

ГОСЫ / Parallelnye_vychislenia
.pdf1. Оценка максимально достижимого параллелизма, закон Амдаля. Понятие ускорения и эффективности параллельных алгоритмов. Анализ масштабируемости параллельных вычислений.
Абсолютно параллельных алгоритмов, за исключением тривиальных случаев, не бывает. Как правило, алгоритм параллельной программы представляет собой последовательность параллельных и последовательных участков, т.е. распределение данных (параллельная часть) и их обработку на всех или отдельных процессах (последовательно-параллельная часть). Поэтому естественно, чем меньше время выполнения последовательных участков, тем параллельный алгоритм теоретически должен бать эффективнее. Например, если алгоритм таков, что на первом и последнем этапах – работа последовательна и составляет 10%, центральная часть алгоритма параллельна и составляет 90% всей работы, то это ещё не означает, что мы получим высокую эффективность такого параллельного алгоритма.
Достижению максимального ускорения может препятствовать существование в выполняемых параллельных вычислениях последовательных расчетов, которые не могут быть распараллелены. Обосновывает этот факт закон Амдаля (Amdahl).
акон Амдала (англ. Amdahl's law, иногда также Закон Амдаля-Уэра) — иллюстрирует ограничение роста производительности вычислительной системы с увеличением количества вычислителей.
«В случае, когда задача разделяется на несколько частей, суммарное время её выполнения на параллельной системе не может быть меньше времени выполнения самого длинного фрагмента».[1] Согласно этому закону, ускорение выполнения программы за счёт распараллеливания её инструкций на множестве вычислителей ограничено временем, необходимым для выполнения её последовательных инструкций.
акон Амдаля
Пусть процессоры однородны по производительности. Т0 – время выполнения последовательной части параллельного алгоритма, например, генерирование начальных данных и обработка полученного при решении задачи результата.
Т1, Т2, ... Тp – время последовательной работы, выполняемой каждым процессором без взаимодействия между собой. Тогда время выполнения задачи на p процессорах определяется неравенством:
Tpar |
T0 |
max(Ti ) T0 |
|
|
i |
p
(Ti )
i 1 |
|
где i=1, 2, ... p. Равенство получается, когда Тi равны между собой. |
|
|
|
|
p |
|
p
Отсюда, подставляя (Ti ) = Tseq – T0, где Tseq есть время выполнения задачи на одном процессоре,
|
|
i 1 |
|
получаем: |
|
|
|
Tpar ≥ T0 + |
Tseq T0 |
|
. Делим на Tseq и, обозначая через f = T0 / Tseq - долю (fraction) последовательного |
p |
|
||
|
|
|
|
участка в общем объеме вычислений, получим:
Tpar |
f |
(1 f ) |
. (1.1) |
|
Tseq |
p |
|||
|
|
Ускорение (Speedup) – это отношение времени выполнения задачи в последовательном режиме (на 1 процессоре), ко времени выполнения задачи в параллельном режиме (на p процессорах).
STseq , используя неравенство (1.1), получим
Tpar
S |
|
1 |
|
|
p |
|
|
(1.2) |
|
|
|
|
|
|
|||
f |
(1 f ) |
|
( p 1) f |
1 |
||||
|
p |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Отсюда видно, что при f=0 и равенстве Ti получим S=p, при f >0 и p → ∞, получим S 1f . Данная функция
является монотонно-возрастающей по p и, значит, достигает максимума на бесконечности. Следовательно,
ни на каком числе процессоров ускорение счета не может превысить обратной величины доли последовательного участка.
Рассматривая закон Амдаля, мы предполагали, что доля последовательных расчетов f является постоянной величиной и не зависит от параметра n, определяющего вычислительную сложность решаемой задачи.
Однако для большого ряда задач доля f=f(n) является убывающей функцией от n, и в этом случае ускорение
1

для фиксированного числа процессоров может быть увеличено за счет уменьшения доли последовательной работы, выполняемой каждым процессором. Иначе говоря, ускорение Sp= Sp(n) является возрастающей функцией от параметра n (данное утверждение часто называют эффектом Амдаля).
