

А.В. Бирюков Статистический анализ и факторный эксперимаент
.pdfМинистерство образования Российской Федерации Кузбасский государственный технический университет
Кафедра высшей математики
СТАТИСТИЧЕСКИЙ АНАЛИЗ И ФАКТОРНЫЙ ЭКСПЕРИМЕНТ
Методические указания к применению статистических методов в исследованиях для студентов, аспирантов и научных работников всех направлений
Составители А.В. Бирюков И.А. Паначев
Кемерово 2000
2
Министерство образования Российской Федерации Кузбасский государственный технический университет
Кафедра высшей математики
СТАТИСТИЧЕСКИЙ АНАЛИЗ И ФАКТОРНЫЙ ЭКСПЕРИМЕНТ
Методические указания к применению статистических методов в исследованиях для студентов, аспирантов и научных работников всех направлений
Составители А.В. Бирюков И.А. Паначев
Утверждены на заседании кафедры Протокол № 3 от 3.03.2000
Рекомендованы учебно-методической комиссией специальности 290300 Протокол № 8 от 4.04.2000
Электронная копия находится в библиотеке главного корпуса КузГТУ
Кемерово 2000

3
ПРЕДИСЛОВИЕ
Статистика исследует часть генеральной совокупности, называемую выборкой. Высказывание о том, что две выборки принадлежат одной и той же генеральной совокупности, называется нуль–гипотезой. При этом возможны два вида ошибок: отклонение верной гипотезы и принятие неверной гипотезы. Вероятность первой из этих ошибок называют уровнем значимости.
Наряду с методами проверки статистических гипотез ниже рассмотрены некоторые вопросы планирования факторного эксперимента. В последнем пункте сосредоточены таблицы критических значений основных статистик для уровня значимости 0,05.
1. ИСКЛЮЧЕНИЕ ОШИБОК
В выборке сомнительными могут быть ее крайние элементы, т.е. самый большой или самый малый. Если Х – крайний элемент, А – выборочное среднее, S – выборочный стандарт (корень квадратный из дисперсии), то искомая статистика имеет вид
Х − A S |
(1) |
Крайний элемент отбрасывается как ошибочный, если найденное значение (1) превосходит критическое. В табл. 1. приведены критические значения этой статистики, зависящие от объема выборки N.
2. НОРМАЛЬНЫЕ ВЫБОРКИ
Выборка называется нормальной, если она извлечена из нормально распределенной генеральной совокупности. Проверка выборки на нормальность состоит в вычислении статистики
R S, |
(2) |
где R, S – размах и стандарт выборки.
Если найденное значение (2) принадлежит критическому интервалу (Х1; Х2), то выборку можно считать нормальной. В табл. 2 приведе-
4
ны значения границ критического интервала в зависимости от объема выборки N.
3. СРАВНЕНИЕ ДИСПЕРСИЙ
3.1. КРИТЕРИЙ ФИШЕРА
Для двух нормальных выборок объемом N1, N2 с дисперсиями S12 и S22 проверяется нуль–гипотеза: обе выборочные дисперсии являются оценками одной и той же генеральной дисперсии или, другими словами, различие между дисперсиями незначимо (случайно). Искомой статистикой является отношение
S2 |
S2 |
, |
(S2 |
> |
S2 ) |
(3) |
1 |
2 |
|
1 |
|
2 |
|
Нуль–гипотеза отклоняется, если значение отношения (3) превосходит критическое. В табл. 3 приведены критические значения статистики Фишера в зависимости от объемов выборок.
3.2. КРИТЕРИЙ ХАРТЛИ
Имеется К нормальных выборок одинакового объема N. Проверяется нуль – гипотеза: дисперсии всех выборок являются оценками одной и той же генеральной дисперсии, т.е. отличаются друг от друга незначимо. Статистика Хартли равна отношению наибольшей дисперсии к наименьшей:
maxS2 minS2 |
(4) |
Нуль–гипотеза отклоняется, если найденное значение статистики
(4) превосходит критическое. В табл. 4 приведены критические значения статистики Хартли в зависимости от K и N.
3.3. КРИТЕРИЙ КОКРЕНА
Имеется K нормальных выборок одинакового объема N. Когда одна из выборочных дисперсий значительно больше остальных или когда K > 12, предпочтителен критерий Кокрена со статистикой, равной отношению наибольшей дисперсии к сумме всех остальных:
maxS2 ∑ S2 |
(5) |

