

3 Імпорт даних, оцінка якості, відновлення, корекція і очистка даних
Для імпортування даних у систему ми використовуємо Майстер імпорту. Особливістю Deductor Academic є те, що дані можливо завантажити лише з текстового фалу.
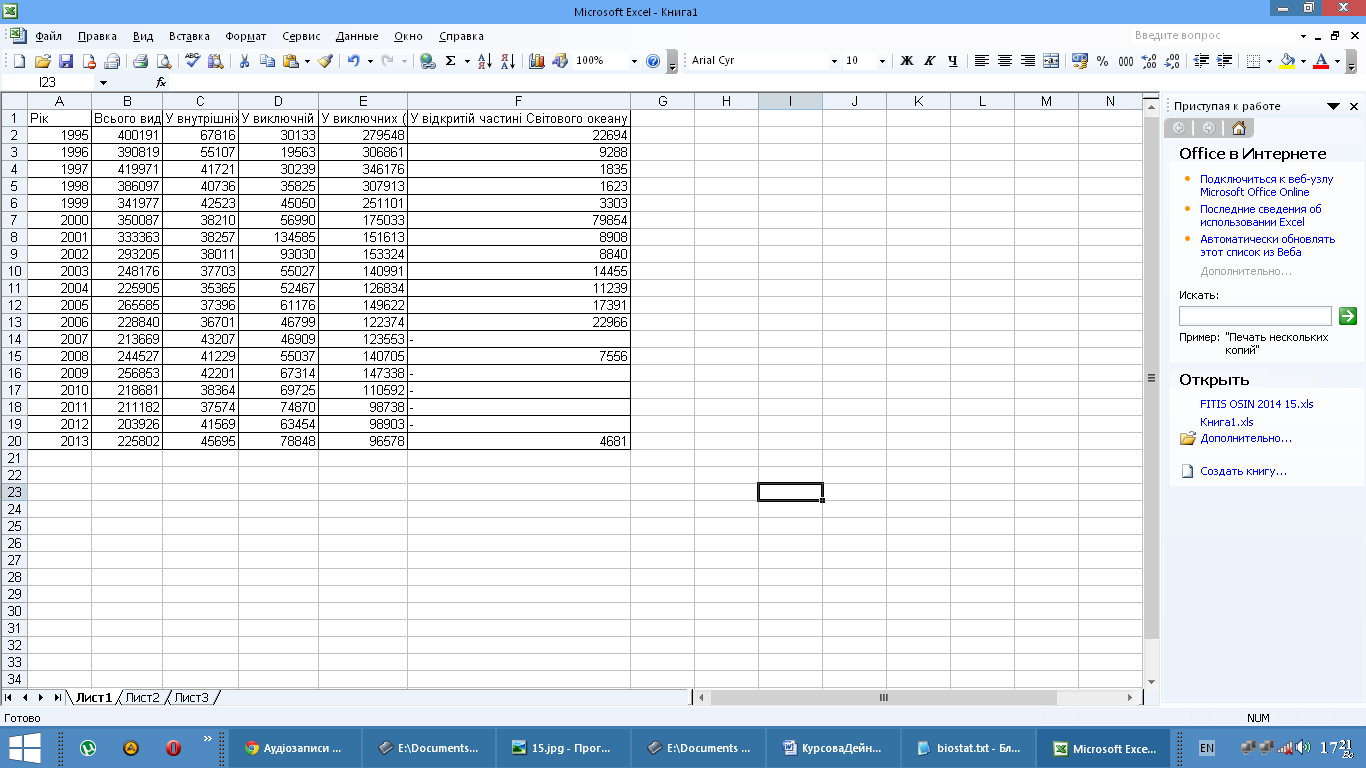
Рис.1 Вхідні дані у форматі Microsoft Exel
Тому для подальшої роботи з вибіркою створюємо текстовий файл за допомогою Блокнот.
