

Максимов Информационные ресурсы и поисковые системы 2008
.pdfСчитается, что стек Google более детализирован и позволяет более гибко развивать собственные приложения конечному пользователю, однако, это иллюзия. Архитектура файловой системы и доступа к вычислительным мощностям скрыта в обоих случаях.
Сервисы Microsoft. Концепция Microsoft по организации распределенных вычислений претерпела существенные изменения. В первую очередь, это касается офисных приложений от Microsoft. Первоначально дело не шло дальше построения системы обновлений ПО посредством Internet. Сами программы и коды их активации стало возможным получать по Сети. Таким образом, речь не шла о собственно распределенных вычислениях. Была решена задача распространения программного кода по сети с последующим учетом того, на каких вычислительных установках он работает.
Вслед за решением этой задачи Microsoft реализовала распределенное хранение информации. Теперь пользователь мог работать с массивами данных, размещенными в распределенном файловом хранилище Microsoft и ее партнеров по данному проекту. Вместе с данными там могут размещаться и приложения. Таким образом, на вычислительной установке не требуется хранить и ПО, и данные. Можно просто загрузить программу по Сети, отредактировать, опять-таки загруженный по Сети файл, и сохранить его в виртуальной файловой системе для дальнейшего использования. Данная концепция, схематично представленная на рис. 7.2, получила название SaaS, т.е. «программное обеспечение, как сервис».
В данное время Microsoft продвигает несколько видоизмененную концепцию «Software + Services» («ПО+сервисы). В рамках данной концепции уже нет необходимости загружать ПО на локальную вычислительную установку. Можно для обработки своих данных арендовать удаленные программы, взаимодействуя с ними через пользовательский интерфейс, главным образом, он ориентирован на обмен XML файлами между удаленно исполняемой программой и браузером пользователя. Такой подход наиболее близок к распределенным вычислениям типа Cloud computing. Архитектура вычислений полностью скрыта от пользователя за интерфейсом доступа к программным средствам.
201
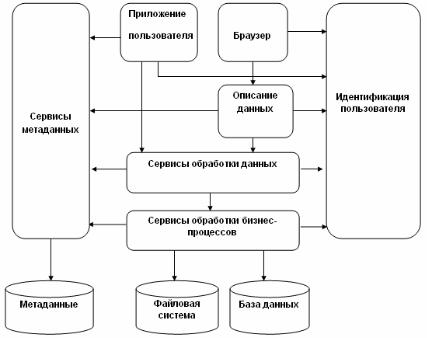
Рис. 7.2 Архитектура S+S от Microsoft.
От коммерческих реализаций распределенных вычислительных архитектур перейдем к разработкам, ориентированным на научные приложения. Наиболее известные проекты такого типа сосредоточены в области Grid Computing.
Примеры проектов Grid-вычислений. Впервые само поня-
тие Grid-вычислений появилось в работе Яна Фостера(Ian Foster) и
Карла Кессельмана(Carl Kesselman) «The Grid: Blueprint for a new computing infrastructure». На основе усилий добровольцев в 1997 г. появился проект distributed.net, а чуть позже, в 1999 г., SETI@home.
В данных проектах была сделана попытка объединить вычислительные мощности персональных компьютеров по всему миру для решения вычислительно емких задач. Результатом этой работы должен был стать Globus Toolkit, который позволил бы не только организовать распределенные расчеты, но также и распределенное
202
хранение, распределенное управление и другие, необходимые для распределенных вычислений, компоненты.
В настоящее время существует множество реализованных Grid-проектов. Самый старый проект SETI@home (http://setiathome.ssl.berkeley.edu/totals/html) насчитывает около 3
миллионов компьютеров, суммарная производительность которых составляет порядка 23,37 терафлопа. Другой аналогичный проект Folding@home достиг вычислительной мощности в 1502 терафлопа на 270000 машинах в марте 2008 года.
Другой успешный пример Grid-системы – это NAS (NASA Advanced Supercomputing facility). Данная система используется для моделирования генетических алгоритмов. Программы в рамках этого проекта используют около 350 рабочих станций SUN и SGI.