5
Нуль–гипотеза отклоняется, если значение статистики (5) превосходит критическое. В табл. 5 приведены критические значения статистики Кокрена в зависимости от K и N.
3.4. КРИТЕРИЙ ПИЛЛАИ
Рассмотренные критерии сравнения дисперсий предполагают нормальность выборок. Для двух произвольных выборок одинакового объема N с размахами R1 и R2 проверка нуль–гипотезы может быть проведена по критерию Пиллаи со статистикой
R1 R 2 , |
(R1 > R 2 ) |
(6) |
Если это отношение превосходит критическое, то нуль–гипотеза отклоняется. Критические значения статистики (6) в зависимости от N приведены в табл. 6.
4. СРАВНЕНИЕ СРЕДНИХ
4.1. КРИТЕРИЙ СТЬЮДЕНТА
Для двух нормальных выборок объемом N1 и N2 проверяется нульгипотеза: средние выборок являются оценками одного и того же генерального среднего. Если дисперсии выборок отличаются незначимо и средняя дисперсия равна S2 , то искомая статистика имеет вид
ST[(N1 + N2 ) N1N2], |
(7) |
где T – значение критерия Стьюдента.
В табл. 7 приведены значения этого критерия в зависимости от объема выборок. Нуль-гипотеза отклоняется, если абсолютная величина разности между выборочными средними превосходит значение статистики
(7).
4.2. КРИТЕРИЙ ЛОРДА
Для двух произвольных выборок одинакового объема N со средними значениями A1 и A2 и размахами R1 и R2 проверяется нульгипотеза: средние значения выборок являются оценками одного и того же генерального среднего. Соответствующая статистика имеет вид

6 |
|
2 A1 − A2 (R1 + R 2 ) |
(8) |
Если найденное значение этой статистики превосходит критическое (табл. 8), то нуль-гипотеза отклоняется.
4.3. КРИТЕРИЙ ДИКСОНА
Пусть имеется K выборок равного объема со средними
A1 > A2 > … > Aк.
Требуется установить, значимо ли отличается наибольшее среднее от остальных. При A1 < A2 < … < Aк аналогичный вопрос относится к наименьшему среднему. Ответы на эти вопросы дает статистика Диксона
A1 − A2 A1 − Ak |
(9) |
Если найденное значение статистики (9) превосходит критическое (табл. 9), то экстремальное среднее значимо отличается от остальных.
5. СРАВНЕНИЕ ДВУХ ПРОИЗВОЛЬНЫХ НЕЗАВИСИМЫХ ВЫБОРОК ПО КРИТЕРИЮ ВИЛКОКСОНА
Проверяется нуль-гипотеза: обе выборки принадлежат одной и той же генеральной совокупности. Выборки объемом N1 и N2 объединяем в одну совокупность и располагаем элементы по возрастанию, помечая (например, штрихом) элементы одной из них. В объединенной совокупности элементы нумеруются в порядке возрастания. Номер элемента называется его рангом. Одинаковым по величине элементам приписывается средний в их группе ранг. Далее подсчитываются суммы рангов элементов каждой выборки B1 и B2 и находятся величины
U1 = |
N1N2 + 0,5 N1 (N1 + 1) − |
B1 |
U2 = |
N1N2 + 0,5 N2 (N2 + 1) − B2 |
|
Искомая статистика равна наименьшему из чисел U1, U2, т.е. |
||
|
U = min (U1 , U2 ) |
(10) |

