

СПКД123 / СПДК / Задачи АСУТП / Лекция 13. Программирование задач информационных обменов
.doc|
Лекция 13. Программирование задач информационных обменов Содержание лекции:
На предыдущей лекции нами были рассмотрены информационные обмены ДП АСУТП: взаимодействие с системой телемеханики, передача данных другим информационным системам управления и автоматизации производственно-хозяйственной деятельности. В системах реального времени программа, выполняющая передачу информации, может играть одну из следующих ролей (реализуя соответствующие функции):
Клиент и сервер могут взаимодействовать по-разному: или обмениваясь пакетами байт определенного формата по последовательному каналу или сети передачи данных; или напрямую, используя механизмы распределенной работы приложений (DCOM и, в частности, надстройку над ним – OPC; механизм RPC; системы на базе CORBA и т.д.). Общим для программ всех типов является то, что они не имеют пользовательского интерфейса: выполняясь в многозадачной ОС, они запускаются автоматически при старте программного комплекса ДП или планировщиком процессов по определенному регламенту. Конфигурационные параметры определяются в командной строке, инициализационном файле или считываются непосредственно из определенного объекта базы данных; эти методы могут комбинироваться. Аналогично всем прочим процессам ДП АСУТП, программы информационных обменов ориентированы на непрерывную работу в режиме периодического (или, реже, апериодического) выполнение заложенных алгоритмов. За последние годы производительность ЭВМ – серверов ДП АСУТП выросла намного больше, чем объем передаваемой оперативной технологической информации в единицу времени, поэтому требования к оптимизации программного кода по производительности или объему занимаемой памяти не являются в настоящий момент критическими. Однако от разработчика требуется гарантировать отсутствие «утечек памяти» – динамического выделения памяти без последующего ее освобождения. Помимо их отсутствия в устойчивом режиме работы, требуется обеспечить освобождение выделенной памяти при сбоях (напр., ошибках приема/передачи данных, возникающих на низкокачественных линиях связи тональной частоты), что сильно усложняет процесс тестирования ПО. В этой лекции мы рассмотрим вопросы проектирования структуры программ, реализующих информационные обмены. Здесь, как и в остальных областях, проявляются достоинства объектно-ориентированной методологии, также применимы универсальные шаблоны проектирования, широко рассмотренные в литературе.
Действия программы, реализующей некоторую передачу информации, всегда управляются внешними событиями. При получении события программа выполняет определенные действия, после чего переходит в режим ожидания. События бывают следующих видов:
В первом случае возможно две ситуации: настройка частоты вызовов произведена внешней программой-менеджером, которая, возможно, сама и запустила нашу программу; или сама программа информационного стыка при запуске создала и запустила свой таймер. Для программы-сервера «пользователем» обычно является одна или несколько программ-клиентов, которые выполняют инициализацию, периодически запрашивают наборы данных или сведения об изменении. Для клиента «пользователь» – или программа-менеджер, планировщик процессов и т.п., или оператор ДП АСУТП – графический интерфейс ДП позволяет вводить команды и, посредством процессов ядра ДП АСУТП, передавать их программе-клиенту информационного обмена, не имеющей своего графического интерфейса. События, вызванные поступлением данных, управляют действиями сервера, клиента в случае передачи сервером спонтанных (SRBX) сообщений, программой-импортером (событие – появление нового файла данных).
Шаблоны помогают распределить «обязанности» между классами при проектировании системы. Так, К. Ларман в своей книге «Применение UML и шаблонов проектирования» вводит набор общих шаблонов распределения обязанностей (General Responsibility Assignment Software Patterns):
Классическими
книгами
по
шаблонам
проектирования
являются:
Gamma E., Helm R., Johnson R. And Vlissides J. «Design Patterns»;
Buschmann F., Meunier R., Rohnert H., Sommerlad P.
«Pattern-Oriented Software Architecture»; Fowler M. «Analysis
Patterns: Reusable Object Models» и
«Patterns of Enterprise Application Architecture» (см.
также www.martinfowler.com).
В
этих книгах вводятся шаблоны, также
распределяющие обязанности, но при
этом впрямую влияющие не только на
архитектуру, но и на программную
реализацию проектируемой системы.
Они могут быть разбиты на несколько
групп: шаблоны для реализации
прецедентов, шаблоны для проектирования
взаимодействия с базой данных, шаблоны
для распределенной работы, выполнения
вычислений и др.
Далее мы рассмотрим
применение шаблонов при введении и
проектировании отдельных модулей
программ информационных обменов.
При
реализации программы-клиента,
управляемой обычно событиями первых
двух видов, эффективно использование
шаблона Controller (иначе – Facade, иногда
различают UseCaseController – класс-контроллер,
реализующий логику прецедентов, см.
