

Лекція 3-4. Типи і структури даних і ER-модель
.pdfТема 2: «Типи і структури даних»
2.1. Основні типи даних
Всі дані, які необхідні для вирішення практичних задач, підрозділяються на декілька різних типів, причому поняття тип пов’язується не тільки з представленням даних в адресному просторі, а і зі способом їх обробки. Будь-які дані можуть бути віднесені до одного з двох типів: основному (простому - це - символи, числа и т.д. елементи, подальше розділення яких не має сенсу), форма представлення якого визначається архітектурою ЕОМ, чи складному, конструйованому користувачем для вирішення конкретних задач.
Будь-які дані, які використовують в програмуванні, мають свої типи даних.
Важливо! Реляційна модель потребує, щоб типи використовуваних даних були
простими.
Розглянемо, які взагалі типи даних зазвичай розглядаються в програмуванні. Як правило, типи даних поділяються на три групи:
Прості типи даних.
Структуровані типи даних.
Посилальні (Ссылочные) типи даних.
Прості типи даних
Прості, чи атомарні, типи даних не володіють внутрішньою структурою. Дані такого типу називають скалярами. До простих типів даних відносяться наступні типи:
Логічний.
Рядковий.
Чисельний.
Різні мови програмування можуть розширяти і уточняти цей список, додаючи такі типи як:
Цілий.
Дійсний (Вещественный).
Дата.
Час.
Грошовий.
Перерахований.
Інтервальний.
І т.д.…
Звичайно, поняття атомарності доволі відносне. Так, рядковий тип даних можна розглядати як одномірний масив символів, а цілий тип даних - як набір бітів. Важливо лише те, що при переході на такий низький рівень втрачається семантика (сенс) даних. Якщо рядок, який виражає, наприклад, прізвище співробітника, розкласти в масив символів, то при цьому втрачається сенс такого рядка як єдиного цілого.
Структуровані типи даних
Структуровані типи даних призначені для задання складних структур даних. Структуровані типи даних конструюються зі складових елементів, які називають компонентами, які, в свою чергу, можуть володіти структурою. В якості структурованих типів даних можна привести наступні типи даних:
Деякі структури:
Масив (функція з кінцевою областю визначення) - проста сукупність елементів даних одного типу, засіб оперування групою даних одного типу. Окремий елемент масиву задається індексом. Масив може бути одномірним, двомірним и т.д. Різновидами одномірних масивів змінної довжини являються структури типу
кільце, стек, черга і двостороння черга.
Зматематичної точки зору масив представляє собою функцію з кінцевою областю визначення. Наприклад, розглянемо кінцеву множину натуральних чисел
Яку називають множиною індексів. Відображення
із множини  в множину дійсних (вещественных) чисел
в множину дійсних (вещественных) чисел 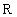 задає одномірний дійсний (вещественный) масив. Значення цієї функції для деякого значення індекса
задає одномірний дійсний (вещественный) масив. Значення цієї функції для деякого значення індекса 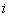 називається елементом масиву, що відповідає
називається елементом масиву, що відповідає 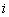 . Аналогічно можна задавати багатомірні масиви.
. Аналогічно можна задавати багатомірні масиви.
Запис (декартовий добуток) - сукупність елементів даних різного типу. В найпростішому випадку запис містить постійну кількість елементів, які називають полями. Сукупність записів однакової структури називається файлом. (Файлом називають також набір даних в зовнішній пам’яті, наприклад, на магнітному диску). Для того, щоб мати можливість витягувати з файлу окремі записи, кожному запису присвоюють унікальне ім’я чи номер, яке служить її ідентифікатором і розташовується в окремому полі. Цей ідентифікатор називають ключом.
Запис (чи структура) представляє собою кортеж із деякого декартового добутку множин. Дійсно, запис представляє собою іменований упорядкований набір елементів 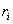 ,
,
кожен із яких належить типу 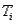 . Таким чином, запис
. Таким чином, запис 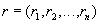 є елемент множини
є елемент множини
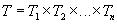 . Об’являючи нові типи записів на основі уже наявних типів, користувач може конструювати будь-які складні типи даних.
. Об’являючи нові типи записів на основі уже наявних типів, користувач може конструювати будь-які складні типи даних.
Загальним для структурованих типів даних є те, що вони мають внутрішню структуру, що використовується на тому ж рівні абстракції, що і самі типи даних.
