

Inf_comp_sys
.pdf9.4Границы анализа
В небольшом или довольно цельном предприятии анализ должен охватить всю организацию. В организации, состоящей из множества объединений, он может охватывать объединения поочередно.
Если объем планирования сверху вниз слишком велик и охватывает отдельные филиалы организации, то может оказаться затруднительным осуществление контроля и получение результатов вовремя, для осуществления разработки базы данных. С другой стороны, если объем слишком мал, преимущества планирования сверху вниз будут частично потеряны. Если информационные ресурсы влекут за собой сложное взаимодействие нескольких подразделений, исследование сверху вниз, ограничившееся только одним из подразделений, может не дать адекватного основания для построения требуемых информационных систем.
Широта стратегического планирования должна отражать стиль руководства корпорации. В некоторых корпорациях подразделения действительно разделены и автономны, в других - нет. Управление одинаковыми по размеру фирмами в одной и той же области промышленности часто строится совершенно по-разному.
Для решения проблемы границ планирования сверху вниз следует получить ответ на вопрос: могут ли структуры данных, проектируемые для исследуемой области, использоваться в другой области или зависеть от нее? Если ответ положительный, то эта другая область должна быть охвачена планом. В ином случае границы плана не следует делать излишне широкими.
9.5Определение процессов
Для определения процессов каждая функциональная область предприятия рассматривается отдельно. Результаты такого анализа составляют три первых уровня в схеме предприятия (рис. 6).
Идентификацию процессов лучше поручать представителям каждой функциональной области. Чтобы показать им, что требуется сделать, можно нарисовать предполагаемый ряд процессов. Такой предварительный список затем обсуждается и уточняется представителями функциональных областей,
пока не будет определен согласованный набор процессов.
Согласованный набор процессов группируют в таком виде, как представлено на рис. 6, но пока без действий. Иногда на такой схеме выявляются расхождения и противоречия. Такие функциональные расхождения разрешают на совместной встрече представителей соответствующий областей. Затем вся схема может быть представлена на рассмотрение высшему руководству.
9.6Степень разрешения
При укрупненном (с низкой степенью разрешения) планировании рассматриваются функциональные области и процессы, но не действия. При этом проектирование снизу вверх ведется на уровне предметных баз данных.
81
При детализированном (с высокой степенью разрешения) планировании рассматриваются процессы разбиваются на более мелкие функции и действия. При этом проектирование снизу вверх ведется на уровне объектов.
Более детализированное планирование служит гораздо лучшим руководством для проектирование и внедрения баз данных.
Важно, чтобы планирование сверху вниз оставалось обзорным, выполнялось довольно быстро и не задерживалось на деталях определения атрибутов данных и моделирования. Детальное моделирование данных является важным процессом, но оно осуществляется позже и обычно по частям.
9.7Определение объектов и действий
Определение объектов, данные о которых должны храниться, а возможно также и действий, с которыми ассоциируется данный объект, выполняется с участием отделов и групп, выполняющих каждый из процессов.
Хороший способ организовать такую работу - научить заинтересованных конечных пользователей в разных областях предприятия идентифицировать действия и объекты. Вместе с пользователями над определением действий могут продолжать работать аналитики, определявшие процессы на предыдущем этапе.
Затем группа-ядро планирования составляет более подробную модель
(рис.6).
По мере составления модели предприятия (рис. 6), часть ее, относящуюся к каждой функциональной области, можно для проверки отдавать в эту область.
9.8Филиалы корпорации
Некоторые подразделения имеют множество филиалов. Если это неоднородные предприятия, они могут иметь совершенно различную структуру. Если это отделения (например иностранные филиалы), они могут быть аналогичны по структуре. Желательно, когда это практически осуществимо,
чтобы базы данных филиалов были хотя бы частично совместимы с базами данных в основной корпорации. Это существенно облегчает репликацию данных и формирование сводной отчетности.
Когда методология стратегического планирования применяется впервые, она обычно осуществляется сначала в одной корпорации, подразделении или предприятии. Группа, реализующая эта методологию, должна познакомиться с ней, приобрести опыт, а затем ее легко распространить на другие части организации, что должно проводиться с указания высшего руководства. Иногда филиалы или предприятия крупной корпорации могут воспользоваться теми же типами предметных баз данных, охватывающими аналогичные объекты.
9.9Анализ
На каждом шаге централизованного планирования сверху вниз необходим критический анализ со стороны участников и руководителей различных функциональных областей с изложением мнений и замечаний.
82
Каждый должен анализировать все функциональные области схемы, а
затем заниматься разработкой деталей в тех областях, с которыми он знаком.
Один человек не может разбираться во всех деталях каждой функциональной области.
Этот предварительный процесс анализа схемы и ее усовершенствования является критическим. Схему не следует "замораживать" преждевременно. Она должна быть достаточно точной, чтобы ею можно было руководствоваться в процессе детального проектирования системы и базы данных. Вполне вероятно, что она будет уточняться неоднократно и по этому для ее ведения необходимы соответствующие программные и вычислительные средства.