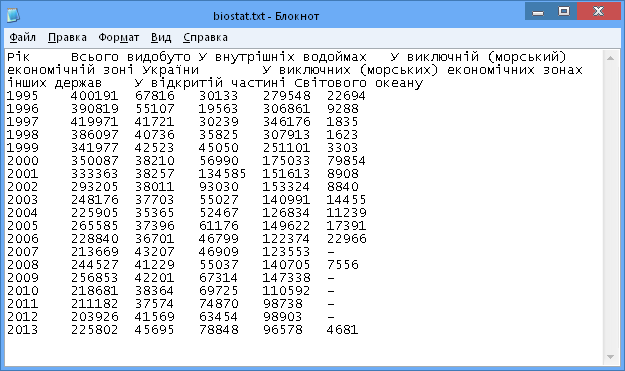
Рис.2 Вхідні дані у форматі .txt
Далі запускаємо Майстер імпорту і вказуємо подальші параметри імпортування, а саме:
Формат вихідних даних;
Парамаетри імпорту файла з розмежуваннями;
Визначення призначення величин, тип даних, їх форма;
Рис.3 Майстер імпорту

Рис.4 Зображення даних

Рис.5 Параметри імпорту
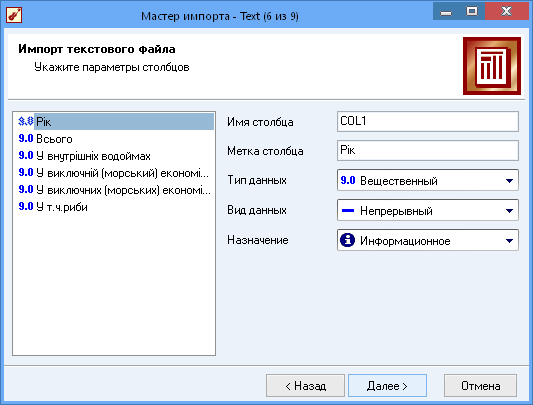
Рис.6 Визначення призначення величин (вхідні\ вихідні\ інформаційні), тип даних (дата, ціле число, строка, тощо), їх форма (дискретна, неперервна)
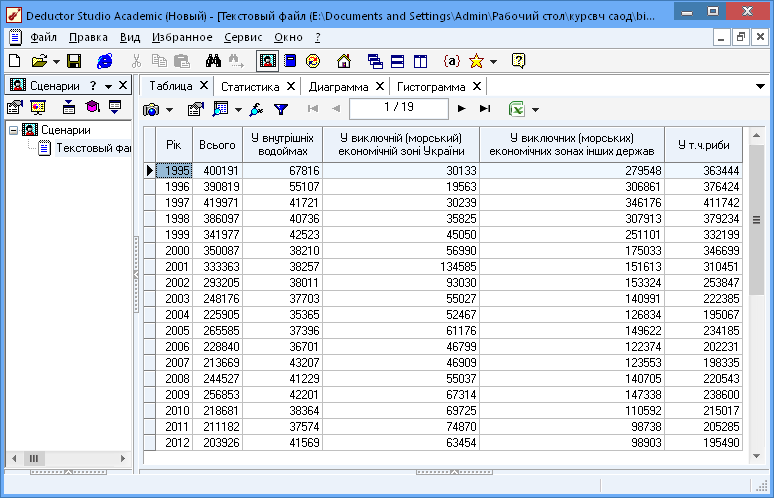
Рис.7 Фрагмент зображення даних
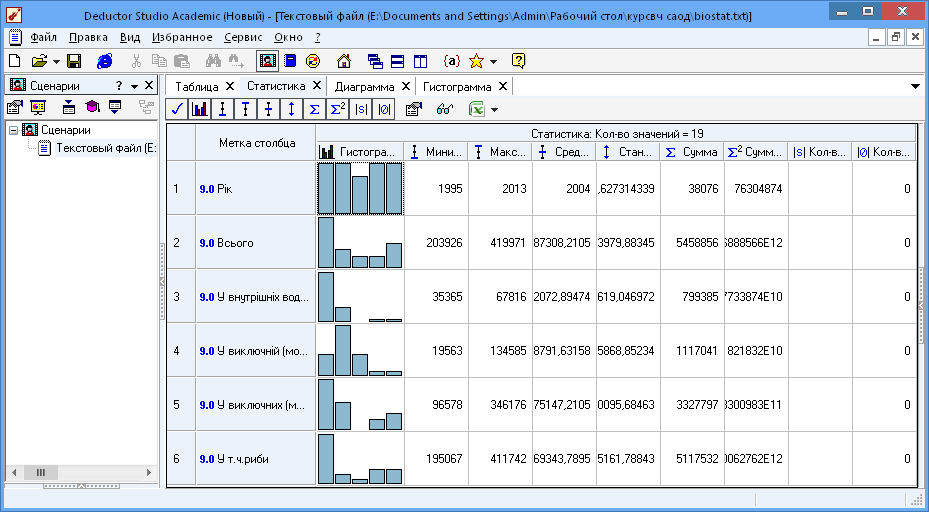
Рис.8 Статистика
Для цього набору даних також було використано візуалізацію як одну із задач аналізу даних. На наступному рисунку було показано параметри відображення для нашої вибірки:
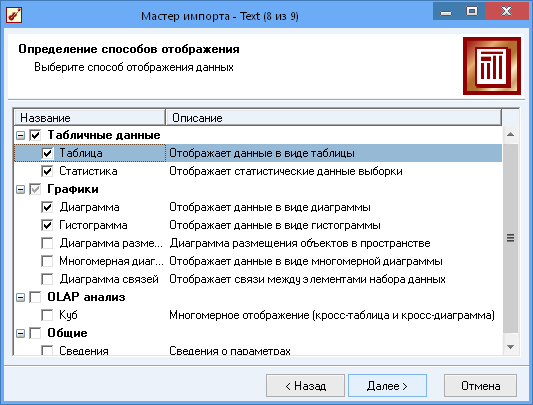
Рис.9 Параметри візуалізації
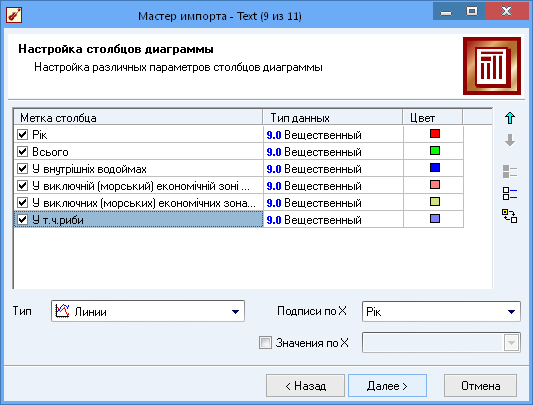
Рис.10 Показники, які відображаються на діаграмі
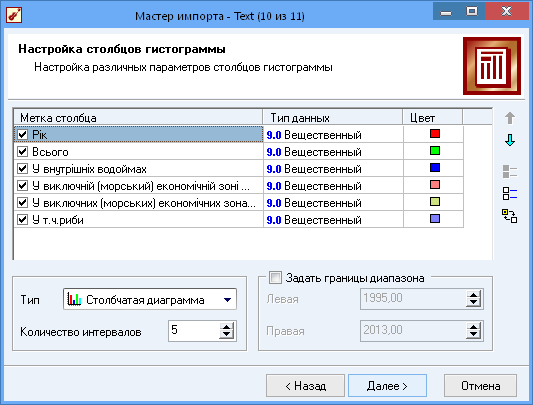
Рис.11 Показники, які відображаються на графіку
На рис.12 показано отриманий графік обсягів видобування біоресурсів для різних видів видобутку, взалежності від року видобування. Цей графік демонстує обсяг видубутку біоресурсів (відносний спад):

Рис.12 Діаграма показників продукції
4 Дослідження видобутку біоресурсів Україною із застосуванням методів аналітичної обробки даних
4.1 Кореляційний аналіз
Кореляційний аналіз застосовується для оцінки залежності вихідних полів даних від вхідних факторів і усунення незначущих факторів. Принцип кореляційного аналізу полягає у пошуку таких значень, які в найменшій мірі корельовані (взаємопов'язані) з вихідним результатом. Такі чинники можуть бути виключені з результуючого набору даних практично без втрати корисної інформації. критерієм прийняття рішення про виключення є поріг значимості. Якщо модуль кореляції (ступінь взаємозалежності) між вхідним і вихідним факторами менше порога значимості, то відповідний фактор відкидається як незначущий.