Пояснимо це наступним чином. При роботі з масивами чи записами можна маніпулювати масивом чи записом і як з єдиним цілим (створювати, видаляти, копіювати цілі масиви чи записи), так и поелементно. Для структурованих типів даних є спеціальні функції - конструктори типів, які дозволяють створювати масиви чи записи із елементів більш простих типів.
Працюючи з простими типами даних, наприклад з числовими, ми маніпулюємо ними як нероздільними цілими об’єктами. Щоб "побачити", що числовий тип даних
насправді складний (являється набором бітів), треба перейти на більш низький рівень абстракції. На рівне програмного коду це буде виглядати як асемблері вставки в код на мові високого рівня чи використання спеціальних побітових операцій.
Посилальний (ссылочный) тип даних
Посилальний тип даних (вказівники) призначені для забезпечення можливості вказання на інші дані. Вказівники характерні для мов процедурного типу, в яких є поняття області пам’яті для зберігання даних. Посилальний тип даних призначений для обробки складних структур, які змінюються, наприклад дерев, графів, рекурсивних структур.
Такі структури даних як масив чи запис займають в пам’яті ЕОМ постійний об’єм, тому їх називають статичними структурами. До статичних структур відноситься також множина. Є ряд структур, які можуть змінювати свою довжину - динамічні структури. До них відносять дерево, список, посилання.
Важливою структурою, для розміщення елементів, якій потрібний нелінійний адресний простір, є дерево. Існує велика кількість структур даних, які можуть бути представлені як дерева. Це, наприклад, класифікаційні, ієрархічні, рекурсивні та ін. структури.
|
|
|
|
|
|
|
|
Дані |
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Складові |
|
|
|
|
|
||
|
Елементарні |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
(структурні) |
|
|
|
|
|
||||||
|
|
(прості) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Статичні |
|
|
|
|
|
|
Динамічні |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Символ |
|
… |
|
Ціле |
|
|
Масив |
|
|
Множина |
|
Дерево |
|
|
Список |
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Запис |
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 2.1. Класифікація типів даних.
Домени
В реляційній моделі даних з поняттям тип даних тісно пов’язане поняття домена, яке можна вважати уточненням типу даних.
Домен - це семантичне поняття. Домен можна розглядати як підмножину значень деякого типу даних, які мають визначений сенс. Домен характеризується наступними властивостями:
Домен має унікальне ім’я (в межах бази даних).
Домен визначений на деякому простому типові даних чи на другому домені.
Домен може мати деяку логічну умову, яка дозволяє описати підмножину даних, допустимих для даного домена.
Домен несе визначене смислове навантаження.
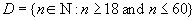
Наприклад, домен  , який має смисл "вік співробітника" можна описати як наступну підмножину множини натуральних чисел:
, який має смисл "вік співробітника" можна описати як наступну підмножину множини натуральних чисел:
Якщо тип даних можна вважати множиною всіх можливих значень даного типу, то домен нагадує підмножину в цій множині.
Відмінність домена від поняття підмножини полягає саме в тому, що домен відображає семантику, визначену предметною областю. Може бути декілька доменів, що співпадають як підмножини, але несуть різний сенс. Наприклад, домени "Маса деталі" і "Наявна кількість" можна однаково описати як множину невід’ємних цілих чисел, але сенс цих доменів буде різним, і це будуть різні домени.
Основне значення доменів полягає в тому, що домени обмежують порівняння. Некоректно, з логічної точки зору, порівнювати значення із різних доменів, навіть якщо вони мають однаковий тип. В цьому проявляється смислове обмеження доменів. Синтаксично правильний запит "видати список всіх деталей, у яких маса деталі більше наявної кількості" не відповідає сенсу понять "кількість" і "маса".
Зауваження. Поняття домена допомагає правильно моделювати предметну область. При роботі з реальною системою в принципі можлива ситуація коли потрібно відповісти на запит, приведений вище. Система дасть відповідь, але, ймовірно, вона буде безглуздою.
Зауваження. Не всі домени мають логічну умову, яка обмежує можливі значення домена. В такому випадку множина можливих значень домена співпадає з множиною можливих значень типу даних.
