

Переваги і недоліки основних рівнів raid
|
Рівень RAID |
Механізм забезпеченнянадійності |
Ефективнамісткість масиву |
Продуктивність |
Сфера застосування |
|
0 |
- |
100% |
висока |
додатки без істотнихвимог до надійності |
|
1 |
зеркалирование |
50% |
висока або середня |
додатки без істотнихвимог до вартості |
|
3 |
парність |
80% |
середня |
додатки, що працюють з великими об'ємамиданих (графіка, CAD/CAM і ін.) |
|
5 |
парність |
80% |
середня |
додатки, що працюють з невеликими об'ємамиданих (обробка транзакцій) |
Складені raid масиви
У основних рівнів RAID є свої достоїнства і недоліки. І цілком зрозуміло, чому інженери стали мріяти про такому RAID, який би об'єднував достоїнства декількох рівнів. Складений RAID масив - це найчастіше поєднання швидкого RAID 0 з надійним RAID 1, 3 або 5. Підсумковий масив дійсно має поліпшені характеристики, але і платити за це доводиться підвищенням вартості і складністю рішення.
Складений RAID будується так: спочатку диски розділяються на набори (set). Потім на основі кожного з наборів будуються прості масиви. А завершується усе об'єднанням цих масивів в один мегамасив. Запис типу X+Y означає, що спочатку диски об'єднані в RAID рівня X, а потім декілька RAID X масивів об'єднані в RAID рівня Y.
RAID 0+1 (01) і 1+0 (10)
RAID 0+1 часто називають "дзеркалом страйпов", а RAID 1+0 - "страйпом дзеркал" (нормальне російське "чергування" практично не використовується, змінившись американізмом). У обох випадках використовуються дві технології - чергування і зеркалирование, але результати різні.
|
|
|
Структура RAID 0+1 |

RAID 0+1 має високу швидкість роботи і підвищену надійність, підтримується навіть дешевими RAID контроллерами і є недорогим рішенням. Але по надійності дещо краще RAID 1+0. Так, масив з 10 дисків (5 по 2) може залишитися працездатні пі відмові до 5 жорстких дисків!
|
|
|
Структура RAID 1+0 |
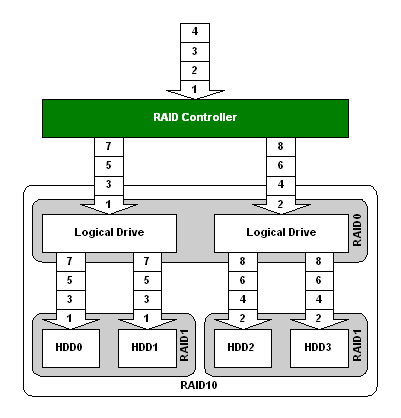
Основний недолік цих масивів - низький відсоток використання місткості накопичувачів - усього 50%. Але для домашніх систем саме RAID 01 або 10 може виявитися оптимальним рішенням.
RAID 0+3 (03) і 3+0 (30)
З цими масивами у виробників спостерігається плутанина. Досить часто замість 0+3 або 3+0 вказують привабливіше число 5+3 (53). Не вірте!
По ідеї поєднання чергування і RAID 3 дає виграш в швидкості, але він досить малий. Зате система помітно ускладнюється. Найбільш простий рівень 3+0. З двох масивів RAID 3 будується страйп, і мінімальна кількість необхідних дисків - 6. RAID 3+0, що вийшов, з точки зору надійності краще, ніж 0+3.
Достоїнства цих комбінацій в досить високому відсотку використання місткості дисків і високої швидкості читання даних. Недоліки - висока ціна, складність системи.
RAID 0+5 (05) і 5+0 (50)
Що буде, якщо об'єднати чергування з розподіленою парністю із звичайним чергуванням? Вийде швидка і надійна система. RAID 0+5 є набором страйпов, на основі яких побудований RAID 5. Така комбінація використовується рідко, оскільки практично не дає виграшу ні в чому. Широкого поширення набув складений RAID масив 5+0.
|
|
|
Структура RAID 5+0 |
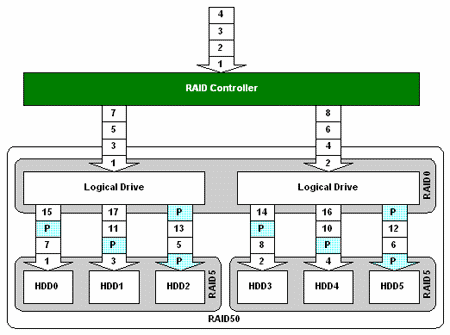
Найчастіше це два масиви RAID 5, об'єднаних в страйп. Така конфігурація дозволяє отримати високу продуктивність при роботі з файлами малого розміру. Типовий приклад - використання як WEB -сервера.
