

Высшая математика / 2 / шпоры матем 31-39
.docx31.Интервальные оценки параметров распределения.
Пусть Ө(хи) неизвестн. Параметр,а Ө* его не смещённая оценка.Точечные оценки дают хорошие результаты для больших объёмов выборок. Для малых выборок n<30 используются оценки определяемые 2умя числами –концами интервала внутри к. находится неизвестн. Параметр.Очевидно, что оценка Ө* будет чем точнее, чем меньше разность |Ө-Ө*|,т.е.чем меньше число б ,такое что|Ө-Ө*|<б .Данное неравенство раскрывая модуль можно записать: |Ө-Ө*|<б <=> Ө*-б <Ө<б+ Ө*.Статистич.методы не позволяют строго утверждать выполняется данное неравенство или нет.О выполнении равенства можно судить с определённой долей уверенности или вероятности,кот.назыв. доверительной вероятностью r (гамма).r= Р(|Ө-Ө*|<б ).При решении задачrзадаётся заранее и как правило=0,9;0,95;0,99.Интервал в к.находится Ө-доверительный интервал.
32.Условные варианты. Условные эмпирические моменты.
Усл.варианты. Предположим, что варианты выборки расположены в возрастающем порядке,т.е.в виде вариационного ряда.Равноотстоящими назыв.варианты,к.образуют арифметич.прогрессию с разностью(h).Условными назыв.варианты определяемые равенством Ui=( хi -с )/ h, С-ложный ноль,h-шаг между любыми соседними первоначальными вариантами.Усл.эмпирич.моменты.Вычисление центральных моментов достаточно громодко, поэтому заменим первонач.варианты условными.Условн. эмпирич.моментом порядка(к)назыв.начальный момент порядка(к) вычисленный для усл.вариант : Мк*=(∑ni uik) /n=(∑ni × ( хi -с / h)к)/h. В частности М1*=(∑ni *( хi -с/h)1)/h=1/h((∑ni хi )/n)-(∑ni с/n))=1/h(х̅в –с), выразим х̅в => х̅в = М1*× h+с. Аналогично рассуждая получим Dв=( М2*-( М1*)2) × h2.
33.Обычные,начальные и центральные эмпирич.моменты.
Обычные эмпирическим моментом порядка(к) назыв. ср.значение (к-х) степеней разности(хi-с): М’k=(∑ni × ( хi –с)k)/n,где хi-наблюдаемые варианты, ni-частоты соответствующих вариант, n-объём выборки, с-ложный ноль. Начальным эмпирич.моментом порядка(к) назыв. обычный момент порядка(к) при (с=0): Мк=∑ni хкi/ n в частности М1=∑ni х1i/ n= х̅в т.е.начальный эмпирический момент 1-ого порядка= х̅в. Центральным эмпирич.моментом порядка (к)наз.обычный момент порядка (к) при(с= х̅в): mk=∑ni(хi- х̅в)к/n в частности m2=∑ni(хi- х̅в)2/n= Dв т.е. центр. эмпирич.момент 2-ого порядка = Dв. Легко вывести,что m2= М’2-( М’1)2 ; m3= М’3-3 М’2 М’1+2(М’1)3 ; m4= М’4-4 М’3 М’1+6М’2(М’1)2-3( М’1)4
34. Эмпирические и выравнивающие частоты для дискретного распределения.
Рассмотрим дискретн. СВ(х) закон распределения к. не известен.Пусть произведено (n) испытаний в к. СВ(х)приняла(n1) раз значение(х1),( n2)раза значение(х2)и т.д. при чём сумма(ni= n).эмпирич.частотами –назыв. фактически наблюдаемые частоты(ni)-ые.Пусть имеется основание предположить,что изучаемая величина(х) распределена по некоторому опред.закону .Чтобы проверить согласуется ли это предположение с данными наблюдений вычисляют частоты наблюдаемых значений т.е.находят теоретические частоты (mi)каждого из наблюдаемых значений предположении,что величина(х)распределена по данному закону.Выравнивающими частотами назыв-я числа (ni) к-ое находится из равенства n’i= nPi , где n-число испытаний, Pi-вероятность наблюдаемого значения (хi) вычисленное при допущении,чтоСВ(х)имеет предполагаемое распределение.Таким образом выравнивающая частота наблюдаемого значения (хi)дискретного распределения равна произведению числа испытаний н вероятность этого наблюдаемого значения.
35. Эмпирические и выравнивающие частоты для непрерывного распределения.
В случае непрерывного распределения признака (х) ген.совокупности вероятности отдельных возможных значений(=0),поэтому весь интервал возможных значений разбивают на (к)интервалов и находят вероятности (Pi) попадаются СВ (х) в итый частичный интервал, затем, как и для дискретного распределения умножают число испытаний на эти вероятности. Таким образом выравнивающие частоты непрерывного распределения нах. по ф. : n’i= nPi . Для нормально распределённой СВ (х) формула запишется в виде: n’i= nPi=nh/٧B×фи(ui), где ui= (хi- х̅в)/ ٧B.
36. Условные средние. Выборочные уравнения регрессии.
