

12. Сравнение ll – и lr – методов разбора
Как LL - , так и LR – методы разбора имеют много достоинств. Оба метода – детерминированы и могут обнаруживать синтаксические ошибки на самом раннем этапе. LR – методы обладают тем преимуществом, что они применимы к более широкому классу грамматик и языков и преобразование грамматик в них обычно не требуется. Однако, для хорошо структурированной грамматики сам факт преобразования грамматики не вызывает каких-либо технических трудностей.
Два этих метода можно сравнивать в отношении размеров таблиц разбора и времени разбора. Использование по одному слову на элемент в LL – таблице разбора позволяет свести размер типичной таблицы к минимуму, в то время как LR – разбор этой возможности не предоставляет.
Коэн и Рот сравнивали максимальное и среднее время разбора с помощью LL – и LR – анализаторов. Из данных для машин серии DEC результаты разбора LL – методом оказались быстрее на 50%.
Оба метода разбора позволяют включать в синтаксис действия для выполнения некоторых аспектов компиляции. Для LR – анализаторов такие действия обычно связаны с приведениями.
Разные разработчики компиляторов отдают предпочтение разным методам (т.е. разбору снизу вверх или сверху вниз), что постоянно служит предметом дискуссий. На практике выбор метода в основном зависит от наличия хорошего генератора синтаксических анализаторов любого типа.
13. Нормальная форма Хомского
Определение. КС–грамматика G = (N, Р S) называется грамматикой в нормальной форме Хомского (или бинарной нормальной форме), если каждое правило из Р имеет один из следующих видов:
А ВС, где А, В, С принадлежит N;
А а, где а;
S е, если еL(G), причём S не встречается в правых частях правил.
На практике каждый КС – язык порождается грамматикой в нормальной форме Хомского. Это очень полезно, когда требуется простая форма представления КС – языка.
Алгоритм преобразования к нормальной форме Хомского.
Вход. КС–грамматика G = (N, Р S).
Выход. Эквивалентная КС-грамматика G' в нормальной форме Хомского, т.е. L(G')=L(G).
Метод. Грамматика G' строится следующим образом.
Включить в Р' каждое правило из Р вида А а.
Включить в Р' каждое правило из Р вида А ВС.
включить в Р' каждое правило Sе, если оно было в Р.
для каждого правила из Р вида
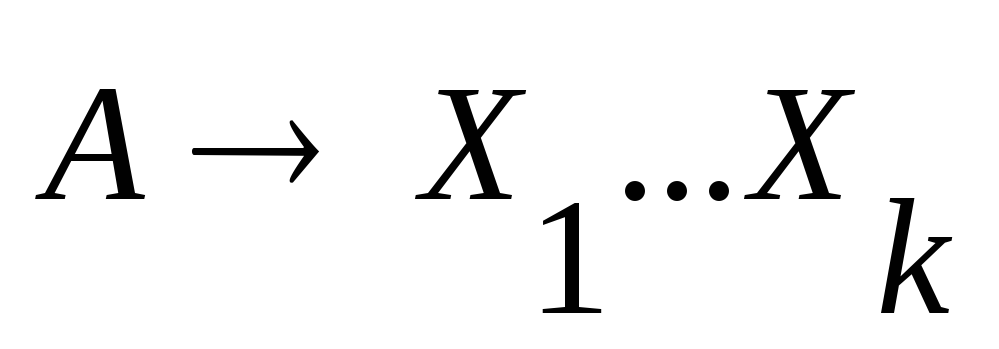 ,
гдеk
>2, включить в Р'
правила
,
гдеk
>2, включить в Р'
правила
![]()
![]()
…………………………………
![]()
![]() ,
,
где
![]() ,
если
,
если![]() ;
;![]() – новый нетерминал, если
– новый нетерминал, если![]() ;
;![]() - новый терминал.
- новый терминал.