7
Нуль-гипотеза отклоняется, если значение статистики (10) меньше критического (табл. 10).
6. СРАВНЕНИЕ НЕСКОЛЬКИХ ВЫБОРОК ПО КРИТЕРИЮ КРАСКЕЛА-ВАЛЛИСА
Пусть имеется K произвольных выборок объемом N1, N2, … , Nк. Проверяется нуль-гипотеза: все выборки принадлежат одной и той же генеральной совокупности. Для проверки этой гипотезы, как и в п. 5, объединяем все выборки в одну совокупность, располагая элементы по возрастанию и помечая их как-либо для каждой выборки. После ранжировки элементов подсчитываем сумму рангов для каждой выборкиBi (i = 1, 2,..., K). Искомая статистика имеет вид
12 |
K |
(Bi2 Ni ) − 3(N |
+ 1), |
(11) |
|
∑ |
|||
N(N + 1) i= 1 |
|
|
|
|
где N = N1 + N2 + …+ Nk.
Нуль-гипотеза отклоняется, если значение статистики (11) больше критического (табл. 11).
7. КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ
Имеется N одновременных наблюдений за двумя случайными величинами. Коэффициент корреляции является показателем того, насколько связь между этими величинами близка к линейной. Его выборочная оценка имеет вид
(E − F) S1S2 , |
(12) |
где E – среднее произведение значений случайных величин, F – произведение средних значений случайных величин, S1 и S2 - стандарты случайных величин. Корреляция значима (неслучайна), если значение статистики (12) превосходит критическое (табл. 12).
8. РАНГОВАЯ СТАТИСТИКА СПИРМЕНА
Коэффициент ранговой корреляции Спирмена имеет вид
8 |
|
1− 6(D12 + ... + D2N ) N(N2 − 1), |
(13) |
где N – количество пар наблюдений за двумя случайными величинами. Для его вычисления оба ряда значений ранжируются и находятся разности рангов Di (i = 1, 2,..., N) у соответствующих пар значений случай-
ных величин. Корреляция признается значимой, если найденное значение статистики (13) превосходит критическое (табл. 13).
9.ФАКТОРНЫЙ ЭКСПЕРИМЕНТ
При построении многофакторной регрессионной модели изучаемого процесса каждый фактор варьируется на двух уровнях (нижнем и верхнем), охватывающих весь рабочий диапазон значений фактора. Значения факторов нормируются таким образом, что нижнему уровню соответствует значение (-1), а верхнему – (+1). Так, например, при изучении влияния фактора в диапазоне 10 ≤ Х ≤ 70 нормированные значения составляют (Х − 40)  30 , где 40 – середина интервала варьирования,
30 , где 40 – середина интервала варьирования,
а 30 – половина размаха значений. Таким образом, для нижнего и верх-
него уровней получим (10 – 40) / 30 = -1, (70 – 40) / 30 = +1.
Рассмотрим план эксперимента с двумя факторами Х1, Х2 и выходным параметром Y. В этом случае полный факторный эксперимент содержит 4 опыта со всевозможными сочетаниями уровней факторов:
|
№ |
X1 |
X2 |
X1X2 |
Y |
|
1 |
+ |
+ |
+ |
Y1 |
||
2 |
− |
+ |
− |
Y2 |
||
3 |
+ |
− |
− |
Y3 |
||
4 |
− |
− |
+ |
Y4 |
||
Здесь уровни факторов упрощенно обозначены через (-) и (+). Результаты эксперимента, проведенного по такому плану, позволяют построить регрессионную модель вида Y = H0 + H1X1 + H2 X2 + H12 X1X2 ,
где коэффициенты H1 и H2 называются линейными эффектами факторов, а коэффициент H12 - эффектом парного взаимодействия факторов. При этом