рис. 13.1а, и FacadeController – класс, обеспечивающий
внешний интерфейс системы, см. рис.
13.1б).
В простейшем случае, программе информационного обмена требуется минимум конфигурационных данных. Это – настройки коммуникации: имя удаленного хоста и номер порта для сетевого клиента; скорость передачи данных, количество стартовых, стоповых и бит данных, четность для сервера и клиента, взаимодействующих по последовательному каналу связи; имена каталога и файлов для программы, выполняющей экспорт/импорт файлов данных. Однако при этом требуется, чтобы внешний процесс, управляющий программой-клиентом, каждый раз при запросе выполнения определенных действий (чтения, записи) передавал бы и список имен параметров (сигналов), для которых требуется выполнить это действие. В свою очередь, клиент должен передать этот список имен серверу, также получающему информацию «по необходимости». Такой подход неэффективен с точки зрения производительности, т.к. требует передачи существенно больших объемов данных при каждой транзакции, выполнения сервером доступа к данным, используя символьную, а не цифровую адресацию. Недостатком этого подхода также является то, что из-за отсутствия фазы начальной инициализации невозможно определить ошибки в параметрах (именах сигналов в удаленной базе) до того, как будет выполнена попытка чтения или записи каждого из сигналов. Поэтому каждая программа информационного обмена содержит в себе массив конфигурационных данных реализуемого взаимодействия. Для клиента это таблично организованный список сигналов, который хранится в базе данных или текстовом файле. Каждая строка списка имеет следующие поля (пример):
Сервер содержит часть конфигурационной информации, согласующейся с данными клиента, также при инициализации сервер выполняет часть операций, ускоряющие последующую обработку запросов: определение цифровых адресов объектов БД по их символьным именам; динамическое выделение памяти для временного хранения значений и т.п. В сервере могут быть реализованы три механизма формирования пространства имен:
Сохранение
конфигурационной информации требует
определения структур данных для
хранения информации, поиска (доступа)
по передающимся в составе сообщений
идентификаторам для выполнения
требуемых операций. Такие структуры
обычно иерархически организованы. На
рис. 13.5. приведен пример типовой
структуры данных сервера.
Для
каждого подключившегося клиента
сервер создает пространство имен
(массив TagsStorage). В него входит шесть
групп (коллекций) тегов: 3 группы для
скалярных, векторных, табличных
сигналов и еще 3 группы – для сигналов,
поддерживающих передачу изменений
(PRBX-сигналов). Клиент в направляемых
серверу запросах (переинициализации
– удалении всех тегов из списка, на
добавление сигнала, чтение/запись его
значений) указывает функциональный
код fc, который определяет, с какой
группой требуется выполнить
операции.
|
 Рис.
13.1. Использование шаблона Controller
(Facade).
Для некоторых программ
требуется реализовать вариативный
доступ к различным программным модулям,
взаимодействующим с различными
ресурсами. Например, передача данных
между клиентом и сервером может
осуществляться по последовательному
каналу связи или по сети, с использованием
одного из множества протоколов. В
таких случаях применяют шаблон Adapter,
который подразумевает введение
дополнительного класса, унифицирующего
интерфейсы компонентов и принимающего
внешние вызовы (выполняет в какой-то
мере роль контроллера).
Рис.
13.1. Использование шаблона Controller
(Facade).
Для некоторых программ
требуется реализовать вариативный
доступ к различным программным модулям,
взаимодействующим с различными
ресурсами. Например, передача данных
между клиентом и сервером может
осуществляться по последовательному
каналу связи или по сети, с использованием
одного из множества протоколов. В
таких случаях применяют шаблон Adapter,
который подразумевает введение
дополнительного класса, унифицирующего
интерфейсы компонентов и принимающего
внешние вызовы (выполняет в какой-то
мере роль контроллера).
 Рис.
13.2. Введение класса-адаптера,
унифицирующего интерфейсы.
Как
адаптер мы модем рассматривать и
чистый интерфейс, реализуемый
несколькими классами. Тогда, в дополнение
используется шаблон Factory (вводится
производящий класс (factory class), возвращающий
интерфейс и создающий, при необходимости,
экземпляр функционального
класса).
Рис.
13.2. Введение класса-адаптера,
унифицирующего интерфейсы.
Как
адаптер мы модем рассматривать и
чистый интерфейс, реализуемый
несколькими классами. Тогда, в дополнение
используется шаблон Factory (вводится
производящий класс (factory class), возвращающий
интерфейс и создающий, при необходимости,
экземпляр функционального
класса).