Следует заметить, что Grid-вычисления довольно популярны и в других медицинских проектах. Например, до апреля 2007 г. Проект исследования рака применял Grid MP, который использовал персональные компьютеры добровольцев, подсоединенные к Internet. По данным 2005 г. в этом проекте участвовали 3100000 машин.
Используют Grid и в Европейском Союзе. Это так называемый European DataGrid – самый большой Grid проект в мире. Он так же, как и LCH Computing Grid (LCG), был разработан для обработки данных ядерно-физических экспериментов на большом адронном коллайдере в CERN. Вычислительная мощность этой системы около 10 петобайт в год.
На рис. 7.3 представлена архитектура gLite – «легкого» Grid, который используется в проекте обработки данных большого адронного коллайдера.
На этой схеме в правой стороне рисунка изображены статусы задания по мере его выполнения различными компонентами Gridокружения, а слева собственно сами компоненты. Буквы на диаграмме обозначают состояния задания при его исполнении
203
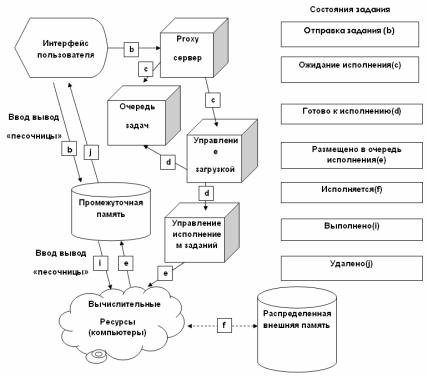
Рис. 7.3. Схема обработки данных в WLCG/EGEE Grid
Примеры других проектов Internet-вычислений. Кроме
Grid-вычислений и Internet-вычислений существуют и другие распределенные вычислительные архитектуры, ориентированные на решение различных специфических задач. Одной из них является криптография.
Проект HashClas@home исследовал алгоритмы генерации кодов MD5 и SHA1, широко используемые в современных системах защиты каналов связи. Отдельно алгоритму SHA1 посвящен другой проект – SHA-1. Речь идет об устойчивости алгоритмов к различного рода исходным данным, используемым при генерации ключей.
204

Другой интересный научный проект – прогноз погоды Climateprediction.net. Задача проекта – организовать расчет предсказания климата в 21-м веке. Но больше всего проектов сосредоточено в области физики и биологии. Это и исследования по искусственному интеллекту, и моделирование деятельности мозга, и исследования магнетизма материалов в нанотехнологиях, и моделирование больших наносистем, и предсказание землетрясений, и многое другое.
7.4. Андеграунд распределенных вычислений
Возможность использования распределенных вычислений в современных вычислительных средах, особенно в Internet, породило не только массу полезных применений, но не меньшее количество угроз. Современные распределенные атаки на различные сайты и сети во многом похожи распределенные вычисления. Здесь можно найти различные виды таких вычислений.
Рассмотрим, например, различные способы организации распределенных атак. Как правило, для организации такой атаки требуется большое количество компьютеров, с которых атаку проводят, так как в этом случае трудно обнаружить центр управления атакой и трудно заблокировать компьютеры, с которых атакуют1.
При организации таких атак на машинах устанавливается стандартное ПО, которое выполняет подавление активности атакуемого сайта. Для такого подавления требуется согласованные действия множества машин (несколько тысяч). Как правило, управлением этими машинами производится из одного управляющего центра.
Участие в такого рода мероприятиях чревато тем, что на машине добровольца остается ПО, которое выполняет некоторые функции, о которых владелец компьютера может даже и не подоз-
1 За последнее время мы стали свидетелями двух крупных атак, организованных добровольцами на сайты государственных органов. Вопервых, это атака 2007 года на эстонские сайты в связи с переносом памятника, и совсем свежие события августа 2008 года, когда была организована синхронная атака на российские и грузинские правительственные сайты, вызванная югоосетинским кризисом.
205
ревать. То есть компьютер в дальнейшем может быть использован третьими лицами в коммерческих целях без согласия его владельца.
