

Ajax Patterns And Best Practices (2006)
.pdfC H A P T E R 5 ■ P E R M U T A T I O N S P A T T E R N |
149 |
GET /shoppingcart HTTP/1.1 Host: 192.168.1.103:8100
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.0; en-US; rv:1.7.5) Gecko/20041220 K-Meleon/0.9
Accept: application/xml
Authorization: Digest username="cgross", realm="Private Domain", nonce="yiLhlmf/AwA=e1bafc57a6151c77e1155729300132415fc8ad0c",
uri="/browse/authenticate", algorithm=MD5, response="c9b5662c034344a06103ca745eb5ebba", qop=auth, nc=00000001, cnonce="082c875dcb2ca740"
The request is an illustration of doing multiple things at the same time and contains both authorization and representation information. The server would generate a response similar to the following:
<dir xmlns:xlink="http://www.w3.org/1999/xlink"> <cart
xlink:href="cgross/cart1"
xlink:label="cart1" xlink:title="Shopping Cart 1" />
<cart
xlink:href="cgross/cart2"
xlink:label="cart2" xlink:title="Shopping Cart 2" />
<cart
xlink:href="cgross/cart3"
xlink:label="unlabelled" xlink:title="Unlabelled Shopping Cart" />
</dir>
The newly generated response contains a directory listing of all shopping carts associated with the individual user cgross. The links cgross/cart1 and cgross/cart2 represent already created and manipulated carts. The link cgross/cart3 is a new cart that could be used to buy other items. The already existing carts could be old shopping experiences or shopping carts that are waiting for checkout. The big idea is that it is possible to have multiple carts that could be manipulated at different times. Or the server could implement repeat purchases based on a past shopping cart, wish lists, and so on. Using server-based carts allows a website to perform automations.
The example illustrated the available carts being generated for those who want to manipulate XML. If a browser references the shopping cart URL link, the following HTML content would be generated:
<html>
<body>
<a href="cgross/cart1" label="cart1">Shopping Cart 1</a> <a href="cgross/cart2" label="cart2">Shopping Cart 2</a>
<a href="cgross/cart3" label="unlabelled">Shopping Cart 1</a> </body>
</html>
150 |
C H A P T E R 5 ■ P E R M U T A T I O N S P A T T E R N |
Notice how the generated content is HTML, but that a directory listing is still generated similar to the generated XML.
Shopping carts are personal items that do not need to be associated with a generic link. Shopping carts have unique URLs that can be entirely anonymous or be associated with a user. The shopping cart illustrates how it is unnecessary to have generic URLs yet still be able to offer the same functionality, even if the user has turned off cookies.
Pattern Highlights
The purpose of the Permutations pattern is to define a component-type structure for Web applications that can be associated with a user identifier. Web applications can implement an interface-driven architecture, where the resource mimics an interface, and representation mimics an implementation. The added benefit for the developer is the ability to modularize a web application in a consistent structure.
The benefit of the pattern is best illustrated by looking at Figure 5-7, where some URLs implement the Permutations pattern, and others do not. The URLs that implement the Permutations pattern are the reference URLs that clients use when accessing their functionality. A reference URL would be a user’s bank account, shopping cart, and so on. Those URLs that are part of the implementation are specific and will generally not be bookmarked by the user.
The following points are the important highlights of the Permutations pattern:
•There are two aspects of the Permutations pattern: resource separated from representation, and the definition of URLs that reference specific resources.
•Separating a resource from a representation means providing a generic URL that can be used on multiple devices or browser types. The end user needs to remember only the URL, and the appropriate content will be generated by the server, depending on the HTTP headers of the HTTP request.
•When implementing the separation of the resource from the representation, URL rewriting is commonly used. For example, the resource URL http://mydomain.com/resource is redirected to a potential representation URL http://mydomain.com/resource/content.html.
•Redirected resources such as content.html do not need multiple representations. When a resource has an extension such as html, it is implied that the representation is HTML.
•When defining resource URLs, they will often reference data resources such as users or bank accounts. The resource URLs are noun based, for example, http://mydomain.com/ bankaccount/maryjane. The URL rewriting component then has the additional responsibility of ensuring those who access a noun-based, resource-based URL have the security clearance. Security clearance is determined by the user identifier. User identifiers are not used to generate content, but to allow or disallow access to a resource.
•Cookies and HTTP authentication mechanisms are the preferred means used to implement user identification.
C H A P T E R 5 ■ P E R M U T A T I O N S P A T T E R N |
151 |
•Sometimes when implementing the Permutations pattern it is not possible or desirable to return content solely based on the Accept HTTP header. In those instances, it is possible to specify the content that is retrieved by using a parameter in the query. An example is http://mydomain.com/mybooks/1223?accept=text/xml. The query parameter accept is an arbitrary value and has no special value other then being illustrative in this example.
•Even though all of the examples used HTTP GET to retrieve the correct content, the same rules apply for HTTP POST because an HTTP POST can generate data.
•A URL rewriter component need not use only a single HTTP header such as Accept. A more sophisticated URL rewriter component will base its decisions on all information passed to it by the HTTP request and then make a single URL rewrite decision.

