

ТИПИС
.pdf§ 2.4. Процедура планирования |
71 |
|
шение разработчиков алгоритма А* является следствием того, что оценка g(x) с каждой итерацией увеличивается на единицу. Если даже оценка h(x) будет иметь относительно предыдущих итераций меньшее значение, то за счет роста g(x) суммарное значение f(x) будет относительно большим. Предполагается, что сравнение оценок состояний должно происходить не только на текущем фронте (как это выполняется в алгоритме А*), но и относительно оценок состояний всех ранее полученных фронтов.
В результате алгоритм поиска примет следующий вид:
1.Раскрыть очередное состояние si-1 Fj =Si.
2.Если si Si, st, то задача решена, иначе – п. 3.
3.Для всех si Si определить значение оценки f(x) и записать в память MF(x), перейти к п. 4.
В памяти MF(x) хранятся оценки f(x) всех ранее раскрытых состояний
вранжированном виде. При записи новых состояний в MF(x) их оценки ранжируются вместе с ранее раскрытыми состояниями. Причем ранее раскрытые состояния должны быть помечены.
Следует также отметить, что в механизме управления формированием памяти должна быть предусмотрена работа алгоритмов, учитывающих
наличие терминальных состояний и колец (повторов).
Отличие MF(x) от MS, применяемой в методе Мура, заключается в том, что оригинальные состояния ранжируются на основе оценки f(x), а не на основе порядка поступления.
4.Выбрать из MF(x) любое состояние si, ранее не раскрытое, для которого оценка f(x)min; если таких нет, то выбрать любое состояние, для кото-
рого f(x)min.
5. Оператор fi, образовавший очередное состояние, записать в цепоч-
ку Li = {f1, f2, … fi-1, fi, …}, далее перейти к п. 1 для состояния si.
Следует отметить, что цепочка Li в процессе поиска корректируется. В случае повторений или терминальных состояний соответствующие родительские операторы удаляются. Управление выбором состояния в алгоритме А* из текущего фронта, по сути, определяется только количеством не на месте расположенных цифр в матрице, т. е. значением h(x). По этой причине алгоритм А* обладает низкой эвристической силой и соответственно является неустойчивым к возможным проявлениям неудачи в поиске (рис. 2.16), даже с использованием памяти и процедуры возврата.
Сила эвристической информации, заложенная в оценочную функцию, должна обеспечить максимальное сужение сектора поиска, т. е. предполагается, что априорная эвристика должна способствовать тому, что во всяком сгенерированном фронте имеется лишь одно состояние (одно ре-

72 |
Глава 2. Методы поиска |
|
|
||
|
|
|
шение), для которого оценка f(x)min. Только движение по лучу, как это было показано ранее (см. параграф 2.3), позволяет выделить путь.
Для практического выполнения поиска оценочная функция для игры «В восемь» должна принять альтернативный вид:
N
f(xi) = h(xi) + g(xi)min,
i 1
где g(xi)min – величина минимального пути от текущего расположения знака до места расположения в целевом состоянии; h(xi) – оценка, представляющая отличие свойств текущего и целевого состояния.
Вданном примере h(xi) указывает на количество знаков текущего состояния, расположенных не на месте относительно целевого состояния.
Величина h(xi) изменяется в пределах от восьми до нуля. Чем меньшее значение принимает величина h(xi) в текущем состоянии, тем ближе оно расположено к целевому состоянию. Нулевое значение h(xi) указывает на то, что целевое состояние найдено.
Величина g(xi)min указывает минимальную величину пути каждого знака от текущего расположения до расположения в целевом состоянии.
Величина g(xi)min для игры «В восемь» изменяется в пределах от четырех до нуля. Чем меньшее значение принимает величина g(xi)min для некоторого знака в текущем состоянии, тем ближе оно расположено к целевому со-
стоянию. Нулевое значение g(xi)min некоторого знака указывает на то, что в целевом состоянии этот знак находится на том же самом месте.
Впроцессе поиска величина g(xi)min (в отличие от алгоритма А*) изменяется в зависимости от флуктуации оценки h(xi). Так как в матрице имеется восемь знаков, то в оценочной функции целесообразно использовать величину суммарного пути всех знаков матрицы. Суммарная вели-
чина g(xi)min может изменяться от двадцати четырех до нуля. Чем меньшее значение принимает суммарная величина g(xi)min для текущего состояния, тем ближе оно к целевому состоянию. Соответственно, нулевое значение
суммарная оценка g(xi)min указывает на то, что в целевое состояние достигнуто.
