

Алгоритм.
Вход.
Помеченное упорядоченное дерево, представляющее собой оператор присвоения, включающий только арифметические операции * и +. Предполагается, что уровни всех вершин уже вычислены.
Выход.
Код в ячейке ассемблера, вычисляющий этот оператор присвоения.
Метод.
Делать шаги 1) и 2) для всех вершин уровня 0, затем для вершин уровня 1 и т.д., пока не будут отработаны все вершины.
Пусть n – лист с меткой <ИДi>.
(i) Допустим, что элемент i таблицы идентификаторов является переменной. Тогда C(n) – имя этой переменной.
(ii) Допустим, что элемент j таблицы идентификаторов является константой k, тогда C(n) – цепочка =k.
Если n – лист с меткой =, +, *, то C(n) – пустая цепочка.
Если n – вершина типа а и ее прямые потомки – это вершины n1 n2 n3, то C(n) – цепочка LOAD С(n3); STORE С(n1).
Если n – вершина типа б и ее прямые потомки – это вершины n1 n2 n3 ,то C(n) – цепочка С(n3); STORE $l(n); LOAD С(n1); ADD $l(n). Эта последовательность занимает временную ячейку, именем которой служит $ вместе со следующим за ним уровнем вершины n. Непосредственно видно, что, если перед этой последовательностью поставить LOAD, то значение, которое она поместит в сумматор, будет суммой значений выражением поддеревьев, над которыми доминируют вершины n1 и n3. Выбор имен временных ячеек гарантирует, что два нужных значения одновременно не появятся в одной ячейке.
Если n – вершина типа в, а все остальное как и в 4), то C(n) – цепочка С(n3); STORE $l(n); LOAD С(n1); MPY $l(n).
Применим этот алгоритм к нашему примеру (рис. 2.4).
Таким образом, в корне мы получили ассемблеровскую программу, эквивалентную фортрановской:
COST=(PRICE+TAX)*0.98.
Естественно, эта ассемблеровская программа далека от оптимальной, но это можно исправить на этапе оптимизации.
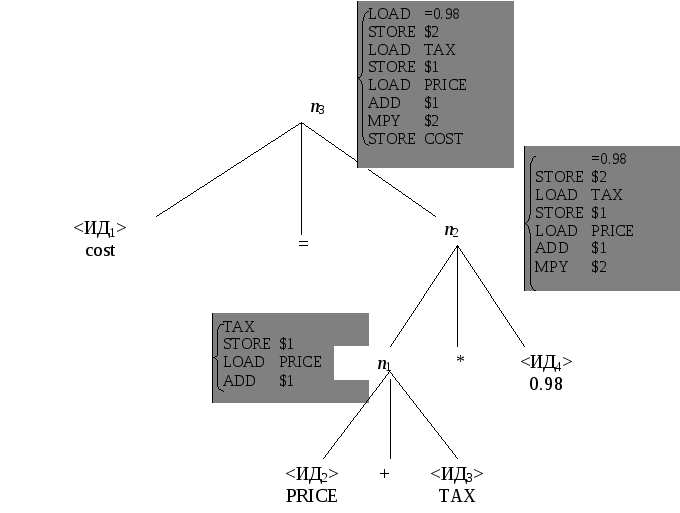
Рис. 2.4. Дерево с генерированными кодами
5. Оптимизация кода
Во многих случаях желательно иметь компилятор, который бы создавал эффективно работающие объектные программы. Термин оптимизация кода применяется к попыткам сделать объектные программы более «эффективными», т.е. быстрее работающими или более компактными.
Для оптимизации кода существует широкий спектр возможностей. На одном конце находятся истинно оптимизирующие алгоритмы. В этом случае компилятор пытается составить представление о функции, определяемой алгоритмом, программа которого записана на исходном языке. Если он «догадается», что это за функция, то может попытаться заменить прежний алгоритм новым, более эффективным алгоритмом, вычисляющий ту же функцию, и уже для этого алгоритма генерировать машинный код.
К сожалению, оптимизация этого типа чрезвычайно трудна, т.к. нет алгоритмического способа нахождения самой короткой или самой быстрой программы, эквивалентной данной.
Поэтому в общем случае термин «оптимизация» совершенно неправильный – на практике мы должны довольствоваться улучшением кода. На разных стадиях процесса компиляции применяются различные приемы улучшения кода.
В общем случае мы должны выполнить над данной программой последовательность преобразований в надежде повысить ее эффективность. Эти преобразования должны, разумеется, сохранить эффект, создаваемый во внешнем мире исходной программой.
Преобразования можно проводить в различные моменты компиляции, начиная от входной программы, заканчивая фазой генерации кода.
Более подробно оптимизацией кода мы займемся далее.
Сейчас рассмотрим лишь те приемы, которые делают код более коротким.
Если + - коммутативная операция, то можно заменить последовательность команд LOAD ; ADD ; последовательностью LOAD ; ADD . Требуется, однако, чтобы в других местах не было перехода к оператору ADD .
Подобным же образом, если * - коммутативная операция, то можно заменить LOAD ; MPY на LOAD ; MPY .
Последовательность операторов типа STORE ; LOAD можно удалить из программы при условии, что либо ячейка не будет использоваться далее, либо перед использованием ячейка будет заполнена заново.
Последовательность LOAD ; STORE ; можно удалить, если за ней следует другой оператор LOAD и нет перехода к оператору STORE , а последующие вхождения будут заменены на вплоть до того места, где появится другой оператор STORE .
Рассмотрим наш пример. Мы получили программу (табл. 2.3).
Таблица 2.3 - Оптимизация кода
|
LOAD =0.98 STORE $2 LOAD TAX STORE $1 LOAD $1 ADD PRICE MPY $2 STORE COST |
LOAD =0.98 STORE $2 LOAD TAX ADD PRICE MPY $2 STORE COST
|
LOAD TAX ADD PRICE MPY =0,98 STORE COST
|
|
Продолжение табл. 2.3. | ||
|
Применяем правило 1) к последовательности LOAD PRICE; ADD $1 Заменяем на LOAD $1 ADD PRICE |
Удаляем последовательность STORE $1; LOAD $1
|
К последовательности LOAD =0.98; STORE $2 Применяем правило 4) и удаляем их. В команде MPY $2 Заменяется $2 на MPY =0,98 |