Зауваження. Не завжди очевидно, як задати логічну умову, яка обмежує можливі значення домена. Я буду вдячний тому, хто приведе мені умову на рядковий тип даних, що задає домен "Прізвище співробітника". Ясно, що рядки, які є прізвищами не повинні починатися з цифр, службових символів, з м’якого знаку і т.д. Але от чи є допустимим прізвище "Ггггггиииии"? Чому б і ні? Очевидно, ні! А може хтось навмисно так себе назве. Труднощі такого роду з’являються тому, що сенс реальних явищ далеко не завжди можна формально описати. Просто ми, як всі люди, інтуїтивно розуміємо, що таке прізвище, але ніхто не може дати таке формальне визначення, яке відрізняло б прізвища від рядків, які не є прізвищами. Вихід із цієї ситуації простий - покластися на розум співробітника, який вводить прізвища до комп’ютера.
2.2. Форми представлення структур даних
При створенні БнД розробляються схеми структур різних даних.
Схемою структури даних називається описання структури даних деякого типу на формалізованій мові, що відображає сукупність властивостей даного типу структури даних. Реалізація схеми, яка являється конкретною структурою даних відповідного типу, називається екземпляром схеми.
Форми представлення структур даних стандартизовані. В наш час широко використовуються наступні три форми представлення структур даних в БД: таблична, графова і графічна.
Таблична форма структури даних.
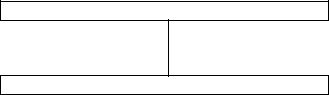
В таблиці рядки представляють екземпляри записів, а елементи рядків (чи атрибути) - екземпляри полів. Приклад наведений на рис. 2.2.1.
Тип поля 1 (Р1) |
Тип поля 2 (Р2) |
. . . |
Тип поля N (PN) |
Значення р1,1 |
Значення р2,1 |
. |
Значення рn,1 |
|
|
. |
|
Значення р1,2 |
Значення р2,2 |
. |
Значення pn,2 |
|
|
. |
|
. . . |
. . . |
. . . |
. . . |
Рис. 2.2.1. Таблична форма
Графова форма структури даних.
Графова форма полегшує розуміння та інтерпретацію даних. На графі сутності (сущности), що моделюються записами, відображаються вершинами графа - прямокутниками (рис. 2.2.2.), а зв’язки між сутностями відображаються відповідними дугами. Над вершинами вказуються типи записів, в вершинах приводяться типи полів, причому типи полів-ідентифікаторів підкреслюються. Типи зв’язків записуються вздовж дуг.
Відділ
№ Відділу, НазваВідділу
ПрацюєВ
Співробітник
№Таб., ПІБ, Посада
Рис. 2.2.2. Графова форма
Графічна діаграма структури даних.
Ціль діаграми полягає в більш виразній деталізації елементів. На діаграмі використовуються наступні позначення:
типи сутностей позначаються прямокутниками;
атрибути позначаються овалами, які з’єднані з відповідними типами сутностей ненаправленими дугами; ключі підкреслюються;
відношення (чи зв’язки) відображаються ромбами, які з’єднуються з відповідними типами сутностей при бінарних зв’язках направленими дугами, а при інших зв’язках - ненаправленими дугами.
Приклад графічної діаграми структури даних наведений на рис. 2.2.3.
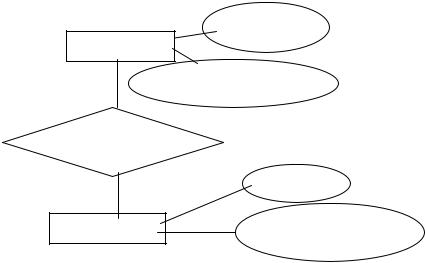
|
№Відділу |
Відділ |
|
|
НазваВідділу |
ПрацюєВ |
|
|
№Таб |
Співробітник |
Посада |
Рис. 2.2.3. Графічна діаграма
2.3. Методи доступу до даних
Запитання представлення даних тісно пов’язані з операціями, за допомогою яких ці дані обробляються. До числа таких операцій відносяться: вибірка, зміна, включення і виключення даних. В основі всіх перерахованих операцій лежить операція доступу, яку не можна розглядати незалежно від способу представлення.
В задачах пошуку передбачається, що всі дані зберігаються в пам’яті з визначеною ідентифікацією і, говорячи про доступ, мають на увазі, перш за все, доступ до даних (які називають ключами), однозначно ідентифікують пов’язані з ними сукупності даних.
Існують два класи методів, які реалізують доступ до даних по ключу:
методи пошуку по дереву,
методи хешування (хеширования).