Дополнительной оценкой, позволяющей выделить единственное состояние в текущем фронте для игры «В восемь», может стать оценка относительного расположения пустого места и знака. Как известно, в игре при передвижении знака используется четырехсоседство. Так, каждый не на месте расположенный знак может характеризоваться еще и наличием соседства с пустым местом. Наличие такого соседства позволяет оценить перспективность состояния относительно иных состояний текущего фрон-

§ 2.4. Процедура планирования |
73 |
|
та. Кроме этого, дополнительно можно оценивать наличие или отсутствие отношения смежности чисел в матрице, учитывая четырехили восьмисоседства в текущем и целевом состоянии. Однако усложнение оценочной функции также может привести к неудаче поиска вследствие корреляции применяемой системы оценок
Поэтому в основе другого способа преодоления участков немонотонности лежит способ корректировки состава оценочной функции. При возникновении ситуации, представленной на рис. 2.16, следует заключить, что выбранный состав оценочной функции на текущей итерации поиска неадекватен пропорционально количеству событий, в которых состояния текущего фронта имеют тождественные оценки. В этом случае процедура планирования должна позволить изменять систему оценок в составе оценочной функции, при необходимости, по результатам каждой итерации.
В качестве примера рассмотрим работу типичной шахматной программы. Шахматные программы, в отличие от рассмотренных ранее оценочных алгоритмов, привлекают гораздо больший объем априорной информации, поскольку оценочная функция в своей организации объединяет сразу несколько оценок. Каждая оценка представляет некоторое свойство текущего состояния партии. Состоянием в этом случае является текущее расположение шахматных фигур, их значимость в организации позиции, уязвимость и т. д. Конечная функция, представляющая состояние партии, может иметь следующий вид:
F(S) = aB bR cM dC eP …, fZ,
где В (баланс) – сумма стоимостей фигур с той и другой стороны, которые подсчитываются обычным образом (пешка – 1, конь – 3, слон – 4, ладья – 5, ферзь – 9); R – величина, учитывающая относительную безопасность королей; M – величина, которая характеризует подвижность фигур; P – учитывает организацию пешечного строя и т. д.; Z – характеризует атакующие возможности позиции.
Представленные оценки являются эвристиками, характеризующими отдельные свойства шахматной позиции. Коэффициенты a, b, c, d, e, f – это эвристики, которые имеют значимость каждого признака состояния с точки зрения разработчиков программы. Обобщенная функция F(S) дает коррелированную систему оценок состояний шахматной позиции с учетом всех имеющихся признаков.
Не секрет, что в большинстве шахматных программ априори заложены варианты выигрышных путей развития игры. Причем их организация не всегда имеет четкую иерархию, хотя от организации системы признаков
74 |
Глава 2. Методы поиска |
|
|
||
|
|
|
в значительной степени зависит вычислительная сложность поиска и достоверность (оптимальность) выигрышных путей. В связи с тем, что в типичных примеру случаях необходимо учитывать корреляцию признаков в составе функции для выбора направления поиска, приходится применять встроенные алгоритмы, позволяющие поддерживать заданный уровень корреляции.
Допустимый уровень корреляции оценок поддерживается путем их перегруппировки, исключения и введения после каждого изменения состояния партии. Цель преобразований заключается в том, чтобы система признаков в составе оценочной функции адекватно отображала существенные свойства состояний.
Для подбора признаков существуют различные методы. Например, выбор признаков может быть осуществлен по критерию совместимости, минимизации внутриклассового разброса наблюдений, максимизации межклассового расстояния с учетом среднеквадратичной ошибки аппроксимации признаков, подсчета энтропии и т. д.
Наиболее распространенным и практическим способом является метод линейного преобразования исходной коррелированной системы признаков функции в новую менее коррелированную систему признаков. Суть преобразования заключается в том, что в случае возникновения ситуации, представленной на рис. 2.16, из первоначальной системы признаков удаляется признак, имеющий наименьший вес. Таким образом, формируется новая, менее коррелированная оценочная система.