За допомогою кореляційного аналізу дізнаймося від чого найбільше залежить загальна кількість видобутих біоресурсів:
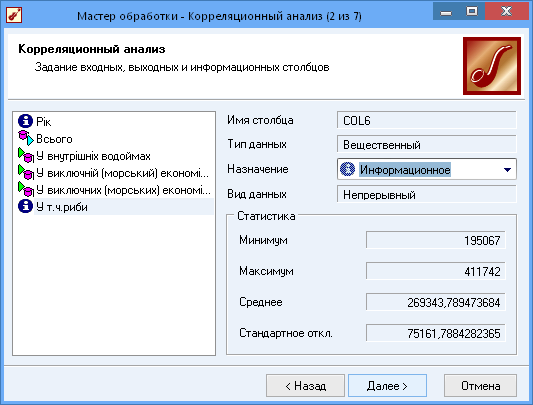
Рис.13 Вибір даних для кореляційного аналізу
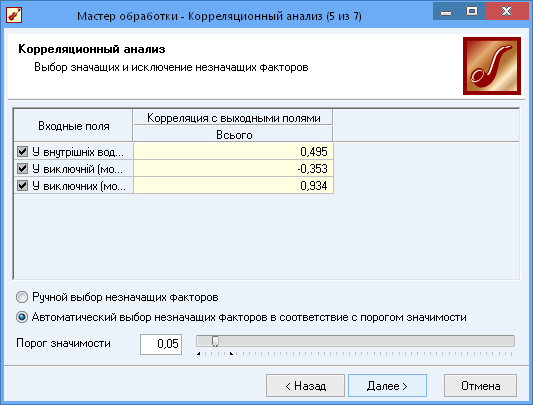
Рис.14 Вибір значущих факторів
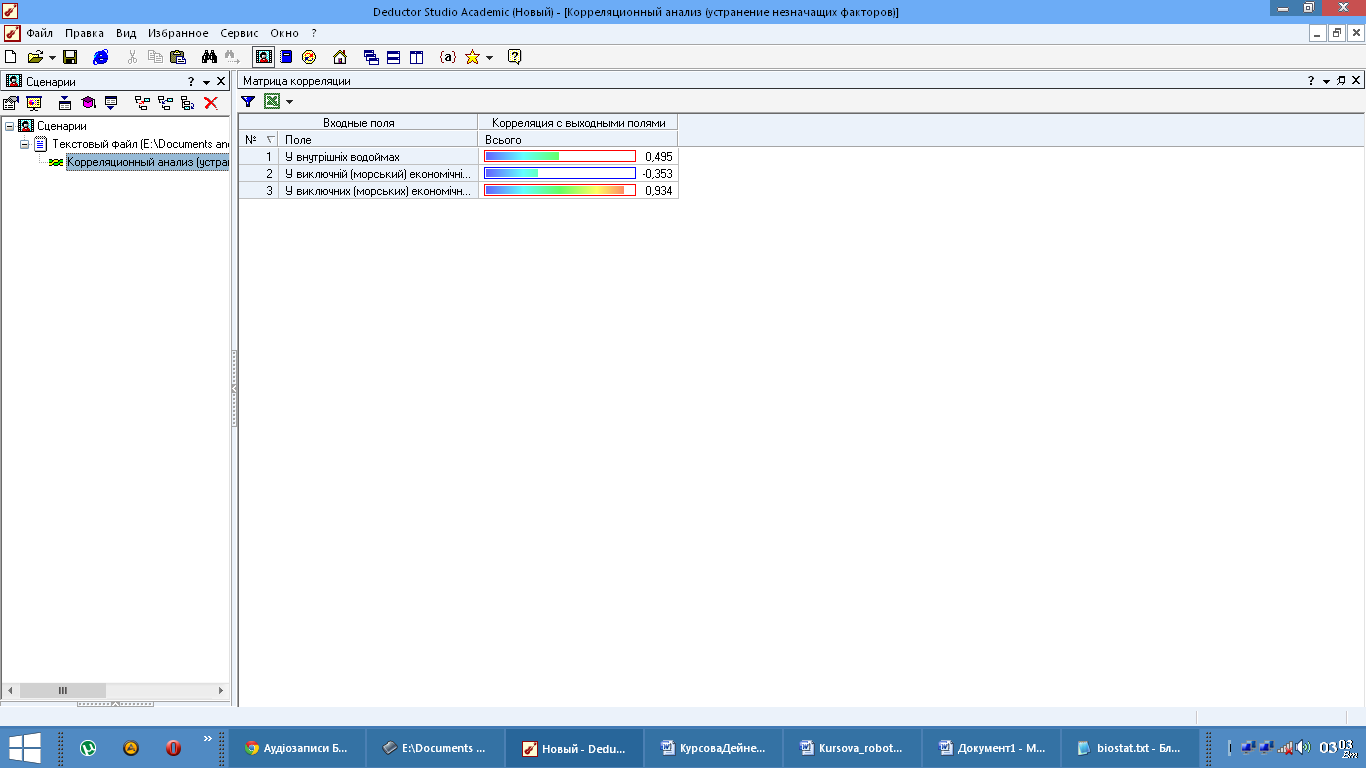
Рис.15 Кореляційна залежність
Як ми можемо побачити значним впливом на загальну кількість біоресурсів являє собою видобуток у виключних (морських) економічних зонах інших держав. Також можна зазначити, що найменший вплив має видобуток біоресурсів у виключній морській зоні України.