Сети компьютеров, которые управляются третьей стороной без согласия их владельцев, принято называть бот-сетями. Традиционный способ создания бот-сетей – это заражение их програм- мами-троянами. Заразить компьютер можно через почтовую рассылку, через уязвимости сетевого программного обеспечения, через уязвимости веб-сервисов и т.п.
В настоящее время бот-сети – это коммерческий клиенториентированный продукт. Наиболее известной из коммерческих сетей принято считать RBN (Russian Business Network). ФБР счи-
тает эту сеть «худшей из худших». Считается, что сервисы этой сети расположены на неизвестном российском пуленепробиваемом хостинге.
Суть работы данной сети заключается в том, что сервис состоит из нескольких подразделений, решающих узкоспециализированные задачи, ориентированные на конечную бизнес-цель, создание коммерческой бот-сети и продажу ее услуг.
Есть группа разработчиков, которая совершенствует методы внедрения программ-троянов и сами программы-трояны, есть группа разработчиков, которая совершенствует методы управления «затроянеными» компьютерами, группа разработчиков биллинга (система сбора платежей за предоставляемую услугу), группа разработчиков пользовательского интерфейса.
Фактически речь идет о распределенной вычислительной платформе, на основе которой предоставляются услуги по нелегальному использованию распределенных вычислительных мощностей, приватной информации и банковской информации.
Биллинг в такой сети очень напоминает принципы биллинга для Internet-вычислений (Cloud computing). Пользователь платит только за тот набор услуг, который реально использует. Например, только за то время, в течение которого заранее выбранное им количество компьютеров используются для организации DDos-атаки, или только за конкретное количество эккаунтов электронной почты, которые можно использовать для спам-рассылки, или за точно определенное количество номеров кредиток, которые могут быть использованы системой для оплаты услуг своего клиента. В по-
206
следнем случае, система заботится о том, чтобы списание денег было не очень заметно для действительных владельцев карт и банков, эти карты выпустивших.
ГЛАВА 8. АРХИТЕКТУРА РАСПРЕДЕЛЕННЫХ РЕСУРСОВ
8.1. Типология и структура распределенных ИР
Рассматривая в предыдущих главах технологии и средства информационного поиска, мы не акцентировали внимание на орга- низационно-физических аспектах ИР и доступа к ним, тем самым показывая, что принципы информационного поиска и архитектура ИС имеет универсальный характер.
Реальные АИПС по своим возможностям различаются достаточно существенно (по крайней мере, для пользователей). Это связано не столько с решениями тех или иных разработчиков, сколько с многочисленными факторами, в той или иной степени, ограничивающими или даже исключающими некоторые функциональные возможности. Такими факторами являются, например, назначение и область применения, масштабность и интенсивность использования ИР, характер распределения информационных компонент (для сетевых систем), тип информации, источники и режим пополнения, предполагаемый профессиональный уровень потребителей и т.д.
По архитектуре, определяющей физическую доступность ресурсов, информационно-поисковые системы (в том числе и Internetмашины) могут быть разделены на следующие классы:
-локальные системы – локализованные данные и их обра-
ботка;
-частично-распределенные – локальная обработка распределенных данных;
-полностью распределенные системы, где реализуются принципы распределенных вычислений и распределенного хранения данных.
Локальные системы обеспечивают доступ удаленных пользователей к ресурсам, сосредоточенным на поисковом сервере. Эти
207
системы в большинстве случаев функционально эквивалентны локальным системам, например, на CD-ROM-носителях.
Ко второму типу относятся системы, использующие данные, которые находятся на Web-серверах, в качестве распределенных первичных ИР; вторичные и индексные данные сосредоточены на поисковом сервере, осуществляющем обслуживание пользовате-
лей. Это такие системы, как AltraVista, Google, Yandex и пр.
К третьему типу относятся системы, в которых процесс поиска реализуется на совокупности серверов, распределенных по сети, которые при обработке запроса опрашивают друг друга, причем исходные и промежуточные данные поиска также имеют распределенный характер.