Основным недостатком преобразования является то, что в результате столкновения поиска с немонотонными участками пространства поиска оценочная функция становится более абстрактной за счет удаления признака. В некоторых случаях организации пространства поиска и распределения свойств состояний такой способ корректировки системы оценки может привести к снижению эффективности поиска. Кроме этого, не всегда возможно построить четкую иерархию пространств поиска типа «часть – целое» и по виду априорной оценочной функции сделать вывод о его пригодности или полезности при дальнейшем уточнении. Так, случайные действия начинающего шахматиста могут привести к тому, что программа не сможет с заданным значением корреляции спланировать дальнейшие действия.
Для решения задач, которые не удаётся представить в виде фиксированного набора подзадач, обычно используется ранее описанный механизм обобщения видовых признаков. Таким образом, можно получить более широкий набор вариантов подпространств и вариантов решений, рассчитанных даже на новичка.
§ 2.4. Процедура планирования |
75 |
|
Альтернативным способом планирования является опережающая оценка событий. Сущность способа заключается в том, что выбор пути выполняется на основе прогноза результатов генерации двух и более последующих итераций. В таком случае точность прогнозирования пропорциональна затрачиваемому ресурсу, поэтому суть планирования заключается в выборе оптимального или минимаксного соотношения между требуемым ресурсом и глубиной анализа. Для решения этой проблемы часто используется статистическая оценка апостериорной модели, которая вычисляется на каждой итерации поиска.
Схема поиска с использованием минимаксного планирования на примере игры «Крестики-нолики» представлена на рис. 2.17.
-1 |
-2 |
X |
1 |
|
X |
|
X |
X |
X |
X |
X |
X |
0 |
0 |
X |
0 |
X |
0 |
X |
0 |
X 0 |
0 |
0 |
0 |
0 |
|
X |
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|||
6 - 5=1 |
5 - 5=0 |
6 - 5=1 |
5 - 5=0 |
4-5= -1 |
5-6= -1 |
5 - 5=0 |
5-6= -1 |
6 - 6=0 |
4-6= -2 |
||||
0 X

 0 X
0 X

5- 4= 1
 6 - 4=2
6 - 4=2
Рис. 2.17. Схема поиска минимаксным методом
Как уже было отмечено, такой способ опережающего анализа может потребовать значительного ресурса. Для экономии ресурса может быть применено отсечение пространства поиска. Например, альфа-бета (α-β) отсечение позволяет снизить ресурс необходимый для прогнозирования за счет того, что не строится все дерево решений. Основная идея принципа отсечения состоит в сравнении наилучших оценок, полученных для полностью изученных ветвей, относительно предполагаемых оценок для оставшихся.
При очередном ходе первого игрока из рассмотрения исключаются варианты, для которых оценка оказывается меньше предварительной оценки текущего варианта (оценки ). В этом случае первым игроком выполня-
76 |
Глава 2. Методы поиска |
|
|
||
|
|
|
ется -отсечение. Второй игрок не рассматривает варианты, для которых оценка оказывается больше, чем предварительная оценка текущего варианта ( -оценки): выполняется -отсечение.
Сегодня планирование подразумевает комплекс мер, осуществляемый отдельной процедурой поиска. Процедура планирования должна позволить поисковой системе исключить возникновение альтернативных вариантов в достижении цели. Для этого необходимо выполнять корректировку принятого априори способа оценки свойств состояний относительно результатов поиска, т. е. выполнять необходимые изменения в системе оценки свойств состояний путем привлечения дополнительной информации в процессе поиска. Использование в поиске дополнительной информации позволяет выделить оптимальную цепочку из возможных вариантов решений.
Взаключении параграфа выделим основные положения, характеризующие особенности планирования поиска оптимального пути. Планирование поиска может быть реализовано следующим образом:
1) на основе оценки текущего фронта, как это реализовано в алгоритме А*. В этом случае управление поиском происходит только на основе априорной информации;
2) на основе оценки всех ранее сгенерированных состояний. В этом случае управление поиском происходит на основе априорной и апостериорной информации;
3) на основе прогноза ситуации, как это реализовано в минимаксной процедуре.
Вследующем параграфе будут рассмотрены особенности n-направленного поиска.

§ 2.5. Организация n-направленного поиска |
77 |
|
§ 2.5. Организация n-направленного поиска
Современный этап развития вычислительных средств на сегодня позволяет организовать n-направленные технологии или режимы поиска. Выбор того или иного режима поиска обычно зависит от задачи, от организации пространства поиска, от распределения целевых начальных состояний и планирования работы методов поиска.