Для отримання додаткової інформації також побудуємо лінійну регресію:

Рис. 16. Вибір вхідних та вихідних даних для лінійної регресії
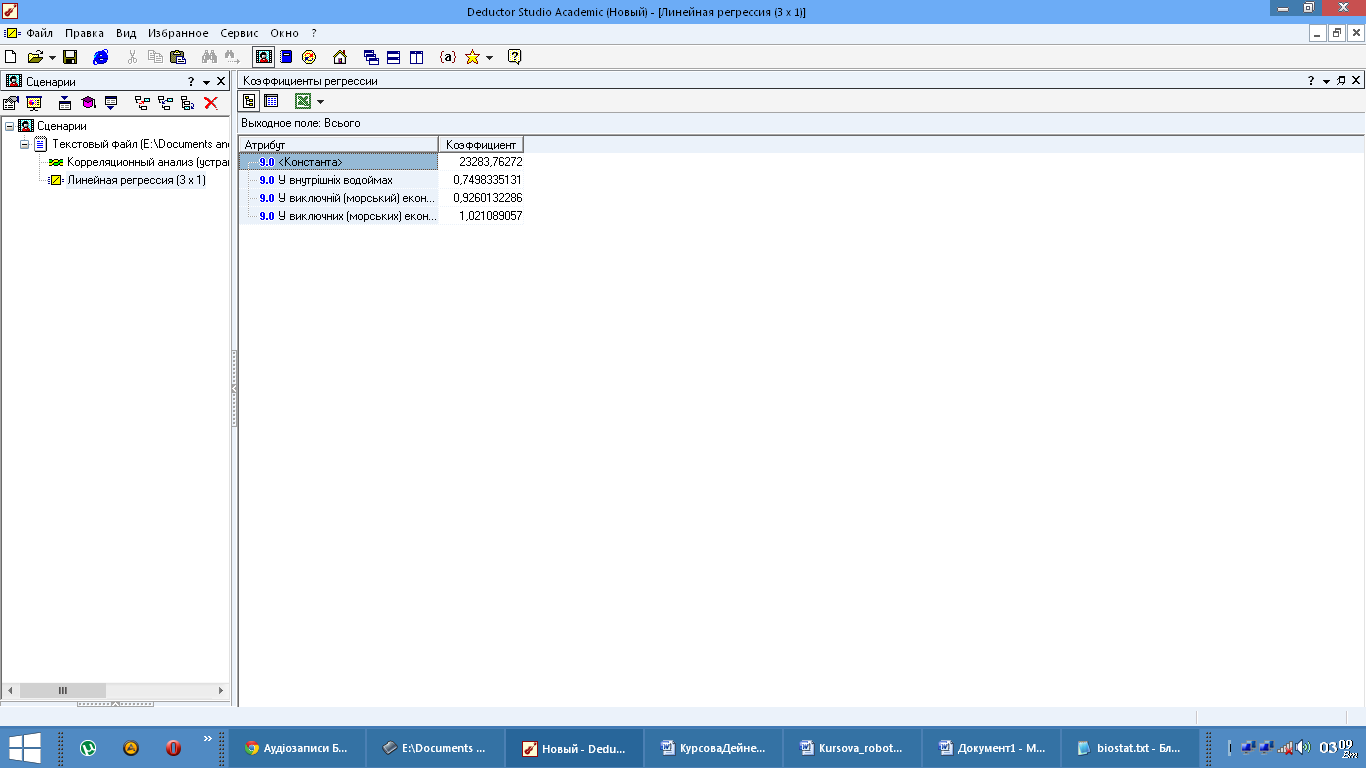
Рис. 17. Результат лінійної регресії
4.2 Групування
Аналітику для прийняття рішення часто необхідна зведена інформація, тобто згруповані дані. Сукупні дані набагато більш інформативні, особливо якщо їх можна отримати в різних розрізах. В Deductor передбачений інструмент, який реалізує збір зведеної інформації - «Групировка». Групування дозволяє об'єднувати записи по полях-вимірів, агрегуючи дані в полях-фактах для подальшого аналізу
Рис. 18. Налаштування даних для групування

Рис. 19. Результати групування
На Рис. 19. Можна побачити результати групування, так я в нас вимір це роки, немає сенсу їх використовувати так як в нас нічого б не змінилось, адже дані в нас по одному на рік.