Эффективность распараллеливания.
Эффективность распараллеливания – это способность алгоритма использовать все задействованные в выполнении задачи процессоры на 100%. Формула вычисления эффективности:
S
E 100% (1.2)p
Т.е. если ускорение S = p (максимально возможное на p процессорной машине), то эффективность распараллеливания задачи равна 100%. Используя закон Амдаля получаем верхнюю оценку эффективности:
|
|
|
1 |
|
|
E ≤ 100% |
|
|
|
|
(1.3) |
|
|
||||
|
|
(1 |
f ( p 1)) |
|
|
|
|
|
|
||
Например, E ≤ 52.25% |
для p=100 и f=0.01 и E ≤ 9.1% для p=1000 и f=0.01. |
||||
Вывод. При малой доли последовательной работы увеличение количества процессов приводит к ухудшению параллельной эффективности (причина – с ростом процессов растет количество обменов). Например, если f=0.01 (1%), то Е<100 и использовать для решения параллельной задачи более 100
процессоров нецелесообразно. Для повышения эффективности, как правило, не распараллеливают
управляющие части программы или небольшие участки вычислений, которые требуют интенсивной синхронизации процессов.
Для оценки ускорения рассматривают еще одну характеристику, которую называют ускорением масштабирования (scaled speedup). Данная оценка может показать, насколько эффективно могут быть организованы параллельные вычисления при увеличении сложности решаемых задач.
Масштабирование (scalable) – это способность параллельного алгоритма эффективно использовать процессоры при повышении сложности вычислений. Задача является масштабируемой, если при росте числа процессоров алгоритм обеспечивает пропорциональное увеличение ускорения при сохранении постоянного уровня эффективности использования процессоров.
Масштабируемость – это пропорциональное увеличение объема задачи с увеличением числа используемых для ее решения процессоров. Наличие масштабируемости задач является важным свойством тестовых систем оценки производительности параллельных вычислительных систем.
Плохая масштабируемость параллельного приложения на MPP-системе может быть вызвана а) ростом затрат на коммуникации при увеличении числа используемых процессоров; б) неравномерностью распределения вычислительной нагрузки между процессорами.
При увеличении количества процессоров с сохранением размерности задачи увеличивается общее количество вызовов функций MPI в программе. При этом накладные расходы на формирование и отправку сообщений растут, а объем вычислений, приходящихся на один процессор, падает, что и вызывает уменьшение эффективности параллелизации. Все большее негативное влияние в условиях возросшего количества сообщений будет оказывать латентность сети. Для кластеров, узлы которых являются симметричными мультипроцессорами, можно попытаться снизить стоимость коммуникаций, заменив внутри каждого узла многопроцессорную обработку на многопоточную.
Оценим накладные расходы (total overhead), которые имеют место при выполнении параллельного алгоритма T0 = P*Tp − T1 , где T1 - время выполнения последовательного алгоритма задачи, Tp - время выполнения алгоритма задачи на P процессорах.
Накладные расходы появляются за счет необходимости организации взаимодействия процессоров, синхронизации параллельных вычислений и т.п.
Используя введенное обозначение, можно получить новые выражения для времени параллельного решения задачи и соответствующего ускорения:
Tp = (T1 + T0)/P , Sp = T1/ Tp = (P* T1)/( T1 + T0)
Тогда эффективность использования процессоров можно выразить как
EP = Sp/P = T1/ (T1 + T0) = 1/(1+ T1/T0)
Тогда, если сложность решаемой задачи является фиксированной (T1=const), то при росте числа процессоров эффективность, как правило, будет убывать за счет роста накладных расходов T0. При фиксированном числе процессоров, эффективность можно улучшить путем повышения сложности решаемой задачи T1, поскольку предполагается, что при увеличении сложности накладные расходы T0 растут медленнее, чем объем вычислений T1.
Таким образом, при увеличении числа процессоров в большинстве случаев можно обеспечить определенный уровень эффективности при помощи соответствующего повышения сложности решаемых
2
задач. В этой связи, важной характеристикой параллельных вычислений становится соотношение необходимых темпов роста сложности расчетов и числа используемых процессоров.