2.3.1. Методи пошуку по дереву
Визначення: Деревом називається кінцева множина, яка складається із одного чи більше елементів, які називають вузлами, такі, що:
1.між вузлами має місце відношення типу "вихідний - породжений";
2.є тільки один вузол, який не має вихідного вузла. Він називається коренем;
3.всі вузли за виключенням кореня мають тільки один вихідний; кожен вузол може мати декілька породжених вузлів;
4.відношення " вихідний - породжений " діє тільки в одному напрямку, тобто ні один нащадок деякого вузла не може стати для нього предком.
Число породжених окремого вузла (число піддерев даного кореня) називається його степенем. Вузол з нульовим степенем називають листом чи кінцевим вузлом. Максимальне значення степеня всіх вузлів даного дерева називається степенем дерева.
Якщо в дереві між породженими вузлами, які мають спільний вихідний, вважається істотним їх порядок, то дерево називається упорядкованим. В задачах пошуку майже завжди розглядаються упорядковані дерева.
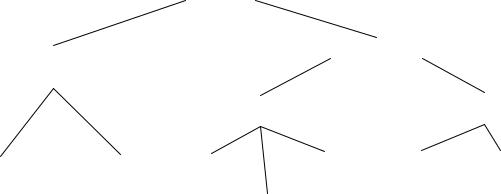
Упорядковане дерево, степінь якого не більше 2 називається бінарним деревом. Бінарне дерево особливо часто використовується при пошуку в оперативній пам’яті. Алгоритм пошуку: спочатку аргумент пошуку порівнюється з ключем, що знаходиться в корені. Якщо аргумент співпадає з ключем, пошук завершений, якщо ж не співпадає, то у випадку, коли аргумент виявляється менше ключа, пошук продовжується в лівому піддереві, а у випадку, коли більше ключа - в правому піддереві. Збільшивши рівень на 1, повторюють порівняння, вважаючи поточний вузол коренем.
Приклад: Нехай даний список студентів, який вміщає їх прізвища та середній бал успішності (див. таблицю 1). В якості ключа використовується прізвище студента. Припустимо, що всі записи мають фіксовану довжину, тоді в якості вказівника можна використовувати номер запису. Зміщення запису в файлі в цьому випадку буде рахуватися як ([номер_запису] -1 ) * [довжина_запису]. Нехай аргумент пошуку "Петров". На рисунку 2.3.1. показано одне із можливих для цього набору даних бінарне дерево пошуку і шлях пошуку.
Замітимо, що тут використовується наступне правило порівняння рядкових змінних: вважається, що значення символа відповідає його порядковому номеру в алфавіті. Тому "І" менше "К", а "К" менше "С". Якщо поточні символи в порівнюваних рядках співпадають, то порівнюються символи в наступних позиціях.
Таблиця 1
|
|
Студент |
|
Бал |
|
|
|
|
|
|
|
|
|
|
|
Васильєв |
|
4,2 |
|
|
|
|
|
|
|
|
|
|
|
Іванов |
|
3,4 |
|
|
|
|
|
|
|
|
|
|
|
Кузнєцов |
|
3,5 |
|
|
|
|
|
|
|
|
|
|
|
Петров |
|
3,2 |
|
|
|
|
|
|
|
|
|
|
|
Сидоров |
|
4,6 |
|
|
|
|
|
|
|
|
|
|
|
Тихомиров |
|
3,8 |
|
|
|
|
|
|
|
|
|
|
|
Кузнєцов |
|
|
|
|
Іванов |
|
Сидоров |
||||
Васильєв |
Петров |
Тихомиров |
Рис. 2.3.1. Пошук по бінарному дереву
Бінарні дерева особливо ефективні у випадку, коли множина ключів зарані невідома, або коли ця множина інтенсивно змінюється. Очевидно, що при змінній множині ключів краще мати збалансоване дерево.
2.3.2. Хешування (Хеширование)
Цей метод використовується тоді, коли вся множина ключів зарані невідома і на час обробки може бути розміщена в оперативній пам’яті. В цьому випадку будується спеціальна функція, яка однозначно відображає множину ключів на множину вказівників, яка називається хеш-функцією (від англійського слова "to hash" - різати, подрібнювати). Маючи таку функцію можна вираховувати адрес запису в файле по заданому ключу пошуку. В загальному випадку, ключові дані, які використовують для визначення адреси запису, організовуються у вигляді таблиці, яку називають хеш-таблицею.
Якщо множина ключів зарані невідома чи дуже велика, то від ідеї однозначного вираховування адреси запису по її ключу відмовляються, а хеш-функцію розглядають просто як функцію, яка розсіює множину ключів в множину адрес.
