

Алгоритмы C++
.pdfcout << ", " << *i;
}
}
cout << " ]\n";
}
}

Поиск компонент сильной связности, построение конденсации графа
Определения, постановка задачи
Дан ориентированный граф , множество вершин которого и множество рёбер — . Петли и кратные рёбра допускаются. Обозначим через  количество вершин графа, через
количество вершин графа, через 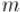 — количество рёбер.
— количество рёбер.
Компонентой сильной связности (strongly connected component) называется такое (максимальное по включению) подмножество вершин , что любые две вершины этого подмножества достижимы друг из друга, т.е. для  :
:
где символом  здесь и далее мы будем обозначать достижимость, т.е. существование пути из первой вершины во вторую.
здесь и далее мы будем обозначать достижимость, т.е. существование пути из первой вершины во вторую.
Понятно, что компоненты сильной связности для данного графа не пересекаются, т.е. фактически это разбиение
всех вершин графа. Отсюда логично определение конденсации |
как графа, получаемого из данного |
|
||||||
графа сжатием каждой компоненты сильной связности в одну вершину. Каждой вершине графа конденсации |
|
|||||||
соответствует компонента сильной связности графа |
, а ориентированное ребро между двумя вершинами |
и |
||||||
графа конденсации проводится, если найдётся пара вершин |
|
, между которыми существовало |
||||||
ребро в исходном графе, т.е. |
. |
|
|
|
|
|
||
Важнейшим свойством графа конденсации является то, что он ацикличен. Действительно, предположим, |
|
|||||||
что |
, докажем, что |
. Из определения конденсации получаем, что найдутся две вершины |
|
|||||
и |
, что |
. Доказывать будем от противного, т.е. предположим, что |
, тогда найдутся две |
|||||
вершины |
и |
, что |
. Но т.к. |
и |
находятся в одной компоненте сильной связности, то |
|||
между ними есть путь; аналогично для  и . В итоге, объединяя пути, получаем, что
и . В итоге, объединяя пути, получаем, что  , и одновременно
, и одновременно
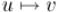 . Следовательно,
. Следовательно,  и
и 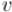 должны принадлежать одной компоненте сильной связности, т.е. получили противоречие, что и требовалось доказать.
должны принадлежать одной компоненте сильной связности, т.е. получили противоречие, что и требовалось доказать.
Описываемый ниже алгоритм выделяет в данном графе все компоненты сильной связности. Построить по ним граф конденсации не составит труда.
Алгоритм
Описываемый здесь алгоритм был предложен независимо Косараю (Kosaraju) и Шариром (Sharir) в 1979 г. Это очень простой в реализации алгоритм, основанный на двух сериях поисков в глубину, и потому работающий за
время 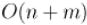 .
.
На первом шаге алгоритма выполняется серия обходов в глубину, посещающая весь граф. Для этого мы проходимся по всем вершинам графа и из каждой ещё не посещённой вершины вызываем обход в глубину. При этом для каждой вершины 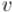 запомним время выхода . Эти времена выхода играют ключевую роль в алгоритме,
запомним время выхода . Эти времена выхода играют ключевую роль в алгоритме,
и эта роль выражена в приведённой ниже теореме.
Сначала введём обозначение: время выхода |
из компоненты |
сильной связности определим как максимум |
|||||||||
из значений |
для всех |
. Кроме того, в доказательстве теоремы будут упоминаться и времена входа |
|||||||||
в каждую вершину |
|
, и аналогично определим времена входа |
|
для каждой компоненты сильной связности |
|||||||
как минимум из величин |
|
для всех |
|
. |
|
|
|
|
|
|
|
Теорема. Пусть |
и |
— две различные компоненты сильной связности, и пусть в графе конденсации между |
|||||||||
ними есть ребро |
|
. Тогда |
|
. |
|
|
|
|
|
|
|
При доказательстве возникает два принципиально различных случая в зависимости от того, в какую из компонент |
|||||||||||
первой зайдёт обход в глубину, т.е. в зависимости от соотношения между |
|
|
и |
|
: |
|
|||||
● Первой была достигнута компонента |
. Это означает, что в какой-то момент времени обход в глубину заходит |
||||||||||
в некоторую вершину |
компоненты , при этом все остальные вершины компонент |
и |
ещё не посещены. Но, т. |
||||||||
к. по условию в графе конденсаций есть ребро |
, то из вершины |
|
будет достижима не только вся компонента |
||||||||
, но и вся компонента |
. Это означает, что при запуске из вершины |
|
обход в глубину пройдёт по всем |
||||||||
вершинам компонент |
и |
, а, значит, они станут потомками по отношению к |
в дереве обхода в глубину, т.е. |
||||||||
для любой вершины |
|
|
будет выполнено |
|
|
|
, ч.т.д. |
|
|||
● Первой была достигнута компонента |
. Опять же, в какой-то момент времени обход в глубину заходит в |
||||||||||
некоторую вершину |
|
, причём все остальные вершины компонент |
и |
не посещены. Поскольку по условию |
|||||||
в графе конденсаций существовало ребро |
, то, вследствие ацикличности графа конденсаций, не |
||||||||||
существует обратного пути |
|
, т.е. обход в глубину из вершины |
|
не достигнет вершин . Это означает, что |
|||||||
они будут посещены обходом в глубину позже, откуда и следует |
|
|
|
|
, ч.т.д. |
||||||
Доказанная теорема является основой алгоритма поиска компонент сильной связности. Из неё следует, что любое ребро в графе конденсаций идёт из компоненты с большей величиной  в компоненту с меньшей величиной.
в компоненту с меньшей величиной.