При изучении двумерной СВ (ху)рассматривают не только числовые хар-ки одномерных компонент.(х)и(у) но и числовые хар-ки условных распределений. Условным мат. Ожиданием СВ (у) назыв. её мат.ожидание вычисленное при условии, что СВ(х) приняла опред.значение.РХ=х(У)=Р(У\Х=Х) \-вычитание. Для дискретной СВ(х) и (у)условные мат.ожидания вычисляются по формулам М(У\х)=∑УIР(УI\хI) ; М(Х\у)=∑хIР(ХI\уI).В качестве оценок условных мат.ожиданий принимают условные средние к.находятся по выборке.Условным средним(у̅х)назыв.ср. арифметическое наблюдавшихся значений(У)соответствующих(Х=х).Условным ср.( х̅у)назыв.ср.арифметич.наблюдавшихся значений (Х)соответствующих(У=у)
37. Выборочные ур-я прямой линии регрессии по несгруппир. данным
Пусть
изучаемая система количественных
признаков(Х,У) в результате (n)испытаний
получены пары
чисел(х1;у1);(х2;у2)…(хn;уn).Предположим
,что выборочная регрессия (Уна
х)является линейной и будем искать
уравнение выборочной регрессии в виде:
у̅х=(кх+b),где
к и в подлежат
пределению.Параметр (к)(условный коэф-т
прямой)назыв.выборочным коэф.(Уна
х).Подберём параметры к и b
так,чтобы точки построенные по данным
наблюдений лежали на плоскости Оху
как можно ближе к прямой.Для этого
воспользуемся методом наименьших
квадратов. Назовём отклонением
разность(у̅х-уi),где
у̅х-вычесленное
по ур-ию у̅х=кх+
b
ордината при
соответствующих значениях (хi).Подберём
параметры к и в таким образом,чтобы
сумма квадратов отклонений была мин.для
этого составим функцию F(k;b)=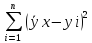 =
=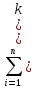 )2
Для
определения минимума функц. найдём
стационарные точки:
)2
Для
определения минимума функц. найдём
стационарные точки:
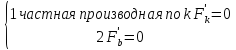 ;
;
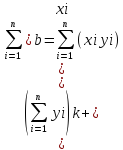 Полученная
система явл-я линейной относительно
переменных (k)
и (b),решив
её например методом Крамера получим
значения (k)
и (b)
и составим выборочное уравнение
регрессии (У на х).
Полученная
система явл-я линейной относительно
переменных (k)
и (b),решив
её например методом Крамера получим
значения (k)
и (b)
и составим выборочное уравнение
регрессии (У на х).
38. Выборочные уравнения прямой линии регрессии по сгруппированным данным.
При большом числе
наблюдений одно и тоже значение(х) может
встретиться (nх)раз.Одно
и тоже значение(у)-(
nу)
раз.Одно и тоже значение (х,у)-(
nху)
раз.Поэтому данные группируют,
подсчитывают частоты и сгруппированные
данные вносят в таблицу,кот.назыв.корреляционной.Введём
обозначения
: ∑
хi=n
х̅в=n
х̅ ;
∑ уi=n
у̅B=n
у̅ ; ∑ х2i=n
х̅2B=n
х̅2
; ∑ хi
уi=nxyxiyi=>
х̅у̅ =1/n∑
хi
уi
nxy
Тогда система для нахождения параметров
(k)
и (b)
примет вид :
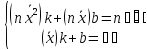 ; b=
у̅- х̅k
подставим в
линейное уравнение у̅x=kx+b
и получим
у̅x=kx+
у̅- х̅k
преобразуем
уравнение у̅x-
у̅=k(x-
х̅) Из системы
выразим коэф(k):
k=(
n
х̅у̅- n
х̅ у̅)/( n
х̅2-
n
(х̅)2
)= (х̅у̅ - х̅ у̅)/( х̅2-(х̅)2)=
(х̅у̅ - х̅ у̅) /
(٧х)2.
; b=
у̅- х̅k
подставим в
линейное уравнение у̅x=kx+b
и получим
у̅x=kx+
у̅- х̅k
преобразуем
уравнение у̅x-
у̅=k(x-
х̅) Из системы
выразим коэф(k):
k=(
n
х̅у̅- n
х̅ у̅)/( n
х̅2-
n
(х̅)2
)= (х̅у̅ - х̅ у̅)/( х̅2-(х̅)2)=
(х̅у̅ - х̅ у̅) /
(٧х)2.
39. Выборочный коэф. корреляции . Коэф.детерминации.
Выбор.коэф.корреляции назыв величина rв= (х̅у̅- х̅ у̅)/ ٧х٧у, | rв |≤1, Уравнение прямой регрессии(Ух) может быть записано в виде у̅x-у̅= rв(٧у/٧х)(х- х̅).Уравнение прямой регрессии(Ху): х̅в- х̅= rв(٧х/٧у)(у- у̅).Замечание: Прямые регрессии(Ух) и (Ху) разные,обе проходят через точку с координатами(х̅; у̅).Чем меньше угол между прямыми, тем теснее линейная зависимость между(х)и (у).Известно, что если прямые(х) и (у) ген.совокупности независимы,то их коэф.корреляции rг=0,Если же коэф корреляции ген. совокупности =±1, то х и у связаны функциональной зависимостью.Выборочный коэф.корреляции явл-я оценкой коэф-та корреляции ген.совокупности и поэтому так же служит для измерения линейной связи между признаками х и у.Для проверки нулевой гипотезы составляем выборочную статистику.затем по таблице критич.точек распределения Стьюдента находим tкр(α;n-2)Если|tнабл|<|tкр|,то гипотезу Н0-принимаем,иначе-отвергаем и принимаем альтернативную гипотезу Н1.Число (r2в)-называется коэф.детерминации, оно определяет долю рассеивания, наблюдаемых значений СВ(У) относительно значений полученных их уравнения регрессии(Ух).Остальная доля отклонений может быть вызвана либо случ.ошибками,либо тем, что линейная регрессионная модель плохо согласуется с экспериментальными данными.