4.3 Кластеризація
Кластеризація - це угрупування об'єктів (спостережень, подій) на основі даних (властивостей), що описують сутність об'єктів. Об'єкти усередині кластера повинні бути «Схожими» один на одного і відрізнятися від об'єктів, що ввійшли в інші кластери. чим більше схожі об'єкти всередині кластера і чим більше відмінностей між кластерами, тим точніше кластеризація.
Рис.20 Задання назначення вихідних стовпців даних
Рис.21 Вибір типу кластеризації
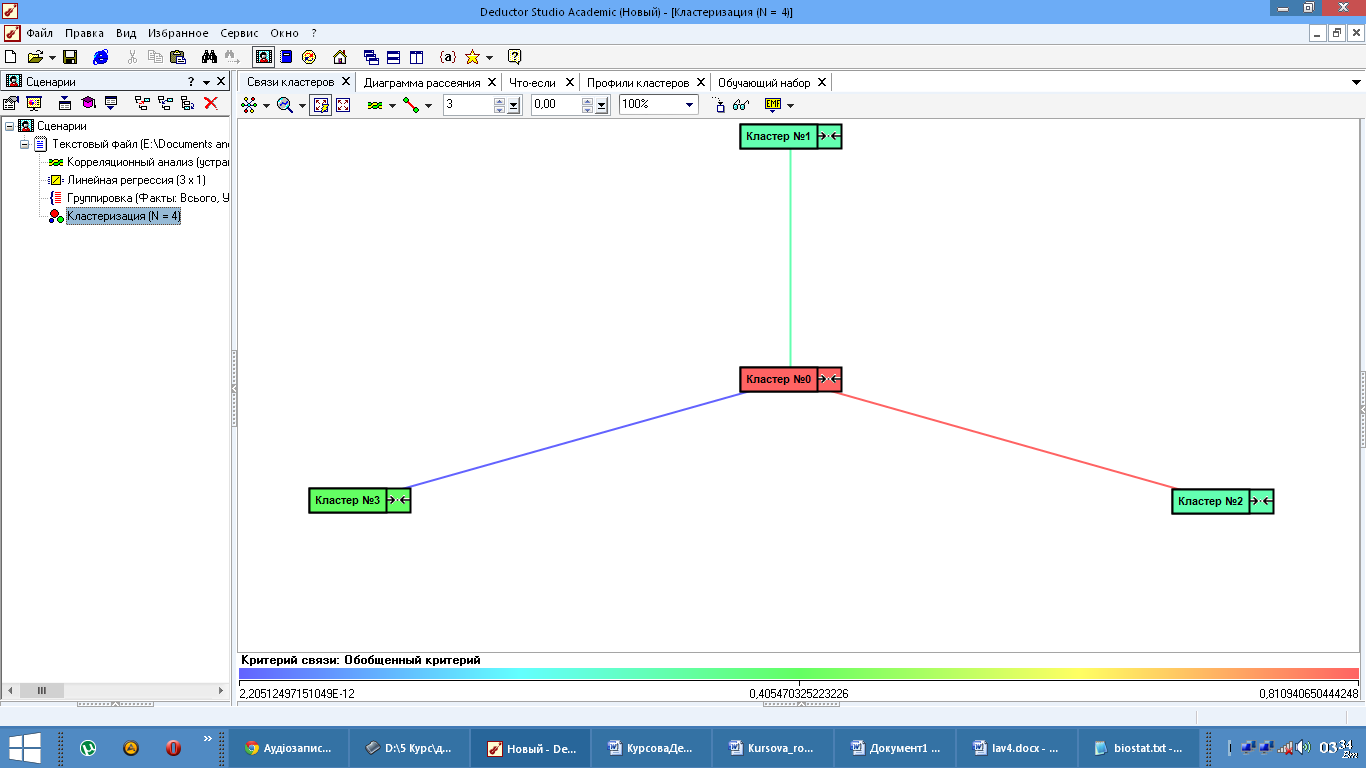
Рис.22 Візуальне відображення даних кластеризації
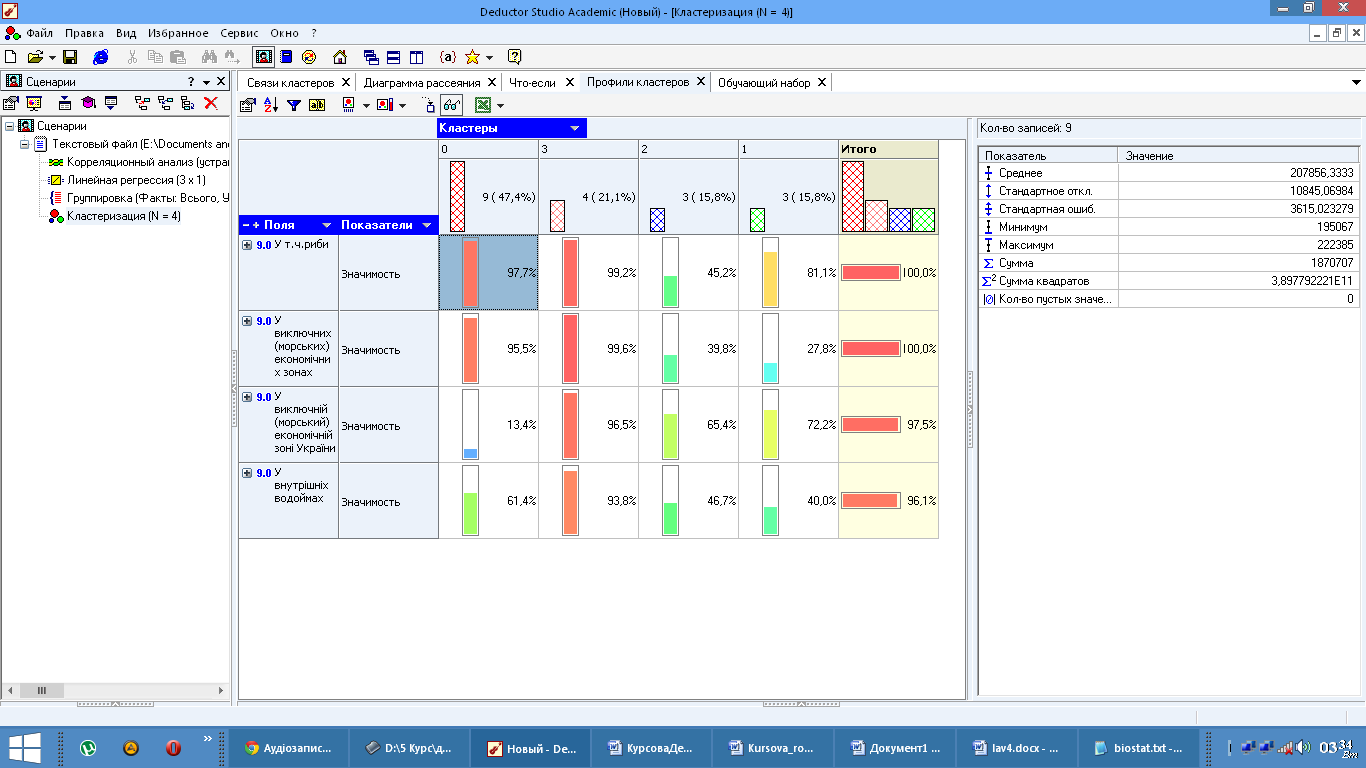
Рис.23 Профілі кластерів