Основной целью разработки n-направленных методов поиска является снижение времени решения задачи за счет распараллеливания вычислений [24–29]. В комплекс задач для n-направленных методов также вошли задачи поиска состояний, расстояния, пути, модели распределения целевых состояний и мониторинга пространства поиска.
Первые попытки организации n-направленного поиска были скорее имитацией, так как реализация выполнялась на однопроцессорных системах. Упоминание об одной из первых попыток имитации n-направленного поиска можно встретить в [2]. Сущность данного способа заключается в том, что поиск целевого состояния осуществлялся одновременно из всех корневых вершин пространства поиска. Для повышения эффективности там же отмечается, что при n-направленном поиске лучше всего использовать способы генерации с наиболее широким фронтом, т. е. использовать круговой обзор. В этом случае гарантируется, что генерируемые фронты приблизят n-направленный поиск к эффективности свойственной методу
78 |
Глава 2. Методы поиска |
|
|
||
|
|
|
полного перебора. Следует отметить, что в [2] приведен пример применения неуправляемого поиска в n-направленном режиме. В результате в [2] отмечается, что, к сожалению, желаемого уровня эффективности поиска достигнуто не было.
Одним из способов повышения эффективности использования неуправляемого поиска в n-направленном режиме является идея предварительного разделения пространства поиска. Разделение пространства поиска осуществляется на равные подпространства в соответствии с числом начальных состояний. Причем расположение в пространстве целевых состояний не учитывается.
В качестве доказательства, позволяющего наглядно представить эффективность идеи разделения пространства поиска, можно привести следующий пример.
Пусть имеется система, состоящая из n равно распределенных в пространстве элементов. В этом случае количество возможных бинарных отношений между элементами системы будет равно r2 = n(n – 1). Если принять, что состояния системы определяются только бинарными отношениями между элементами системы, т. е. r2(ni, n j) r2(nj, ni), то количество возможных состояний системы будет 2n(n-1). Так, если n = 20, то количество состояний будет равным 2380.
Для анализа такого количества возможных состояний потребуется огромный ресурс. Значительного снижение ресурса в подобных случаях можно достичь, если только разбить пространство состояний системы на подпространства.
Систему, имеющую в своем составе 20 элементов, произвольно разобьем на пять одинаковых подсистем. Тогда число отношений в каждой из пяти подсистем будет равно 4(4 – 1) = 12, следовательно, мощность состояний подсистем будет 212, что не так уже велико в сравнение с числом состояний всей системы (2380). Далее, установив бинарные отношения между подсистемами, можно подсчитать общее число состояний организованного таким образом пространства поиска.
Очевидный недостаток такого способа организации n-направленного режима поиска – то, что разделение пространства поиска выполняется слепым способом без учета возможного расположения целевых состояний в пространстве. Кроме этого, применение слепого поиска позволяет найти решение только первой задачи поиска на графе (см. параграф 2.1).
Следующий способ организации n-направленного поиска основан на использовании простейших эвристических методов поиска, которые в n-направленном режиме поиска исключают необходимость априори разделять пространство поиска на части и, кроме этого, расширяют возмож-

§ 2.5. Организация n-направленного поиска |
79 |
|
ности поиска, т. е. позволяют решить не только первую, но и вторую задачу поиска на графе. Идея использования простейших эвристических методов поиска аналогична принципу работы интегрированной инструментальной системы SemP-A, подробно описанной в [24, 25].
Суть способа заключается в том, что организуется взаимосвязь между процедурами проверки и генерации задействованных в поиске простейших эвристических методов поиска.
Рассмотрим схему взаимодействия процедур проверки на примере параллельной работы нескольких методов поиска Мура с генерацией в ширину. Следует отметить, что в силу особенности традиционного метода ветвей и границ, он не может быть эффективно использован в n-на- правленном режиме поиска.
После любой генерации каждый из задействованных в n-на- правленном режиме поиск методом Мура должен выделить подмножество оригинальных состояний из текущего фронта и передать это множество в общую память поиска. В отличие от однонаправленного режима применения метода Мура сравнение текущих состояний фронта происходит с обобщенной памятью, которая формируется после первой итерации n-направленного режима поиска. Обобщенная память поиска наполняется оригинальными состояниями относительно всех участвующих в поиске методов. При этом повторения исключаются, как это выполняется в классическом методе Мура. Тем самым достигается максимальная эффективность применения апостериорной информации в организации n-на- правленного режима поиска методом Мура с генерацией в ширину. В последующих итерациях из обобщенной памяти также исключаются повторения. В результате в обобщенной памяти поиска формируется множество оригинальных состояний, которые должны быть раскрыты при очередной генерации. Существенным отличием n-направленного режима поиска методом Мура от однонаправленного режима является то, что управление генерацией каждого метода происходит за счет обобщенной памяти. Это позволяет значительно сократить время поиска.