Также важной характеристикой разрабатываемых алгоритмов является стоимость (cost) вычислений, определяемая как произведение времени параллельного решения задачи и числа используемых процессоров.
3

2. Топология сети передачи данных. Примеры элементарных топологий, основные характеристики. Алгоритмы маршрутизации и методы передачи данных.
При организации параллельных вычислений в мультикомпьютерах для организации взаимодействия, синхронизации и взаимоисключения параллельно выполняемых процессов используется передача данных между процессорами вычислительной среды. Временные задержки при передаче данных по линиям связи могут оказаться существенными (по сравнению с быстродействием процессоров) и, как результат, коммуникационная трудоемкость алгоритма оказывает существенное влияние на выбор параллельных способов решения задач.
Примеры топологий сети передачи данных
Структура линий коммутации между процессорами вычислительной системы (топология сети передачи данных) определяется, как правило, с учетом возможностей эффективной технической реализации. Немаловажную роль при выборе структуры сети играет и анализ интенсивности информационных потоков при параллельном решении наиболее распространенных вычислительных задач.
Топология сети передачи данных – это структура линий коммутации между процессорами вычислительной системы. Топология представляет собой полный граф, в котором передача данных может быть организована между любыми двумя вершинами (процессорами сети). Топология определяется с учетом возможностей эффективной технической реализации на основе анализа интенсивности передачи информационных потоков. К числу типовых топологий обычно относят следующие схемы коммуникации процессоров (см. рисунок).
Полный граф (completely-connected graph or clique) – система, в которой между любой парой процессоров существует прямая линия связи, поэтому данная топология обеспечивает минимальные затраты при передаче данных, однако является сложно реализуемой при большом количестве процессоров.
Линейка (linear array or farm) – система, в которой все процессоры перенумерованы по порядку и каждый процессор, кроме первого и последнего, имеет линии связи только с двумя соседними (с предыдущим и последующим) процессорами; такая схема является, с одной стороны, просто реализуемой, а с другой стороны, соответствует структуре передачи данных при решении многих вычислительных задач (например, при организации конвейерных вычислений).
Кольцо (ring) – данная топология получается из линейки процессоров соединением первого и последнего процессоров линейки.
везда (star) – система, в которой все процессоры имеют линии связи с некоторым управляющим процессором; данная топология является эффективной, например, при организации централизованных схем параллельных вычислений.
Решетка (mesh) – система, в которой граф линий связи образует прямоугольную сетку (обычно двух - или трехмерную); подобная топология может быть достаточно просто реализована и, кроме того, может быть эффективно использована при параллельном выполнении многих численных алгоритмов (например, при реализации методов анализа математических моделей, описываемых дифференциальными уравнениями в частных производных).
Гиперкуб (hypercube) – данная топология представляет частный случай структуры решетки, когда по каждой размерности сетки имеется только два процессора; данный вариант организации сети передачи данных
достаточно широко распространен в практике и характеризуется следующим рядом отличительных признаков: а) два процессора имеют соединение, если двоичные представления их номеров имеют
только одну различающуюся позицию;
б) N-мерный гиперкуб может быть разделен на два (N-1)-мерных гиперкуба (всего возможно N различных разбиений); в) кратчайший путь между любыми двумя процессорами имеет длину, совпадающую с количеством различающихся
битовых значений в номерах процессоров (данная величина известна как расстояние Хэмминга).
Т.к. каждый процессор может принимать участие только в одной операции приема-передачи данных, то параллельно могут выполняться только те коммуникационные операции, в которых взаимодействующие пары процессоров не пересекаются между собой.