C H A P T E R 6
■ ■ ■
Decoupled Navigation Pattern
Intent
The Decoupled Navigation pattern defines a methodology for decoupling client-side code and navigation into smaller modular chunks, making the client-side content simpler to create, update, and maintain.
Motivation
The basis of any web application is its capability to link together two pieces of content. An HTML link, for example, is a one-way link in that clicking it sends you from content A to content B. There is no built-in HTML mechanism that provides a bidirectional link to connect content B with content A. In theory, when clicking on a link that loads another page, there is no way to get back to the original page. A web browser solves that problem by providing a history of navigated pages. Pressing the Back button on the web browser causes the web browser to look in the history and load the previously visited page.
The link is the basis of the web application, and without the link the Web would not be the Web. However, the link that was the default navigation mechanism in 1995 is not the same link more than a decade later. Let me rephrase that statement: the technical implementation of the link has not changed, but what has changed is how the link is used. With the advent of Dynamic HTML, Ajax, REST, and all the other technologies, the link has taken on a new kind of importance.
For most of the other patterns in this book, the link was a URL that was loaded. The patterns focused on defining a good URL and using the URL, but did not consider how to process a URL or a link on an HTML page.
The classical link that links one HTML page to another is illustrated in Figure 6-1.
Figure 6-1 shows two types of links: the classical link and the static GUI link. A classical link is a construct that has some defined text surrounded by special HTML tags that when processed by a web browser cause the text to be highlighted. The special HTML tags for the classical link include an a tag that contains a reference to a URL. A static GUI link is like a classical link except that an image is used instead of some defined text.
153

154 |
C H A P T E R 6 ■ D E C O U P L E D N A V I G A T I O N P A T T E R N |
Figure 6-1. Example of a classical link and a static GUI link
Clicking the classical link or static GUI link causes the current HTML page to be replaced with a new HTML page. The links are obvious to the human eye, because they tend to be distinguished from other content on the HTML page by using boldface or underlining. When a search engine processes a link, the link is used to provide connection to other content that is indexed. Figure 6-2 illustrates what a search engine sees when processing an HTML page.

C H A P T E R 6 ■ D E C O U P L E D N A V I G A T I O N P A T T E R N |
155 |
Figure 6-2. HTML page structure with respect to a search engine
In Figure 6-2, the links of Figure 6-1 have been explicitly highlighted and illustrate that most HTML pages have a multitude of links. A search engine sees many more links than we realize. The point is that links have changed in their nature, complexity, and sheer number.
Figure 6-3 illustrates a more complicated GUI with links that do more than provide a way to navigate content as a classical link does.