Тема 3: «Представлення даних за допомогою
моделі " сутність-зв'язок " ER – model»
3.1. Призначення і елементи моделі
Перед тим, як приступити до створення системи автоматизованої обробки інформації, розробник повинен сформувати поняття про предмети, факти і події, якими буде оперувати дана система. Одним із найбільш зручних інструментів уніфікованого представлення даних, незалежно від реалізуючого його програмного забезпечення,
являється модель " сутність-зв'язок " (entity - relationship model, ER - model), яка базується на деякій важливій семантичній інформації про реальний світ і призначена для логічного представлення даних, так як не визначає операцій над даними. Вона визначає значення даних в контексті їх взаємозв’язку з другими даними. Важливим для нас являється той факт, що із моделі " сутність-зв'язок " (була запропонована в 1976 г. Пітером Пін-Шен Ченом) можуть бути породжені всі існуючі моделі даних (ієрархічна, мережева, реляційна, об’єктна), тому вона являється найбільш загальною.
Будь-який фрагмент предметної області може буть представлений як множина сутностей, між яким існує деяка множина зв’язків.
Сутність (entity) - це об’єкт, який може бути ідентифікований деяким способом, який відрізняє його від інших об’єктів. Приклади: конкретна людина, підприємство, подія і т.д. Сутність, фактично, представляється множиною атрибутів, які описують властивості всіх членів даного набору сутностей.
Набір сутностей (entity set) - множина сутностей одного типу (які володіють однаковими властивостями). Приклади: всі люди, підприємства, свята і т.д. Набори сутностей не обов’язково мають бути неперетинаючимися. Наприклад, сутність, яка належить до набору ЧОЛОВІКИ, також належить набору ЛЮДИ.
В подальшому для визначення сутності та її атрибутів будемо використовувати позначення виду: СПІВРОБІТНИК (ТАБЕЛЬНИЙ_НОМЕР, ІМ’Я, ВІК). Наприклад,
відділи, на які підрозділяється підприємство, і в яких працюють співробітники, можна описати як ВІДДІЛ(НОМЕР_ВІДДІЛУ, НАЙМЕНУВАННЯ).
Множина значень (область визначення) атрибута називається доменом. Наприклад, для атрибута ВІК домен (назвемо його ЧИСЛО_РОКІВ) задається інтервалом цілих чисел більших нуля, оскільки людей з від’ємним віком не буває.
Атрибут визначається як функція, яка відображає набір сутностей в набір значень чи в декартовий добуток наборів значень. Так атрибут ВІК виробляє (производит)
відображення в набір значень (домен) ЧИСЛО_РОКІВ. Атрибут ІМ’Я виробляє (производит) відображення в декартовий добуток наборів значень ІМ’Я, ПРІЗВИЩЕ та По-батькові.
Отже, ключ сутності - група атрибутів, така, що відображення набору сутностей в відповідну групу наборів значень є взаємно однозначним відображенням, тобто - це один чи більше атрибутів, які унікально визначають дану сутність. В нашому прикладі ключем сутності СПІВРОБІТНИК являється атрибут ТАБЕЛЬНИЙ_НОМЕР (звичайно, тільки в тому випадку, якщо всі табельні номери на підприємстві унікальні).
Зв’язок (relationship) - це асоціація, встановлена між кількома сутностями. Приклади:
оскільки кожний співробітник працює в якомусь відділі, між сутностями СПІВРОБІТНИК і ВІДДІЛ існує зв’язок "працює в" чи ВІДДІЛ-ПРАЦІВНИК;
так як один із робітників відділу являється його керівником, то між сутностями СПІВРОБІТНИК і ВІДДІЛ існує зв’язок "керує" чи ВІДДІЛ-КЕРІВНИК;
можуть існувати і зв’язки між сутностями одного типу, наприклад зв’язок БАТЬКО - НАЩАДОК між двома сутностями ЛЮДИНА;
Зв’язок також може мати атрибути. Наприклад, для зв’язку ВІДДІЛ-ПРАЦІВНИК можна задати атрибут СТАЖ_РОБОТИ_У_ВІДДІЛІ.
Роль сутності в зв’язку - функція, яку виконує сутність в даному зв’язку. Наприклад, в зв’язку РОДИТЕЛЬ-НАЩАДОК сутності ЛЮДИНА можуть мати ролі "батько" і "нащадок". Указання ролей в моделі "сутність-зв'язок" не є обов’язковим і служить для уточнення семантики зв’язку.