RAID 1+5 (15) і 5+1 (51)
Цей рівень побудований на поєднанні зеркалирования або дуплексу і чергування з розподіленою парністю. Основна мета RAID 15 і 51 - значне підвищення надійності. Масив 1+5 продовжує працювати при відмові трьох накопичувачів, а 5+1 - навіть при втраті п'яти з восьми жорстких дисків! Платити доводиться великою кількістю невживаної місткості дисків і загальним дорожчанням системи.
Найчастіше для побудови RAID 5+1 використовують два контроллери RAID 5, які зеркалируют на програмному рівні, що дозволяє понизити витрати.
JBOD
А що робити, якщо потрібний просто один логічний диск гігантського розміру? Без всяких зеркалирований, чергування і парності? Тоді це вже не RAID, а JBOD - Just A Bunch Of Disks. Реалізувати цей режим здатний простий контроллер або навіть програмна реалізація контроллера.
|
|
|
Об'єднання дисків в один логічний |

Чи є у нього переваги, якщо JBOD не підвищує ні швидкодії, ні надійності? Є. Принаймні, для роботи використовується увесь доступний простір жорстких дисків. І ще: у разі виходу з ладу одного з жорстких дисків, інформація на інших не ушкоджується.
Зведемо основні характеристики найбільш поширених рівнів в таблиці.
Поширені single RAID масиви
|
|
RAID 0 |
RAID 1 |
RAID 3 |
RAID 5 |
RAID 6 |
|
Технологія |
Чергування |
Зеркали-рование |
Чергування, парність |
Чергування, парність |
Чергування, парність |
|
Контроллер |
Усе |
Усе |
Апаратний |
Апаратний Hi - End |
Специали-зированный |
|
К-ть жорстких дисків |
2, 4 |
2 |
3 і більше |
3 і більше |
3 і більше |
|
Доступний робочий простір, % |
100 |
50 |
66 для 3,75 для 4 |
66 для 3,75 для 4 |
33 для 350 для 460 для 5 |
|
Стійкість при відмові диска |
Ні |
Висока |
Висока |
Висока |
Дуже висока |
|
Відновлення даних |
Ні |
Дуже швидке |
Швидке |
Швидке |
Дуже швидке |
|
Швидкість випадкового читання |
Дуже хороша |
Хороша |
Хороша |
Дуже хороша |
Дуже хороша |
|
Швидкість випадкового запису |
Дуже хороша |
Хороша |
Погана |
Нормальна |
Погана |
|
Швидкість лінійного читання |
Дуже хороша |
Хороша |
Дуже хороша |
Дуже хороша |
Хороша |
|
Швидкість лінійного запису |
Дуже хороша |
Хороша |
Хороша |
Хороша |
Середня |
|
Ціна |
Найнижча |
Низька |
Середня |
Середня |
Висока |
Поширені multi - RAID масиви
|
|
RAID 0+1 |
RAID 1+0 |
RAID 5+0 |
RAID 5+1 |
|
Технологія |
Чергування, зеркали-рование |
Чергування, зеркали-рование |
Чергування, парність |
Чергування, парність, зеркали-рование |
|
Контроллер |
Майже усе |
Майже усе |
Специали-зированный |
Специали-зированный |
|
К-ть жорстких дисків |
4 min |
4 min |
6 min |
6 min |
|
Доступний робочий простір, % |
50 |
50 |
66 для 2 страйпов по 3 диски |
33-40 |
|
Стійкість при відмові диска |
Дуже хороша |
Відмінна |
Хороша |
Відмінна |
|
Відновлення даних |
Швидке |
Дуже швидке |
Середнє |
Швидке |
|
Швидкість випадкового читання |
Дуже хороша |
Дуже хороша |
Дуже хороша |
Дуже хороша |
|
Швидкість випадкового запису |
Хороша |
Хороша |
Хороша |
Хороша |
|
Швидкість лінійного читання |
Дуже хороша |
Дуже хороша |
Дуже хороша |
Дуже хороша |
|
Швидкість лінійного запису |
Хороша |
Хороша |
Хороша |
Хороша |
|
Ціна |
Відносно висока |
Відносно висока |
Висока |
Дуже висока |
Лекція 3. Контроль цілісності інформації
Контроль цілісності програмної структурыв процесі эксплуатацииКонтроль цілісності програм і даних виконується одни-ми і тими ж методами. Виконувані програми изменяютсякрайне рідко на етапі їх експлуатації. Існує достаточноширокий клас програм, для яких усі початкові дані илиих частина також змінюються рідко. Тому контроль целостноститаких файлів виконується так само, як і контроль програм.Контроль цілісності програмних засобів і даних осуще-ствляется шляхом отримання (обчислення) характеристик і сравне-ния їх з контрольними характеристиками. Контрольні характе-ристики обчислюються при кожній зміні соответствующегофайла. Характеристики обчислюються по визначених алгорит-мам. Найбільш простим алгоритмом є контрольне сум-мирование. Контрольований файл в двійковому виді разбиваетсяна слова, що зазвичай складаються з парного числа байт. Усе двоичныеслова порозрядний підсумовується з накопиченням по mod2, утворюючи врезультате контрольну суму. Розрядність контрольної суммыравняется розрядності двійкового слова.