Для более эффективного распределения ресурса текущие оригинальные состояния из обобщенной памяти распределяются по методам поиска по возможности равномерно. Например, если некоторое оригинальное состояние из обобщенного списка было сгенерировано сразу несколькими методами, то оно будет передано для раскрытия в тот метод, в котором после распределения текущих оригинальных состояний из обобщенной памяти попало меньше всего оригинальных состояний. Таким образом, поддерживается максимальная активность задействованных в n-направленном режиме методов поиска.

80 |
Глава 2. Методы поиска |
|
|
||
|
|
|
Реализация n-направленного поиска методом Мура на основе апостериорной информации на самом деле имитирует параллельную работу методов. В этом смысле довольно сложно разграничить данную технологию с усовершенствованием однонаправленного метода проверки. Однако бесспорным отличительным достоинством данной организации n-на- правленного поиска является эффективный алгоритм управления процедурой генерации и проверки относительно однонаправленного режима поиска Мура, полученный за счет анализа большего фронта.
Дополнительно в поиск может быть введен механизм исключения избыточного количества первоначально задействованных методов. Например, этот механизм может быть реализован на основе следующего правила. Если некоторый метод не сгенерировал оригинальных состояний или сгенерированные оригинальные состояния полностью повторяются в обобщенном множестве, то это направление можно исключить из дальнейшего поиска, так как оно полностью перекроется на последующих итерациях соседними методами.
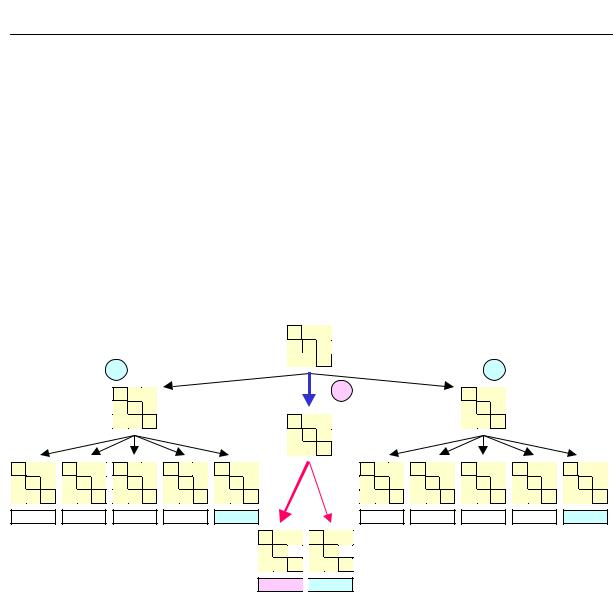
Следующая концепция организации n-направленного поиска базируется на использовании децентрализованного принципа в организации однородных баз знаний, предложенного Дэвисом и Смитом [3]. Концепция заключается в применении к решению задачи так называемой контрактной сети. Схема организации контрактной сети представлена на рис. 2.18
Контрактная сеть моделируют работу группы экспертов, способных решать совместно довольно широкий класс специфических задач. При этом каждый эксперт контрактной сети обладает точными и полными знаниями только в свой предметной области.
Дэвис и Смит отмечают, что контрактная сеть должна включать множество независимых экспертов, связанных с общим хранилищем знаний. Связи между экспертами устанавливаются и определяются только в процессе решения задачи.
Для этого эксперт должен обладать следующими знаниями:
1)о том, какие задачи он способен решить;
2)позволяющими выбрать «компаньона» на условиях оценки затрат при решении собственной задачи.
Впроцессе решения задачи каждый эксперт контролирует хранилище знаний с целью выделения в ней задач (подзадач общей задачи), на решение которых он ориентирован. При условии, что такая задача возникает, эксперт предоставляет свой накрывающий путь ее решения. К накрывающему пути (при условии приемлемой оценки затрат) могут подключаться иные эксперты сети, представляя собственные накрывающие пути решения свойственных им подзадач.