Характеристики топологии сети
В качестве основных характеристик топологии сети передачи данных наиболее широко используется следующий ряд показателей:
•Диаметр – показатель, определяемый как максимальное расстояние между двумя процессорами (под расстоянием обычно понимается величина кратчайшего пути между процессорами); данная величина может характеризовать максимально-необходимое время для передачи данных между процессорами, поскольку время передачи обычно прямо пропорционально длине пути;
•Связность (connectivity) – показатель, характеризующий наличие разных маршрутов передачи данных между процессорами сети; конкретный вид данного показателя может быть определен, например, как минимальное количество дуг, которое надо удалить для разделения сети передачи данных на две несвязные области;
•Ширина бинарного деления (bisection width) – показатель, определяемый как минимальное количество дуг, которое надо удалить для разделения сети передачи данных на две несвязные области одинакового размера;
4
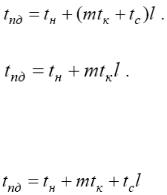
• Стоимость – показатель, который может быть определен, например, как общее количество линий передачи данных
вмногопроцессорной вычислительной системе.
Алгоритмы маршрутизации
Очевидно, что временные задержки при передаче данных по каналам связи при взаимодействии процессов влияют на эффективность параллельных вычислений. Алгоритмы маршрутизации определяют путь передачи данных от процессора-источника до процессора получателя сообщения. Алгоритмы маршрутизации должны определять оптимальный, т.е. кратчайший путь передачи данных с использованием детерминированных и адаптивных методов выбора маршрутов (адаптивные алгоритмы определяют пути передачи данных в зависимости от существующей загрузки коммуникационных каналов).
К числу наиболее распространенных оптимальных алгоритмов относится класс методов покоординатной маршрутизации (dimension-ordered routing), в которых поиск путей передачи данных осуществляется поочередно для каждой размерности топологии сети коммуникации. Например, для двумерной решетки такой подход приводит к маршрутизации, при которой передача данных сначала выполняется по одному направлению (например, по горизонтали до достижения вертикали процессоров, в которой располагается процессор назначения), а затем данные передаются вдоль другого направления (данная схема известна под названием алгоритма XY-маршрутизации).
Для гиперкуба покоординатная схема маршрутизации может состоять, например, в циклической передаче данных процессору, определяемому первой различающейся битовой позицией в номерах процессоров, на котором сообщение располагается в данный момент времени, и на который сообщение должно быть передано.
Время передачи данных между процессорами определяет длительность выполнения параллельного алгоритма в многопроцессорной вычислительной системе. Время передачи данных включает:
− время начальной подготовки (t ) характеризует длительность подготовки сообщения для передачи, поиска
н
маршрута в сети и т.п.;
− время передачи служебных данных (t ) между двумя соседними процессорами (между которыми имеется
с
физический канал передачи данных); к служебным данным может относиться заголовок сообщения, блок данных для обнаружения ошибок передачи и т.п.;
− время передачи одного слова данных по одному каналу передачи данных (t ); длительность подобной передачи
к
определяется пропускной способностью сети.
Рассмотрим два наиболее распространенных метода передачи данных.
Первый – выполняет передачу сообщений как неделимых (атомарных) блоков информации (store-and-forward routing or SFR). В этом случае процессор-отправитель готовит весь объем данных для передачи, определяет процессор, которому следует направить данные, и запускает операцию передачи данных. Процессор-получатель сообщения, осуществляет прием данных, затем, при необходимости приступает к передаче принятого сообщения далее по
маршруту. Время передачи данных t для сообщения размером m байт по маршруту длиной l определяется выражением
пд
При достаточно длинных сообщениях временем передачи служебных данных можно пренебречь и выражение может быть записано в более простом виде
Второй способ - выполняет передачу сообщений в виде блоков информации, в результате чего передача данных может быть сведена к передаче пакетов. В этом случае принимающий процессор может осуществлять пересылку данных по дальнейшему маршруту непосредственно сразу после приема очередного пакета, не дожидаясь завершения приема данных всего сообщения. Время пересылки данных при использовании метода передачи пакетов будет определяться выражением
В большинстве случаев метод передачи пакетов приводит к более быстрой пересылке данных; кроме того, данный подход снижает потребность в памяти для хранения пересылаемых данных для организации приема-передачи сообщений, а для передачи пакетов могут использоваться одновременно разные коммуникационные каналы. С другой стороны, реализация пакетного метода требует разработки более сложного аппаратного и программного обеспечения сети, может увечить накладные расходы (время подготовки и время передачи служебных данных).