H H H H
0
1
2
12
=
=
=
=
9
(Y1 + Y2 + Y3 + Y4 )  4 (Y1 − Y2 + Y3 − Y4 )
4 (Y1 − Y2 + Y3 − Y4 )  4 (Y1 + Y2 − Y3 − Y4 )
4 (Y1 + Y2 − Y3 − Y4 ) 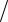 4 (Y1 − Y2 − Y3 + Y4 )
4 (Y1 − Y2 − Y3 + Y4 ) 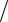 4
4
Пусть один из четырех опытов продублирован 3 раза и соответствующая дисперсия параллельных наблюдений (уровень шума) равна S2. Тогда коэффициент регрессионной модели является значимым, если его абсолютная величина превосходит 2S.
10. ПРИМЕРЫ
1) Исключение ошибок
Имеется выборка 2, 3, 3, 4, 8, у которой N = 5, A = 4, S2 = 5,5, S = 2,34. Сомнительный элемент X = 8. Значение статистики (1) 8 − 4 2,34 = 1,71 меньше критического, равного 1,87 (табл. 1). Следова-
тельно, сомнительное значение нельзя отбрасывать как ошибочное.
2) Нормальность выборки
Имеется выборка 1, 2, 3, 3, 4, 5, 10 с параметрами N = 7, R = 9, S = 2,9. Значение статистики (2), равное 3,1 принадлежит критическому интервалу (2,40; 3,22) (табл. 2). Следовательно, данную выборку можно считать нормальной.
3) Сравнение дисперсий Имеются 3 выборки одинакового объема: (1, 2, 2, 5, 6, 8), (2, 3, 4,
4, 5, 6), (1, 1, 3, 5, 5, 9). Отношение стандарта к размаху для каждой выборки принадлежит критическому интервалу (табл. 2), что позволяет считать данные выборки нормальными. Их дисперсии равны 7,6; 2,0; 9,2. Значение статистики Хартли, равное 9,2 / 2 = 4,6, не превосходит критическое, равное 10,8 (табл. 4). Следовательно, дисперсии данных выборок отличаются незначимо.
4) Сравнение средних Имеются две выборки (1, 2, 2, 4, 6), (2,3, 4, 4, 7) равного объема
N = 5 со средними A1 = 3, A2 = 4 и размахами R1 = 6 – 1 = 5, R2 = 7 – 2 =

10
= 5. Статистика Лорда 2 4 − 3 / 10 = 0,2 не превосходит критического значения 0,613. Поэтому средние выборки отличаются незначимо.
5) Сравнение двух выборок Случайная величина – число автомобилей, проходящих за минуту
через некоторый участок дороги. Две серии наблюдений проведены в начале и конце рабочего дня: (31, 18, 6, 9, 3, 2, 2, 9, 27, 30), (19, 4, 23, 22, 2, 4, 5, 50, 1, 10). Сравним эти выборки по критерию Вилкоксона. В объединенной выборке расположим элементы по возрастанию, приписывая им ранги и помечая штрихом элементы второй выборки:
Элемент |
|
|
|
′ |
2 |
′ |
2 |
2 |
3 |
|
4 |
′ |
4 |
′ |
5 |
′ |
||
|
|
|||||||||||||||||
|
1 |
|
|
|
|
|
||||||||||||
Ранг |
|
|
1 |
3 |
|
3 |
|
3 |
5 |
6,5 |
6,5 |
8 |
|
|||||
|
|
|
|
|||||||||||||||
Элемент |
|
6 |
9 |
|
9 |
10 |
′ |
18 |
19 |
′ |
|
22 |
′ |
|
|
′ |
||
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
23 |
|||||||||||
Ранг |
|
|
9 |
10,5 |
10,5 |
12 |
13 |
14 |
|
15 |
|
|
16 |
|||||
|
|
|
|
|||||||||||||||
Элемент |
|
27 |
30 |
31 |
50 |
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|||||||||
Ранг |
|
|
17 |
18 |
|
19 |
20 |
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
||||||||
Подсчитываем суммы рангов B1 = 108, B2 = 102 и находим величины U1 = 47, U2 = 53. Искомая статистика U = 47 превосходит критическое значение, которое при N1 = N2 = 10 равно 27. Следовательно, нуль-гипотеза не отклоняется, т.е. обе выборки принадлежат одной и той же генеральной совокупности. Другими словами, интенсивности автомобильных потоков в начале и конце рабочего дня отличаются незначимо (случайно).
6) Коэффициент ранговой корреляции Спирмэна
Имеются пары наблюдений за двумя случайными величинами: (5; 6), (8; 3), (7;9), (4;2), (10;12). После ранжировки имеем:
Элемент |
|
5 |
8 |
7 |
4 |
10 |
||
|
||||||||
Ранг |
|
|
2 |
4 |
3 |
1 |
5 |
|
|
||||||||