По тематическому и видовому спектрам ИР могут быть однородными (иметь четко выраженную тематику и работать с документами определенного типа и состава) и гетерогенными (политематическими и не имеющих требований к составу и форме документов).
По способу формирования ИР подразделяются на те, которые используют предопределенные источники, например публикации издательств, рецензирующих материалы, и те, которые используют все свободно доступные материалы. Примерами здесь, соответственно, являются базы данных научной информации и поисковые машины Internet, индексирующие открытые HTML-страницы.
Если рассматривать электронные библиотеки в этом контексте, то можно заметить, что в качестве компонентов здесь выступают электронные каталоги (библиографические и реферативные базы данных), полнотекстовые массивы (электронные журналы, фактографические базы данных, хранилища электронных копий источников в том или ином виде и т.д.), справочно-нормативные файлы (рубрикаторы, тезаурусы, авторские, предметные, географические и другие указатели), возможно связанные между собой ссылками, указателями хранения или условиями поиска, хотя уже по своей сути эти компоненты всегда были и будут связаны, по крайней мере, на концептуальном уровне. Например, записи электронных каталогов содержат указания местоположения книг, а справочно-нормативные файлы традиционно используются в качестве «точек входа» в библиографические и реферативные базы дан-
208
ных. С появлением технических возможностей создания полнотекстовых баз данных справочно-поисковый аппарат и собственно массив информации технологически становятся единым целым, а на первый план выходит задача организации такой взаимосвязи, чтобы переход по ссылке от компонентов одного уровня к компонентам другого воспринимался пользователем как простейший одномоментный процесс, подобно перевороту страницы книги.
Сорганизационной же точки зрения ЭБ помимо справочнопоискового сервиса обычно включает службу электронной доставки, обеспечивающую нахождение (или изготовление) и предоставление копий документов.
Сточки зрения характера и формы представления информации (и, соответственно, логики организации поиска) архитектура ИР включает три уровня: уровень собственно документов (полных текстов), уровень поисковых образов и метаинформационный уровень. Характер и логика взаимосвязей информационных элементов отдельных уровней отражен схемой на рис. 8.1, где в скобках даны примеры, характерные для автоматизированных или традиционных информационных систем.
Взаимосвязь между компонентами разных уровней может быть реализована как для компонентов в целом, так и для их элементов. Иллюстрацией служит, например, такая связь, как «библиографическая запись электронного каталога – запись полнотекстовой базы данных» или «библиографическая запись - оцифрованная копия источника (изображение)». К другому типу (на уровне элементов) могут относиться такие связи, как «пристатейная ссылка – библиографическая запись» или «фрагмент библиографической записи – запись нормативной базы данных» и т.д. Как говорится, все в этом мире взаимосвязано. Однако вербально или алгоритмически выразить эту взаимосвязь иногда весьма сложно.
Рассматривая эту схему как «технологию» поиска, можно видеть, что ссылки вполне узнаваемы и представляют собой традиционные правила и приемы отыскания информации в условиях «бумажной» библиотеки, когда поиск начинается с классификационной схемы или указателя, далее через библиографические карточки к первоисточнику, где, используя пристатейные ссылки и указатели, снова продолжается с метаинформационного уровня.
209
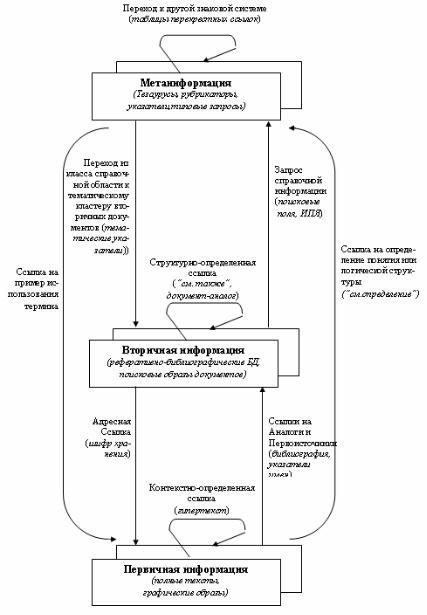
Рис. 8.1. Характер взаимосвязей информационных элементов
210