

2.4.4 Частотная модель
Частотная модель взвешивания терминов тесно связана с частотным методом индексирования. Одна из наиболее известных весовых функций записывается следующим образом :
![]()
Здесь Wi – вес, приписываемый термину терминаti,
(TF)i– частота термина в документе,
(IDF)i– обратная документная частота.
Также на практике широко применяется весовая функция
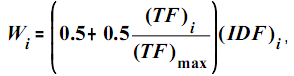
где (TF)max– максимальная частота термина вk-ом документе, то есть частота термина, который встречается в документе чаще всего. Весовой коэффициентWi отражает значимость терминаti вk-ом документе.
При использовании различительной силы терминов, их индексационные веса могут быть вычислены по формуле:
![]()
где (DV)i – значение различительной силы терминаti/
Полнота поиска здесь может быть обеспечена путем поиска высокочастотных терминов, а точность поиска определяется положительными значениями различительной силы.
2.4.5 Вероятностная модель
Недостатком частотных методоввзвешивания терминов является тот факт, что частотные веса рассчитываются формально, без учета реальных информационных потребностей.
Для того чтобы установить соответствие между истинной информационной потребностью и терминами, составляющими поисковый образ документа, разработана вероятностная модель оценки весов терминов .
Вероятностная модель основана на точной оценке вероятности того, что данный документ является релевантным (точнее, пертинентным) данному запросу .
Обозначим вероятность
такого события как
![]()
где
w1
– событие, которое состоит в
том, что документ d является релевантным
по отношению к запросу q . Аналогично,
предположим, что
![]() – вероятность того, что документ d
окажется нерелевантным.
– вероятность того, что документ d
окажется нерелевантным.
Для определения
вероятности
![]() воспользуемся теоремой Байеса:
воспользуемся теоремой Байеса:
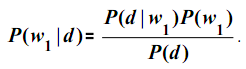
Здесь P(w1)– вероятность того, что случайно выбранный документ является релевантным,P(d)– вероятность того, что из всего множества документов для рассмотрения выбран документP(d | w1)– вероятность того, что документdвыбран из множества релевантных документов.
2.4.6 Латентно-семантический анализ
Основное предназначение взвешивания терминов, как отмечалось выше, заключается в определении того, насколько полно они отражают содержание документа. Как показывает практика, частотные методы оценки весов имеют ряд недостатков. Следствием этого является получение в результате поиска нерелевантных и отсутствие истинно релевантных документов.
Во-первых, описанные методы не учитывают тот факт, что частоты встречаемости различных терминов зависят друг от друга. Термины не появляются в документе независимо от остальных терминов, они могут быть, например, объединены в словосочетания, устоявшиеся обороты и т.п.
Другой проблемой является синонимия и полисемия(многозначность) . Подсинонимиейпонимается тот факт, что любое явление или предмет могут быть выражены различными способами. В зависимости от контекста, знаний человека, манеры письма одни и те же сведения описываются разными терминами (синонимами). Например, синонимы «дисплей» и «монитор» определяют один и тот же предмет.
Полисемия,напротив, заключается в том, что большинство слов в языке имеет несколько значений. Один и тот же термин может обозначать абсолютно разные понятия. Соответственно, наличие того или иного термина в некотором документе не означает того, что документ является релевантным запросу, в котором содержится Описанные проблемы решает латентное семантическое индексирование (ЛСИ) .
Суть этого подходасостоит в том, что каждый набор документов имеет неявную, латентную семантическую структуру, под которой понимается объединение отдельных терминов документа.
Анализ такой структуры (ЛСИ) позволяет описать каждый документ
с точки зрения наличия или отсутствия каких-либо терминов,
с точки зрения его смысла (семантической направленности). Например, документ может быть адекватно описан терминами, которые не входят в его состав, и наоборот – некоторые термины не отражают смысла документа, и совпадение их с терминами запроса не делает документ релевантным.
Таким образом, в результате количественного анализа латентных факторов веса терминов могут быть скорректированы, и поисковый образ документа станет более адекватным его содержанию.
Качество поискав ИПС, использующих ЛСИ, выше, чем в системах, где применяются только частотные методы. Латентно-семантическое индексирование позволяет также охарактеризовать документ некоторыми новыми свойствами, которые не связаны с наличием или отсутствием терминов (например, количеством библиографических ссылок на данный документ из остальных документов набора, разметкой документа (обычный текст или таблица) или, для документов Интернет, частотой обновления и посещаемостью страницы ).
Математически латентно-семантическое индексирование реализуется с помощью одного из методов линейной алгебры – сингулярного разложения матрицы[,]. Современные алгоритмы используют также аппарат теории вероятностей (вероятностное латентное семантическое индексирование) .
Одним из важных направлений ЛСИ является межязыковое латентно-семантическое индексирование(межязыковое ЛСИ) . Основным принципом здесь является тот факт, что запрос на одном языке может возвращать релевантные документы на других языках.
Рассмотрим некоторую группу документов, где каждый документ представлен на двух языках (например, немецком и английском). После проведения латентно-семантического анализа каждый документ будет описан как немецкими, так и английскими терминами в едином межязыковом семантическом пространстве. Поэтому запросы к этому набору документов, а также к вновь добавляемым в набор документам (на каком-то одном языке) можно будет делать на любом из двух языков.
Главное достоинство межязыкового ЛСИ – отсутствие необходимости перевода (ручного или машинного) запроса на другой язык. Это особенно актуально для поиска в сети Интернет, когда запросы являются неспециализированными, и их адекватный перевод вызывает значительные трудности [, , ].
Латентно-семантический анализ в настоящее время также часто применяется для анализа гипертекстовых документов. Практика показывает, что документы, связанные гиперссылками, обычно находятся в одном семантическом пространстве.
Один из латентных факторов, которым в данном случае является структура гиперссылок, существенно влияет на точность поиска .