5
3. Классификация многопроцессорных вычислительных систем. Понятие пропускной способности и латентности, методы их измерения.
Одним из наиболее распространенных классификаторов многопроцессорных ВС является система Флинна (Flynn), в основу которой положен способ взаимодействия последовательностей (потоков) выполняемых команд и обрабатываемых данных. В результате такого подхода различают следующие основные типы систем:
1.SISD (Single Instruction, Single Data) – системы с одиночным потоком команд и одиночным потоком данных; к данному типу систем можно отнести обычные последовательные ЭВМ;
2.SIMD (Single Instruction, Multiple Data) – системы с одиночным потоком команд и множественным потоком данных; это многопроцессорные вычислительные системы, в которых в каждый момент времени может выполняться одна и та же команда для обработки нескольких информационных элементов; подобной архитектурой обладают, например, многопроцессорные системы с единым устройством управления;
3.MISD (Multiple Instruction, Single Data) – системы с множественным потоком команд и одиночным потоком данных. Относительно данного типа систем нет единого мнения – ряд специалистов говорят, что примеров конкретных ЭВМ, соответствующих данному типу вычислительных систем, не существует, и введение подобного класса предпринимается для полноты системы классификации; другие же относят к данному типу, например, системы с конвейерной обработкой данных;
4.MIMD (Multiple Instruction, Multiple Data) – системы с множественным потоком команд и множественным потоком данных; к подобному классу систем относится большинство параллельных многопроцессорных вычислительных систем.
Хотя система Флинна широко используется при конкретизации типов компьютерных систем, такая классификация приводит к тому, что практически все виды параллельных систем (несмотря на их существенную разнородность) относятся к одной группе MIMD. Неоднократные предпринимались попытки детализации системы Флинна. Так, например, для класса MIMD была предложена структурная схема, в которой дальнейшее разделение типов многопроцессорных систем основывается на способах организации памяти: системы на общей и распределенной памяти.
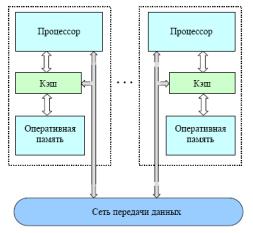
Существующие параллельные ВС класса MIMD образуют два технических подкласса: симметричные мультипроцессоры (SMP) и системы с массовым параллелизмом (МРР).
1.Симметричные мультипроцессоры используют принцип разделяемой(общей) памяти. В этом случае система состоит из нескольких однородных процессоров и массива общей памяти. Все процессоры имеют доступ к любой ячейке памяти с одинаковой скоростью. Аппаратно поддерживается когерентность (согласованность) кэш памяти.
Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число. Вся система работает под управлением единой ОС.
2.Системы с массовым параллелизмом (массивно-параллельные системы massively parallel processor или MPP), примером которых являются кластерные вычислительные системы − это совокупность вычислительных узлов, объединенных в рамках некоторой сети для решения одной задачи. В настоящее время, в качестве вычислительных узлов используются многоядерные процессорные элементы (SMP узлы). Каждый узел работает под управлением своей копии операционной системы, в качестве которой чаще всего используются юниксоподобные ОС (Linux, AIX и т.п) или OC WINDOWS. Состав и мощность узлов может меняться даже в рамках одного кластера, давая возможность создавать неоднородные (гетерогенные) вычислительные системы.
Для кластерных систем принципиальное значение имеют топология и архитектура коммуникационных сетей и соответствующие характеристики - латентность и пропускная
способность.
Понятие пропускной способности и латентности
Основными характеристиками быстродействия сети являются латентность и пропускная способность. Предположим, что на двух процессорах вычислительной системы работают два процесса, между которыми с помощью сети пересылаются сообщения. В передаче информации, кроме аппаратных устройств, участвует и ПО, например реализация интерфейса передачи сообщений MPI.
6
Пропускная способность сети определяется количеством информации, передаваемой между узлами сети в единицу времени (N байт в секунду). Реальная пропускная способность снижается программным обеспечением за счет передачи служебной информации.
Латентностью (задержкой) называется время, затрачиваемое программным обеспечением и устройствами сети на подготовку к передаче информации по данному каналу. Полная латентность складывается из программной и аппаратной составляющих.