Набір зв’язків (relationship set) - це відношення між n (причому n не менше 2) сутностями, кожна із яких відноситься до деякого набору сутностей.
У випадку n=2, тобто коли зв’язок поєднує дві сутності, вона називається бінарною. Доведено, що n-арний набір зв’язків (n>2) завжди можна замінити множиною бінарних, однак перші краще відображають семантику предметної області.
Те число сутностей, яке може бути асоційовано через набір зв’язків з іншою сутністю, називають степенем зв’язку. Розглядання степенів особливо корисно для бінарних зв’язків. Можуть існувати наступні степені бінарних зв’язків:
один до одного (позначається 1 : 1). Це означає, що в такому зв’язку сутності з однією роллю завжди відповідає не більше однієї сутності з іншою роллю. В розгляненому нами прикладі це зв’язок "керує", оскільки в кожному відділі може бути тільки один начальник, а співробітник може керувати тільки в одному відділі.
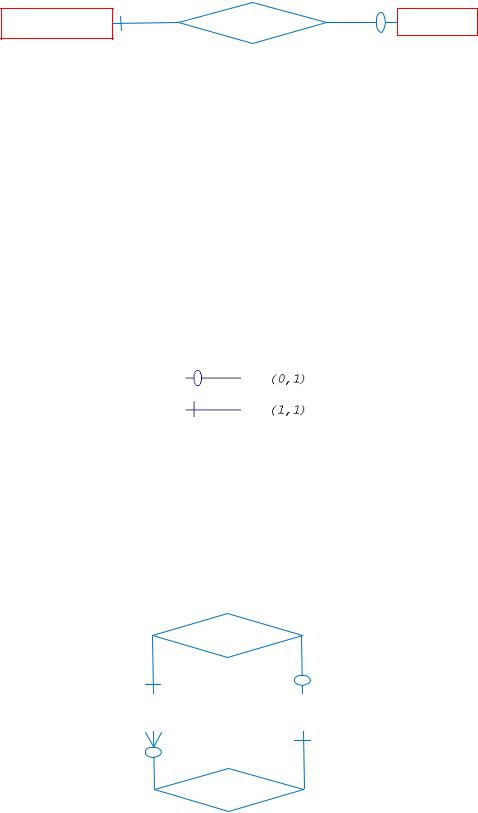
Даний факт представлений на наступному рисунку, де прямокутники позначають сутності, а ромб – зв’язок. Так як степінь зв'язку для кожної сутності дорівнює 1, то вони з'єднуються однією лінією.
Співробітник |
Керує |
Відділ |
Іншою важливою характеристикою зв’язку окрім його степені являється клас приналежності сутностей, які входять до нього чи кардинальність зв’язку. Так як в кожному відділі обов’язково повинен бути керівник, то кожній сутності "ВІДДІЛ" обов’язково повинна відповідати сутність "СПІВРОБІТНИК". Однак, не кожен співробітник являється керівником відділу, отже в даному зв’язку не кожна сутність "СПІВРОБІТНИК" має асоційовану з нею сутність "ВІДДІЛ".
Таким чином, говорять, що сутність "СПІВРОБІТНИК" має обов’язковий клас приналежності (цей факт позначається також вказанням інтервалу числа можливих входжень сутності в зв’язок, в даному випадку це 1,1), а сутність "ВІДДІЛ" має необов’язковий клас приналежності (0,1). Тепер даний зв’язок ми можемо описати як 0,1:1,1. В подальшому кардинальність бінарних зв’язків степені 1 будемо позначати наступним чином:
один до багатьох ( 1 : n ). В даному випадку сутності з однією роллю може відповідати будь-яке число сутностей з іншою роллю. Такий зв’язок ВІДДІЛСПІВРОБІТНИК. В кожному відділі може працювати довільна кількість співробітників, але співробітник може працювати тільки в одному відділі. Графічно степінь зв’язку n відображається "деревоподібною" лінією, так це зроблено на наступному рисунку, який додатково ілюструє той факт, що між двома сутностями може бути визначено декілька наборів зв’язків.
керує
Співробітник |
|
Відділ |
|
|
|
працює в
Тут також необхідно враховувати клас приналежності сутностей. Кожен співробітник повинен працювати в якомусь відділі, але не кожен відділ (наприклад, знову сформований) повинен включати хоча б одного співробітника. Тому сутність "ВІДДІЛ"