Для каждого правила из Р вида
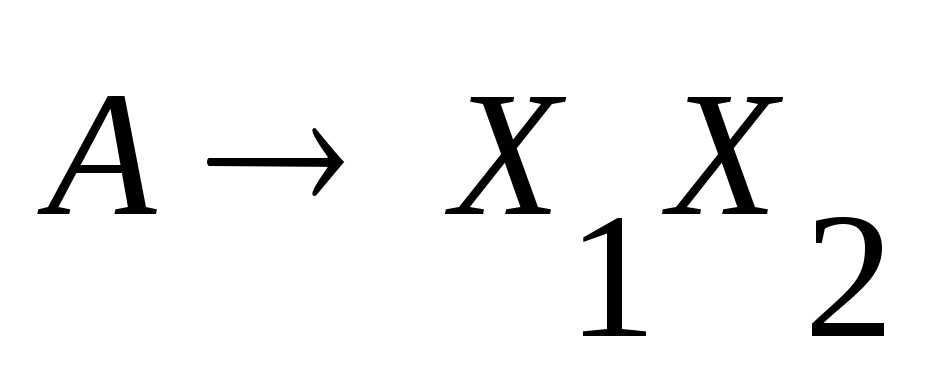 ,
где хотя бы один из символов
,
где хотя бы один из символов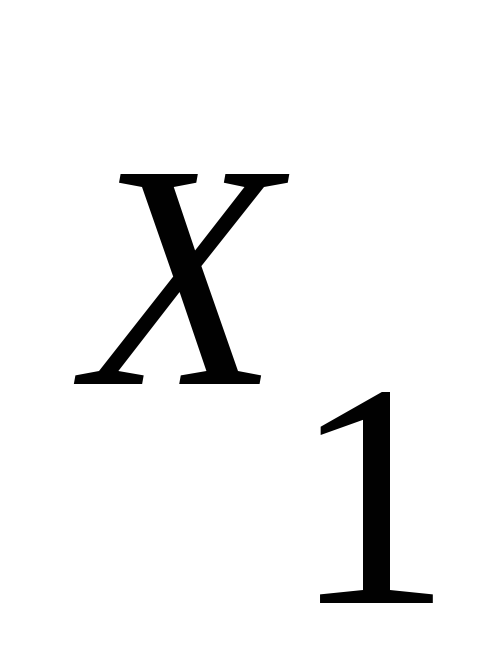 и
и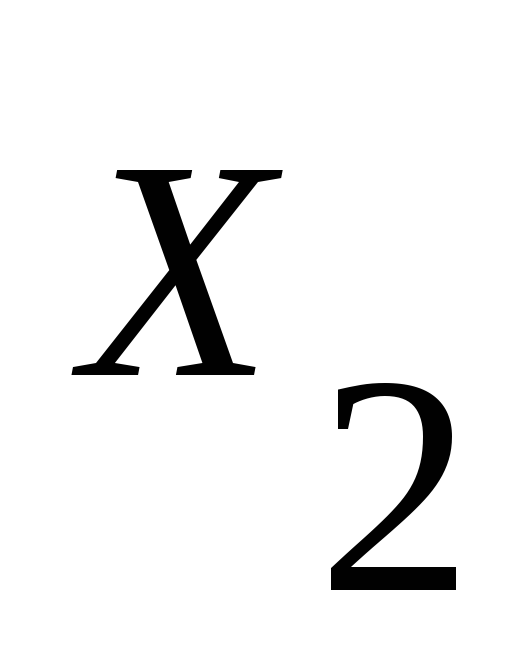 принадлежит
, включить в Р'
правило
принадлежит
, включить в Р'
правило
 .
.Для каждого нетерминала вида а', введённого на шагах 4) и 5), включить в Р' правило а'а. Наконец, пусть N' – это N вместе со всеми нетерминалами, введёнными при построении Р'. Тогда искомая грамматика G' = (N', ' Р' S).
Пример.
Пусть G – приведённая грамматика, определённая правилами
S аАВ | ВА
А ВВВ | а
В АS | b.
Строим Р' рассмотренным выше алгоритмом, сохраняя правила SВА, A а, В АS и В b. Заменяем правило S аАВ на S а'<AB> и <АВ> АВ, а А ВВВ – правилами A В<BB> и <BB>BB. Наконец, добавляем а'а. В результате получим грамматику G'= (N', {a, b}, Р', S) и Р' состоит из правил:
S а'<АВ> | BA
А В<BB> | a
B AS | b
<AB> AB
<BB> BB
a' а.