Если мы отсортируем все вершины |
в порядке убывания времени выхода |
, то первой окажется |
некоторая вершина 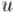 , принадлежащая "корневой" компоненте сильной связности, т.е. в которую не входит ни одно ребро в графе конденсаций. Теперь нам хотелось бы запустить такой обход из этой вершины
, принадлежащая "корневой" компоненте сильной связности, т.е. в которую не входит ни одно ребро в графе конденсаций. Теперь нам хотелось бы запустить такой обход из этой вершины  , который бы посетил только эту компоненту сильной связности и не зашёл ни в какую другую; научившись это делать, мы сможем постепенно выделить все компоненты сильной связности: удалив из графа вершины первой
, который бы посетил только эту компоненту сильной связности и не зашёл ни в какую другую; научившись это делать, мы сможем постепенно выделить все компоненты сильной связности: удалив из графа вершины первой
выделенной компоненты, мы снова найдём среди оставшихся вершину с наибольшей величиной 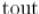 , снова запустим из неё этот обход, и т.д.
, снова запустим из неё этот обход, и т.д.
Чтобы научиться делать такой обход, рассмотрим транспонированный граф |
, т.е. граф, полученный из |
||
изменением направления каждого ребра на противоположное. Нетрудно понять, что в этом графе будут те |
|||
же компоненты сильной связности, что и в исходном графе. Более того, граф конденсации |
для него |
||
будет равен транспонированному графу конденсации исходного графа |
. Это означает, что теперь |
||
из рассматриваемой нами "корневой" компоненты уже не будут выходить рёбра в другие компоненты.
Таким образом, чтобы обойти всю "корневую" компоненту сильной связности, содержащую некоторую вершину
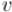 , достаточно запустить обход из вершины
, достаточно запустить обход из вершины 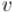 в графе . Этот обход посетит все вершины этой компоненты сильной связности и только их. Как уже говорилось, дальше мы можем мысленно удалить эти вершины из графа,
в графе . Этот обход посетит все вершины этой компоненты сильной связности и только их. Как уже говорилось, дальше мы можем мысленно удалить эти вершины из графа,
находить очередную вершину с максимальным значением |
и запускать обход на транспонированном графе |
из неё, и т.д. |
|
Итак, мы построили следующий алгоритм выделения компонент сильной связности:
1 шаг. Запустить серию обходов в глубину графа , которая возвращает вершины в порядке увеличения времени выхода 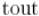 , т.е. некоторый список
, т.е. некоторый список 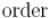 .
.
2 шаг. Построить транспонированный граф |
. Запустить серию обходов в глубину/ширину этого графа в |
||
порядке, определяемом списком |
(а именно, в обратном порядке, т.е. в порядке уменьшения времени |
||
выхода). Каждое множество вершин, достигнутое в результате очередного запуска обхода, и будет очередной |
|||
компонентой сильной связности. |
|
|
|
Асимптотика алгоритма, очевидно, равна |
, поскольку он представляет собой всего лишь два обхода |
||
в глубину/ширину. |
|
|
|
Наконец, уместно отметить связь с понятием топологической сортировки. Во-первых, шаг 1 |
|||
алгоритма представляет собой не что иное, как топологическую сортировку графа |
(фактически именно это и |
||
означает сортировка вершин по времени выхода). Во-вторых, сама схема алгоритма такова, что и компоненты сильной связности он генерирует в порядке уменьшения их времён выхода, таким образом, он генерирует компоненты - вершины графа конденсации в порядке топологической сортировки.
Реализация