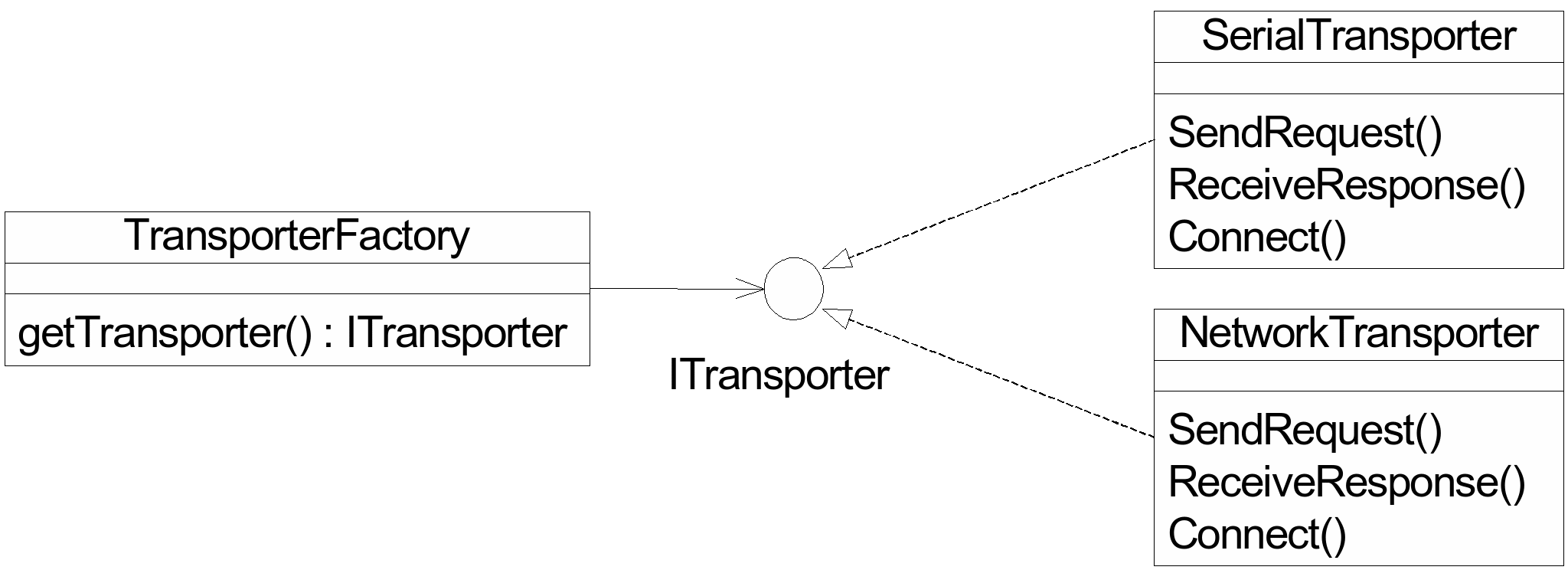 Рис.
13.3. Использование интерфейса-адаптера
и
производящего класса.
Ряд
действий в программах выполняются
модулями, существующими в единственном
экземпляре в памяти: разбиение массива
прикладных данных на фреймы, передаваемые
по линии связи, и обратное преобразование;
вычисление контрольной суммы; запись
сообщений в log-файл. На программном
уровне это достигается использованием
статического класса/функции, или
создания экземпляра и доступ к нему
через метод getInstance(). На уровне
проектирования «единственный экземпляр
объекта в памяти» определяется как
шаблон Singleton.
Как упоминалось выше,
в большинстве протоколов взаимодействие
клиента и сервера осуществляется
посредством обмена сообщениями. Каждый
протокол определяет набор типов
сообщений и их структуру: заголовок,
область данных и т.п. С точки зрения
проектирования, каждый тип сообщения
можно представить в виде класса,
отношение наследования. Поскольку
набор методов, которые требуется
реализовать в каждом классе, неизменен
(например, конструктор и метод записи
атрибутов класса в поток байт,
традиционно называемый Serialize()), то
получаемая иерархия классов –
гомоморфная. Преимущества этого –
возможность всегда оперировать
указателем на абстрактный базовый
класс в уверенности, что никакой
производный класс не содержит
дополнительных операций и не придется
выполнять динамическое приведение
или определение типа, и т.о. добиться
универсализации работы с сообщениями
любых типов в программе. Также при
создании иерархии классов сообщений
полезно применить метод создания их
экземпляров с использованием статической
производящей функции (factory function, см.
Дж. Элджер «С++: библиотека программиста»).
Это также применение шаблона
проектирования Factory, позволяющее
сокрыть и от клиента, и от сервера все
производные от базовых классы сообщений.
Производящая функция сама определяет,
сообщение какого типа следует создать
(опираясь на переданные параметры) и
возвращает указатель на базовый класс
сообщения.