156 |
C H A P T E R 6 ■ D E C O U P L E D N A V I G A T I O N P A T T E R N |
Figure 6-3. More-complicated HTML page structure
Figure 6-3 shows three types of links: classical, user interaction, and dynamic GUI. A classical link has already been explained. A user interaction link is used when the result of content navigation depends on what the user provides as data. In Figure 6-3, the user interaction link is a text box used to define a query that executes a search. The results of the search depend on the content of the query string. The dynamic GUI link is a short-circuited link that when clicked will execute some logic resulting in the navigation of content, generation of images, or some other visual effect.
Figures 6-1 and 6-2 show links of the traditional or initial Web, and Figure 6-3 shows links of the modern Web. The modern Web has changed what it means to navigate content, in that information is navigated. Navigating information is more complicated because determining what information is navigated requires client-side logic. In Figure 6-3, not all links are created equal from a logic perspective. Some links are more complicated, and that is the focus of the Decoupled Navigation pattern.
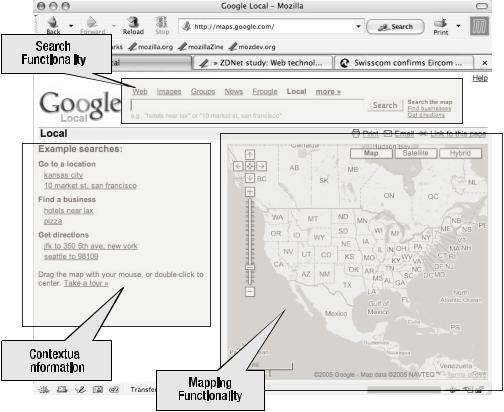
Figure 6-4 dissects the HTML content of Figure 6-3 into individual content chunks.
|
|
|
C H A P T E R 6 ■ D E C O U P L E D N A V I G A T I O N P A T T E R N |
157 |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Figure 6-4. Dissected functionality of HTML page
This HTML page has three types of content chunks: searching, mapping, and contextual. The content chunks are not—and do not need to be—independent of each other. In Figure 6-4, the contextual information is generated based on what is displayed in the mapping chunk. And the searching chunk, when executed, generates content for the mapping and contextual chunks. What is interesting about these chunks is that they are related, because each chunk generates links that depend on the context of the content in the other chunk.
Applicability
The Decoupled Navigation pattern is used when content is navigated. The statement is obtuse and does not really say anything because HTML content is always navigated. However, because of the way Dynamic HTML is used, content navigation is sometimes used to generate an effect. When links are used to generate effects, the Decoupled Navigation pattern does not apply.
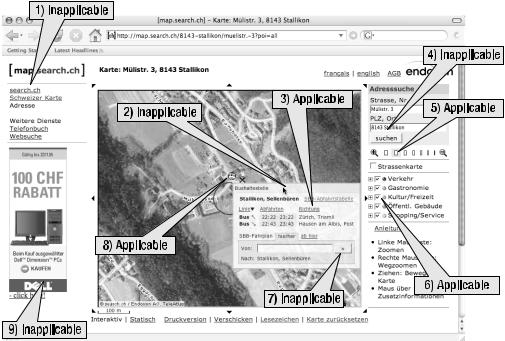
To clarify this explanation, Figure 6-5 provides a snapshot of a website that illustrates where the Decoupled Navigation pattern is applicable and not applicable.
158 |
C H A P T E R 6 ■ D E C O U P L E D N A V I G A T I O N P A T T E R N |
Figure 6-5. Applicable and not applicable scenarios of the Decoupled Navigation pattern
The individual scenarios are explained as follows:
1.Inapplicable: The link is inapplicable because it references another link that wishes to start a new context unrelated to the current content. This scenario is comparable to when a user runs one application and then starts another application.
2.Inapplicable: The pop-up dialog box has a title bar that in some cases allows the pop-up to be dragged by using a mouse. The act of dragging is purely a user interface action that at the technical level uses HTML events and navigation techniques.
3.Applicable: The link referenced in the pop-up dialog box is visually identical to scenario 1, but when clicked the actions are not. This link-click is caught as an event and processed by using a JavaScript function. The JavaScript function processes the link context and loads content that relates to the context. In a sense, this scenario and the first scenario are related because under normal circumstances the referenced content is unrelated to the current content. The difference is that the JavaScript function intelligently decides what should be loaded, thus relating the current context to the new context.
4.Inapplicable: The link referenced by this scenario is an HTML form. By its nature an HTML form is designed to change contexts and replace the old context with a new context. However, HTML forms can function like the link in scenario 3. To make this scenario applicable, the form event onsubmit would need to be processed.