vector < vector<int> > g, gr; vector<char> used; vector<int> order, component;
void dfs1 (int v) { used[v] = true;
for (size_t i=0; i<g[v].size(); ++i) if (!used[ g[v][i] ])
dfs1 (g[v][i]); order.push_back (v);
}
void dfs2 (int v) { used[v] = true;
component.push_back (v);
for (size_t i=0; i<gr[v].size(); ++i) if (!used[ gr[v][i] ])
dfs2 (gr[v][i]);
}
int main() { int n;
... чтение n ...
for (;;) {
int a, b;
... чтение очередного ребра (a,b) ...
g[a].push_back (b); gr[b].push_back (a);
}
used.assign (n, false); for (int i=0; i<n; ++i)
if (!used[i]) dfs1 (i);
used.assign (n, false); for (int i=0; i<n; ++i) {
int v = order[n-1-i];

if (!used[v]) { dfs2 (v);
... вывод очередной component ...
component.clear();
}
}
}
Здесь в хранится сам граф, а |
— транспонированный граф. Функция |
выполняет обход в глубину на графе |
|||||
, функция |
— на транспонированном |
. Функция |
заполняет список |
вершинами в |
|||
порядке увеличения времени выхода (фактически, делает топологическую сортировку). Функция |
сохраняет |
||||||
все достигнутые вершины в списке |
|
, который после каждого запуска будет содержать |
|
||||
очередную компоненту сильной связности. |
|
|
|
|
|
||
Литература
●Томас Кормен, Чарльз Лейзерсон, Рональд Ривест, Клиффорд Штайн. Алгоритмы: Построение и анализ [2005]
●M. Sharir. A strong-connectivity algorithm and its applications in data-flow analysis [1979]

Поиск мостов
Пусть дан связный неориентированный граф. Мостом называется такое ребро, удаление которого делаем граф несвязным.
Опишем алгоритм, основанный на поиске в глубину, работающий за |
, где — количество вершин, |
— рёбер. |
|
Алгоритм
Запустим обход в глубину из произвольной вершины графа; обозначим её через root. Заметим следующий факт (который несложно доказать).
Если текущее ребро таково, что ведёт в вершину, из которой и из любого её потомка нет обратного ребра в текущую вершину или её предка, то это ребро является мостом. В противном случае оно мостом не является.
Теперь осталось научиться для каждой вершины эффективно проверять, не найдётся ли из её потомка обратное ребро в текущую вершину или её предка. Для этого воспользуемся временами входа поиска в глубину.
Итак, пусть |
— это время захода поиска в глубину в вершину |
. Теперь введём массив |
, который |
|
и позволит нам отвечать на вышеописанные запросы. Время |
равно минимуму из времени захода в саму |
|||
вершину |
, времён захода в каждую вершину , являющуюся концом некоторого обратного ребра |
, а также |
||
из всех значений  для каждой вершины
для каждой вершины  , являющейся непосредственным сыном
, являющейся непосредственным сыном 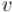 в дереве поиска:
в дереве поиска:
(здесь "back edge" — обратное ребро, "tree edge" — ребро дерева)
Тогда, из вершины  или её потомка есть обратное ребро в её предка тогда и только тогда, когда найдётся такой сын
или её потомка есть обратное ребро в её предка тогда и только тогда, когда найдётся такой сын
, что |
. Если |
, то это означает, что найдётся обратное ребро, приходящее |
|
точно в . |
|
|
|
Таким образом, если для текущего ребра |
(принадлежащего дереву поиска) выполняется |
, |
|
то это ребро является мостом; в противном случае оно мостом не является. |
|
||