Ориентация клиента и
сервера на использование сообщений
определенного набора типов, каждый
из которых определяет некоторое
действие, которое требуется выполнить,
также позволяет использовать шаблоны
Command и CommandProcessor. Каждое сообщение
является командой, а объекты-контроллеры
клиента и сервера являются процессорами
этих команд, самостоятельно реализующие
логику работы с БД на основе этих
команд (см. рис. 13.4а). Противоположностью
разделения команд и их обработчика
была бы инкапсуляция механизма работы
с базой данных в классы сообщений.
Тогда помимо общего метода Serialize(), в
каждом запросе требовалось бы
реализовать некоторый метод Run(). Однако
такой подход обладает рядом недостатков
(см. рис. 13.4б). Во-первых, становится
невозможной взаимно независимая,
использующая только общий набор
классов сообщений, разработка,
компиляция и связывание клиента и
сервера. Во-вторых, если выполнение
самим запросом действий на сервере
достаточно легко реализуемо, то
«самоформирование» запроса на клиенте
весьма затруднительно. В-третьих,
создание ответа запросом, а не
контроллером сервера приводит к
необходимости установления отношения
зависимости классов запросов от
классов ответов.
Рис.
13.3. Использование интерфейса-адаптера
и
производящего класса.
Ряд
действий в программах выполняются
модулями, существующими в единственном
экземпляре в памяти: разбиение массива
прикладных данных на фреймы, передаваемые
по линии связи, и обратное преобразование;
вычисление контрольной суммы; запись
сообщений в log-файл. На программном
уровне это достигается использованием
статического класса/функции, или
создания экземпляра и доступ к нему
через метод getInstance(). На уровне
проектирования «единственный экземпляр
объекта в памяти» определяется как
шаблон Singleton.
Как упоминалось выше,
в большинстве протоколов взаимодействие
клиента и сервера осуществляется
посредством обмена сообщениями. Каждый
протокол определяет набор типов
сообщений и их структуру: заголовок,
область данных и т.п. С точки зрения
проектирования, каждый тип сообщения
можно представить в виде класса,
отношение наследования. Поскольку
набор методов, которые требуется
реализовать в каждом классе, неизменен
(например, конструктор и метод записи
атрибутов класса в поток байт,
традиционно называемый Serialize()), то
получаемая иерархия классов –
гомоморфная. Преимущества этого –
возможность всегда оперировать
указателем на абстрактный базовый
класс в уверенности, что никакой
производный класс не содержит
дополнительных операций и не придется
выполнять динамическое приведение
или определение типа, и т.о. добиться
универсализации работы с сообщениями
любых типов в программе. Также при
создании иерархии классов сообщений
полезно применить метод создания их
экземпляров с использованием статической
производящей функции (factory function, см.
Дж. Элджер «С++: библиотека программиста»).
Это также применение шаблона
проектирования Factory, позволяющее
сокрыть и от клиента, и от сервера все
производные от базовых классы сообщений.
Производящая функция сама определяет,
сообщение какого типа следует создать
(опираясь на переданные параметры) и
возвращает указатель на базовый класс
сообщения.
Ориентация клиента и
сервера на использование сообщений
определенного набора типов, каждый
из которых определяет некоторое
действие, которое требуется выполнить,
также позволяет использовать шаблоны
Command и CommandProcessor. Каждое сообщение
является командой, а объекты-контроллеры
клиента и сервера являются процессорами
этих команд, самостоятельно реализующие
логику работы с БД на основе этих
команд (см. рис. 13.4а). Противоположностью
разделения команд и их обработчика
была бы инкапсуляция механизма работы
с базой данных в классы сообщений.
Тогда помимо общего метода Serialize(), в
каждом запросе требовалось бы
реализовать некоторый метод Run(). Однако
такой подход обладает рядом недостатков
(см. рис. 13.4б). Во-первых, становится
невозможной взаимно независимая,
использующая только общий набор
классов сообщений, разработка,
компиляция и связывание клиента и
сервера. Во-вторых, если выполнение
самим запросом действий на сервере
достаточно легко реализуемо, то
«самоформирование» запроса на клиенте
весьма затруднительно. В-третьих,
создание ответа запросом, а не
контроллером сервера приводит к
необходимости установления отношения
зависимости классов запросов от
классов ответов.
 Рис.
13.4. Два варианта отношений между
классами
клиент-серверного
приложения.
Рис.
13.4. Два варианта отношений между
классами
клиент-серверного
приложения. Рис.
13.5. Организация области хранения
данных сервера.
Рис.
13.5. Организация области хранения
данных сервера.1 ... 6 7 8 9 10 11 12 13 14
хорошо
1