Различают следующие виды пропускной способности сети:
1.пропускная способность однонаправленных пересылок ("точка-точка", uni-directional bandwidth), равная максимальной скорости, с которой процесс на одном узле может передавать данные другому процессу на другом узле.
2.пропускная способность двунаправленных пересылок (bidirectional bandwidth), равная максимальной скорости, с которой два процесса могут одновременно обмениваться данными по сети.
Методы измерения пропускной способности и латентности
Для измерения пропускной способности однонаправленных пересылок ("точка-точка") процесс с номером 0 посылает процессу с номером 1 сообщение длины L байт. Процесс 1, приняв сообщение от процесса 0, посылает ему ответное сообщение той же длины. Используются блокирующие вызовы MPI. Эти действия повторяются N раз с целью минимизировать погрешность за счет усреднения. Процесс 0 измеряет время T, затраченное на все эти обмены. Пропускная способность R определяется по формуле R=2NL/T.
Для измерения пропускной способности двунаправленных обменов используются неблокирующие вызовы MPI. При этом производится измерение времени, затраченного процессом 0 на передачу сообщения процессу 1 и прием ответа от него, при условии, что процессы начинают передачу информации одновременно после точки синхронизации.
Латентность измеряется как время, необходимое на передачу сигнала или сообщения нулевой длины. Для снижения влияния погрешности и низкого разрешения системного таймера (очень малые времена округляются до 0) важно повторить операцию посылки сигнала и получения ответа большое число раз. Таким образом, если время на N итераций пересылки сообщений нулевой длины туда и обратно составило T сек., то латентность измеряется как s=T/(2N).
7
4. Цели и задачи параллельной обработки данных. Основные принципы выполнения параллельных вычислений на общей и распределенной памяти. SMP-системы, их преимущества и недостатки. Параллельные вычисления с передачей сообщений.
Цель параллельных вычислений - ускорить выполнение алгоритма за счет совмещения выполнения множества вычислительных операций над данными. Параллельный алгоритм должен:
1.при использовании интерфейса передачи данных выполнять: а) оптимальное распределение данных по процессам, б) эффективный обмен данными,
в) по возможности обеспечить равномерную вычислительную нагрузку процессоров.
2.при использовании без обменных средств распараллеливания выделить блоки алгоритма, в которых возможно выполнить параллельные вычисления, обращаясь к разным областям общей памяти.
Создавать параллельные программы стало возможно с появлением в операционных системах механизма порождения потоков или нитей (threads), называемых еще легковесными процессами (light-weight process). Нить - это независимый поток управления, выполняемый в контексте некоторого процесса совместно с другими нитями или процессами. Нити имеют общее адресное пространство, но разные потоки команд. В простейшем случае, процесс состоит из одной нити. Однако, если эти потоки (процессы) совместно используют некоторые ресурсы, например область памяти, то при обращении к этим ресурсам они должны синхронизовать свои действия. Многолетний опыт программирования с использованием явных операций синхронизации показал, что такой стиль "параллельного" программирования порождает серьезные проблемы при написании, отладке и сопровождении параллельных программ.
Споявлением симметричных мультипроцессорных систем (SMP), отношение к разработке параллельных программ претерпело существенные изменения. В SMP системах физически присутствуют несколько процессоров, которые имеют равные права и скорость обращения к совместно используемой памяти. Наиболее распространенным интерфейсом для создания параллельных приложений на общей памяти является OpenMP. Интерфейс OpenMP является стандартом для программирования на SMP-системах, в него входит описание набора директив компилятора, переменных среды выполнения программ и ряд процедур. OpenMP является без обменным средством распараллеливания и идеально подходит для программ, где выполняемые вычисления обращаются к разным (не пересекающимся) областям общей памяти, например, программ с “большими” по числу итераций циклами.
Достоинством организации параллельных вычислений на ВС с общей памятью, является использование без обменных средств распараллеливания, что значительно увеличивает производительность параллельного приложения при правильном обращении к общей памяти.