Реализация
Здесь |
— это некая функция, которая будет реагировать на то, что ребро |
является |
мостом, например, выводить это ребро на экран. |
|
|
Если говорить о самой реализации, то здесь нам нужно уметь различать три случая: когда мы идём по ребру дерева поиска в глубину, когда идём по обратному ребру, и когда пытаемся пойти по ребру дерева в обратную сторону. Это, соответственно, случаи , ,
и 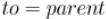 . Таким образом, нам надо передавать в функцию поиска в глубину вершину-предка текущей вершины.
. Таким образом, нам надо передавать в функцию поиска в глубину вершину-предка текущей вершины.
Стоит заметить, что эта реализация некорректно работает при наличии в графе кратных рёбер: она фактически не обращает внимания, кратное ли ребро или оно единственно. Разумеется, кратные рёбра не должны входить в
ответ, поэтому при вызове |
можно проверять дополнительно, не кратное ли ребро мы хотим добавить |
|
в ответ. Другой способ — более аккуратная работа с предками, т.е. передавать в |
не вершину-предка, а номер |
|
ребра, по которому мы вошли в вершину (для этого надо будет дополнительно хранить номера всех рёбер).
vector < vector<int> > g; vector<char> used;
int timer; vector<int> tin, fup;
void dfs (int v, int p = -1) { used[v] = true;
tin[v] = fup[v] = timer++;
for (size_t i=0; i<g[v].size(); ++i) { int to = g[v][i];
if (to == p) continue; if (used[to])
fup[v] = min (fup[v], tin[to]); else {
dfs (to, v);
fup[v] = min (fup[v], fup[to]); if (fup[to] > tin[v])
IS_BRIDGE(v,to);
}
}
}

int main() { int n;
... чтение n и g ...
timer = 0; used.assign (n, false); tin.resize (n); fup.resize (n);
dfs (0);
}

Точки сочленения
Пусть дан связный неориентированный граф. Точкой сочленения называется такая вершина графа, удаление которой делает граф несвязным. Граф, не имеющий точек сочленения, называется двусвязным.
Опишем алгоритм, основанный на поиске в глубину, позволяющий найти все точки сочленения в графе за время O (N+M).
Алгоритм
Запустим обход в глубину из произвольной вершины графа; обозначим её через root. Заметим два следующих факта (которые несложно доказать):
●Пусть v - вершина графа, v≠root. Тогда, если найдётся такой потомок t вершины v в дереве поиска, что ни из него, ни из какого-либо его потомка нет ребра (обратного) в предка вершины v, то вершина v будет являться точкой сочленения. В противном случае, вершина v не является точкой сочленения.
●Рассмотрим теперь корень root дерева поиска. Тогда он является точкой сочленения тогда и только тогда, когда он имеет как минимум двух потомков в дереве поиска.
Теперь осталось научиться для каждой вершины эффективно проверять, не найдётся ли из её потомка обратное ребро в предка текущей вершины. Для этого воспользуемся временами входа поиска в глубину.
Итак, пусть tin[v] - это время захода поиска в глубину в вершину v. Теперь введём массив fup[v], который и позволит нам отвечать на вышеописанные запросы. Время fup[v] равно минимуму из времени захода в саму вершину tin[v], времён захода в каждую из вершину p, являющуюся концом некоторого обратного ребра (v,p), а также из всех значений fup[to] для каждой вершины to, являющейся непосредственным сыном v в дереве поиска:
fup[v] = min { tin[v],
tin[p], где (v,p) - обратное ребро, fup[to], где (v,to) - ребро дерева
}
Тогда, из вершины v или её потомка есть обратное ребро в её предка тогда и только тогда, когда найдётся такой сын to, что fup[to] < tin[v].
Таким образом, если для текущей вершины v≠root найдётся такой непосредственный сын to, что fup[to] >= tin[v],