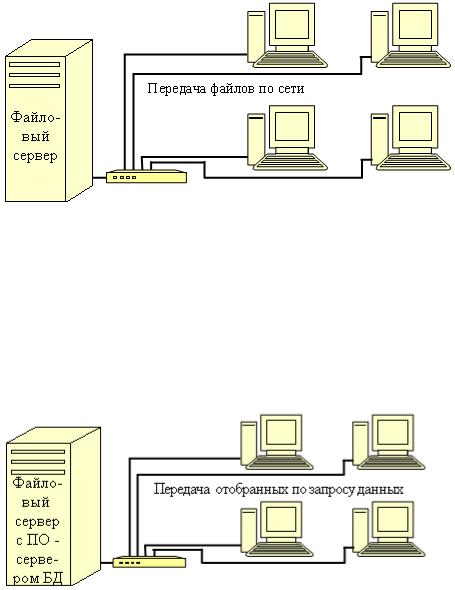
Рис. 2. Схема работы с БД в локальной сети с выделенным файловым сервером
Файл-сервер. Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (файловый сервер). На этот компьютер устанавливается операционная система (ОС) для выделенного сервера. На нем же хранится совместно используемая централизованная БД. Все другие компьютеры сети выполняют функции рабочих станций (на них установлены клиентские ОС). Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где и производится обработка информации. При большой интенсивности доступа к одним и тем же данным производительность системы падает. Пользователи могут создавать также локальные БД на рабочих станциях.
Рис. 3. Схема работы с БД в архитектуре "Клиент-сервер"
Клиент-сервер. В этой архитектуре на выделенном сервере, работающем под управлением серверной операционной системы, устанавливается специальное программное обеспечение (ПО) - сервер БД, например, MS SQL Server или Oracle. СУБД подразделяется на две части: клиентскую и серверную. Основа работы сервера БД - использование языка запросов SQL. Запрос на языке SQL, передаваемый клиентом (рабочей станцией) серверу БД, порождает поиск и извлечение данных на сервере. Извлеченные данные транспортируются по