Алгоритм полученияконтрольной суми може відрізнятися від приведеного, але, какправило, не є складним і може бути отриманий по имею-щейся контрольній сумі і відповідному файлу.Інший підхід до отримання характеристик цілісності свя-зан з використанням циклічних кодів [63]. Суть методу со-стоит в наступному. Початкова двійкова последовательностьпредставляется у вигляді полінома F(x) міри п- 1, де п - числобит послідовності. Для того, що вибраного породжує поли-нома Р(х) можна записати равенство:110где m - міра полінома, що породжує, G(x) - частка, a R(x) -| залишок від ділення F(x) - хш на Р(х).З приведеного співвідношення можна отримати нове выра- I жение:Из останнього вираження можна зробити висновок: якщо исход-ный поліном збільшити на хш (зрушити у бік старших разів-рядів на m розрядів) і скласти із залишком R(x) по модулю 2, тополученный многочлен розділиться без залишку на порождающийполином Р(х).При контролі цілісності інформації контрольована по-следовательность (сектор на диску, файл і т. д.), зрушена на mразрядов, ділиться на вибраний поліном, що породжує, і запо-минается отриманий залишок, який називають синдромом.Синдром зберігається як еталон.
При контролі цілісності до поли-ному контрольованої послідовності додається синдром иосуществляется ділення на поліном, що породжує. Якщо остатокот ділення дорівнює нулю, то вважається, що цілісність контроли-руемой послідовності не порушена. Що виявляє спо-собность методу залежить від міри полінома, що породжує, ине залежить від довжини контрольованої послідовності. Чемвыше міра полінома, тим вище вірогідність визначення из-менений d, яка визначається із співвідношення: d =l/2m.Використання контрольних сум і циклічних кодів, як идругих подібних методів, має істотний недолік.
Алгоритм отримання контрольних характеристик добре відомий, ипоэтому зловмисник може виробити зміни таким об-разом, щоб контрольна характеристика не змінилася (напри-мер, додавши коди).Завдання зловмисника ускладниться, якщо використовувати пере-менную довжину двійкової послідовності при підрахунку кон-трольной характеристики, а характеристику зберігати в зашифро-ванном виді або зовні КС (наприклад, в ЗУ Touch Memory).Розглянемо приклад використання циклічних кодів дляконтроля цілісності двійкової послідовності.Нехай вимагається проконтролювати цілісність двоичнойпоследовательности А=1010010. Використовується породжуваний по-лином виду: Р(х)=х3+х+1.111А. Отримання контрольної характеристики.При обчисленні синдрому RA(X) дії виконуються поправилам ділення поліномів, замінюючи операцію віднімання опе-рацией складання по модулю:Двоичная послідовність з синдромом має вигляд: А' = 1010010011 (синдром підкреслений).
ПоследовательностьА' зберігається і(чи) передається в КС.Б. Контроль цілісності інформації.Якщо змін послідовності А' = 1010010011 не про-изошло, то відповідний нею поліном повинен розділитися напорождающий поліном без остатка:Результат вироблених обчислень свідчить про це-лостности інформацію.112Если синдром відмінний від нуля, то це означає, що произошлаошибка при зберіганні (передачі) двійкової послідовності.Помилка визначається і в контрольних розрядах (у синдромі).Існує метод, який дозволяє практично исключитьвозможность неконтрольованої зміни інформації в КС.Для цього необхідно використовувати хэш-функцию. Під хэш-функцией розуміється процедура отримання контрольної харак-теристики двійкової послідовності, заснована на кон-трольном підсумовуванні і криптографічних перетвореннях.Алгоритм хэш-функции приведений в ГОСТ Р34.11-94.
Алгоритм неявляется секретним, так само як і алгоритм використовуваного приполучении хэш-функции криптографічного перетворення, викладеного в ГОСТ 28147-89 [9].Початковими даними для обчислення хэш-функции являютсяисходная двійкова послідовність і стартовий вектор хэши-рования. Стартовий вектор хешування є дво-ичную послідовністю завдовжки 256 біт. Він має бути не-доступен зловмисникові.
Вектор або піддається зашифро-ванию, або зберігається зовні КС.Итерационный процес обчислення хэш-функции Н преду-сматривает:- генерацію чотирьох ключів (слів завдовжки 256 біт);- шифруюче перетворення за допомогою ключів текущегозначения Н методом простої заміни (ГОСТ 28147-89);- перемішування результатів;- порозрядне підсумовування по mod2 слів завдовжки 256 біт ис-ходной послідовності;- обчислення функції Н. В результаті виходить хэш-функция завдовжки 256 біт. Значе-ние хэш-функции можна зберігати разом з контрольованою ин-формацией, оскільки, не маючи стартового вектора хешування, зло-умышленник не може отримати нову правильну функциюхэширования після внесення змін до початкової последова-тельность. А отримати стартовий вектор по функції хэширова-ния практично неможливо.