Недостатком организации параллельных вычислений на ВС с общей памятью, является доступ разных процессоров к общим данным и обеспечение, в этой связи, однозначности значений данных (cache coherence problem), т.е. необходимость выполнения явной синхронизации для обеспечения безопасного доступа к данным.
Передача сообщений является универсальным механизмом при выполнении параллельных вычислений и может выполняться как на SMP, так и на массивно-
параллельных системах (massively parallel processor or MPP),
примером которых являются кластерные вычислительные системы.
Кластерные системы − это более распространенный вариант MPP–систем, где также используется принцип передачи сообщений. В настоящее время в качестве вычислительных узлов используются двух или четырехпроцессорные SMP-серверы. Каждый узел работает
под управлением своей копии операционной системы, в качестве которой чаще всего используются
8

стандартные операционные системы: Linux, NT, Solaris и т.п. Состав и мощность узлов может меняться в рамках одного кластера, давая возможность создавать неоднородные системы.
Для кластерных систем в соответствии с сетевым законом Амдаля характеристики коммуникационных сетей имеют принципиальное значение. Коммуникационные сети имеют две основные характеристики: латентность − время начальной задержки при посылке сообщений и пропускную способность сети, определяющую скорость передачи информации по каналам связи. При выполнении функции передачи данных, прежде чем покинуть процессор, последовательно выполняется набор операций, определяемый особенностями программного обеспечения и аппаратуры. Наличие латентности определяет и тот факт, что максимальная скорость передачи по сети не может быть достигнута на сообщениях с небольшой длиной.
Достоинства организации параллельных вычислений на распределенной памяти:
1.Использование распределенной памяти упрощает задачу создания мультипроцессорных вычислительных систем.
2.Каждый процесс обладает собственными ресурсами и выполняется в собственном адресном пространстве, таким образом, данные, находящиеся на каждом процессе защищены от неконтролируемого доступа.
3.Универсальность, т.к. алгоритмы с передачей сообщений могут выполняться на большинстве сегодняшних суперкомпьютеров.
4.Легкость отладки. Отладка параллельных программ все еще остается сложной задачей. Однако процесс отладки происходит легче в программах с передачей сообщений. Это связано с тем, что самая распространенная причина ошибок заключается в неконтролируемой перезаписи данных в памяти. Модель с передачей сообщений, явно управляет обращением к памяти, и, тем самым, облегчает локализацию ошибочного чтения или записи в память.
Недостатки организации параллельных вычислений на распределенной памяти:
1.Каждый процессор вычислительной системы может использовать только свою локальную память, поэтому для доступа к данным, располагаемым на других процессорах, необходимо явно выполнять операции передачи сообщений (message passing operations).
2.Проблема эффективного использования распределенной памяти приводят к существенному повышению сложности параллельных вычислений.
Современные вычислительные системы представляют собой распределенные SMP узлы. При такой архитектуре можно использовать два варианта выполнения параллельных программ. Процесс – это программная единица, у которой имеется собственное адресное пространство и одна или несколько нитей. Процессор − фрагмент аппаратных средств, способный к выполнению программы. Если в кластере используются SMP–узлы, то для организации вычислений возможны два варианта:
1.на каждом вычислительном SMP узле порождается отдельный процесс. Процессы внутри узла обмениваются сообщениями через разделяемую память.
2. каждый вычислительный SMP узел захватывается монопольно одним процессом, внутри которого выполняется распараллеливание в модели "общей памяти", например с помощью директив
OpenMP.
Оптимальным для параллельного выполнения программ в алгоритмах задач достаточно выделять только крупные независимые части расчетов, что, упрощает построение параллельных методов вычислений и уменьшает потоки передаваемых данных между процессорами кластера.
Однако, организация взаимодействия вычислительных узлов при помощи передачи сообщений обычно приводит к значительным временным задержкам, что накладывает дополнительные ограничения на тип разрабатываемых параллельных алгоритмов и программ.
Поэтому использование смешанного механизма распараллеливания на общей и распределенной памяти является наиболее эффективным при выполнении параллельных вычислений на современных высокопроизводительных вычислительных системах.
9
5. Общие свойства параллельных алгоритмов. Полная и неполная параллельность. Особенности выбора способов распараллеливания.
Мощные компьютеры стимулировали быстрый рост нового вида научной деятельности. К двум обширным классическим ветвям науки - теоретической и экспериментальной - добавилась вычислительная наука. На суперкомпьютерах выполняется моделирование физических процессов, слишком сложных, чтобы быть достоверно предсказуемыми теоретически, и слишком опасных или дорогостоящих при их воспроизведении в лаборатории. Успехи вычислительной науки резко повысили требования к вычислительным ресурсам и стимулировали быстрое развитие параллельных архитектур.
Дело в том, что стоимость однопроцессорных компьютеров растет быстрее, чем их производительность. На начальных этапах в качестве параллельного компьютера могли использоваться относительно небольшие сети рабочих станций, первоначально используемые для выполнения более простых вычислительных работ. Благодаря относительно низкой себестоимости и приемлемой эффективности выполнения параллельных программ эта схема оказалась столь успешной, что сети рабочих станций стали закупаться с целью выполнения на них более сложных параллельных работ, обычно исполняемых на более дорогих суперкомпьютерах.
Однако, постоянное требование к росту производительности параллельных вычислительных систем и необходимость выполнения крупномасштабных вычислений привело вычислительную науку в область создания параллельных ВС смешанной архитектуры - распределенные мультиядерные вычислительные узлы с высокопроизводительной коммуникационной архитектурой и топологий сети. На сегодняшний день производительность самого мощного суперкомпьютера мира — IBM Roadrunner достигает 1,105 PFLOP.
Однако, различные формы параллелизма должны быть выражены в реальной программе, поэтому проблема эффективного распараллеливания переходит в плоскость программного обеспечения. Компиляторы, автоматически распараллеливающие последовательные алгоритмы, остаются ограниченными по применимости. Несмотря на то, что современные компиляторы при наличии технической возможности (напр. многоядерность) способны строить параллельный код на некоторых программах, наилучшая производительность достигается тогда, когда сам программист распараллеливает алгоритм.
Параллельный алгоритм должен быть эффективным и мобильным.
Цель распараллеливания: - ускорить выполнение алгоритма за счет совмещения выполнения множества операций над данными. Алгоритмы, которые разрабатываются для использования в параллельных программах, обладают рядом общих свойств.
Свойство 1 - использование в алгоритме параллельной программы множественного выполнения (N раз) одного и того же элементарного алгоритма:
Этим свойством обладают алгоритмы задач, в которых надо найти состояния S1, S2, … Sn физической системы в разные последовательные моменты времени: T1, T2, …, Tn и дано состояние физической системы S0 в момент времени T0.
Состояние физической системы в момент времени i+1 можно описать как Si+1=Э(Si). Т.е. алгоритм представляет собой последовательное выполнение элементарного алгоритма Э с входными данными Si и выходными Si+1, где Э – не зависит от i. (от i зависят входные данные и результат). Нельзя вычислить состояние Si, не вычислив предыдущее состояние Si-1
Свойство 2 - пространственная область разбивается на подобласти, каждая из которых обрабатывается отдельным процессом, таким образом, решение задачи может быть выполнено параллельно, с учетом зависимостей соседних подобластей по данным.
Пример. В задачах математического моделирования в области пространства строится сетка соответствующей размерности. Ячейки сетки содержат части вещества, каждое со своим состоянием, и могут быть достаточно разными по своим размерам.
Свойство 3 – параллельные алгоритмы допускают совмещение множества операций.
Это значит, что алгоритм содержит возможность выполнять одновременно несколько одинаковых или различных операций, если вычислительная система состоит из множества процессоров, которые одновременно могут выполнять хотя бы одну операцию. Процессоры могут взаимодействовать между собой, вычислительные операции внутри каждого процесса выполняется последовательно.
В качестве примеров рассмотрим распараллеливание простых алгоритмов.
Пример 1. Поэлементное сложение векторов - функция axpy(Z, a, X, Y) выполняет следующее действие: Z = a*X+Y, где a – скаляр с плавающей точкой, X, Y и Z – векторы размера n. Для
10