83
Глава 10. Предметные базы данных
10.1Местоположение предметных баз данных
История развития баз данных указывает на два разных идеологических подхода к их проектированию, результатом которых являются прикладные и предметные базы данных.
Предметные базы данных соотносятся с предметами организации (объектами, о которых необходимо хранить данные), а не с приложениями, автоматизирующими деятельность отдельных исполнителей. Например, возможно создание базы данных продукта, а возможно создание баз данных инвентарного учета, поступления заказов и контроля качества, которые относятся к информационному обеспечению соответствующих процессов, сопровождающих жизненные циклы этого продукта.
Обработку данных в целом можно рассматривать как последовательность изменений, производимых с данными. Мгновенный снимок системы или организации покажет только структуру данных. Процесс обработки технически заключается в последовательности изменений данных, включая данные, находящиеся в рабочей памяти, а также входные и выходные данные.
Прикладные базы данных содержат избыточные данные, что затрудняет их ведение и контроль целостности. Проектирование стабильной, хорошо документированной и в основном не избыточной структуры предметной базы данных в конечном счете обеспечивает более простую и ясную форму обработки данных, чем вложение отдельно проектируемых прикладных баз данных в сотни процессов.
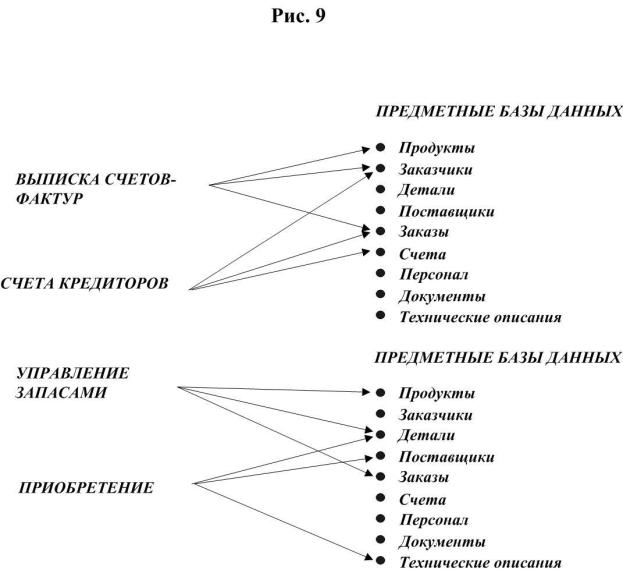
Одной из задач планирования сверху вниз должно быть определение требуемых предметных баз данных. Типичными предметами, для которых строятся базы данных, являются: продукты, заказчики, детали, поставщики, заказы, счета, персонал, документы, технические описания.
Некоторые приложения могут использовать не одну, а несколько предметных баз данных. Так, например, выписка счетов-фактур связана с использованием данных о продуктах, заказчиках и заказах (рис 9).
10.2Преимущества предметных баз данных
Целью проектирования предметной базы данных является ускорение разработки приложений. Данные, которыми пользуются программисты, должны уже существовать в предметных базах данных.
Наличие готовых данных позволяет быстро создавать новые приложения и отчеты с помощью программных средств, называемых генераторами приложений и отчетов, даже если для их (новых приложений и отчетов) реализации требуется добавление новых полей атрибутов к уже существующим данным об объектах (предметах) предприятия.
Планирование сверху вниз должно разбить всю громаду данных предприятия на управляемые единицы - предметные базы данных. Тогда одна или несколько предметных баз данных могут быть взяты под контроль одним из руководителей.
84
Предметные базы данных следует проектировать так, чтобы они были как можно стабильнее. Это означает, что большинство изменений в них будет носить такой характер, что их можно осуществлять без вынужденного переписывания уже работающих приложений.
Логические структуры, создаваемые в результате такого процесса , не зависят от их физической реализации на современных аппаратных средствах и от программного обеспечения. В то время, как технология будет меняться, логические структуры предметных баз данных останутся жизнеспособными.
Разработкой приложений в этом случае как бы движет база данных, а не потребность в обычном системном анализе.
10.3Выбор предметных баз данных
Предметные базы данных представляют собой классы данных.
Для выявления предметных баз данных планирующая группа должна рассматривать их с двух точек зрения и проводить перекрестную проверку результатов.
85
Содной стороны для каждого из элементов списка предметов (объектов) с которыми корпорация имеет дело составляется список процессов, в которых они принимают участие.
Сдругой стороны берется список процессов (рис. 3) и, для каждого процесса, записываются входные и выходные классы данных.
Список классов данных сверяют со списком предметов и получают объединенную группировку классов данных, используемую для выбора и определения предметных баз данных.
При централизованном планировании следует учитывать не только вновь проектируемые предметные базы данных, но и уже существующие, а так же новые файлы и автономные базы данных, предназначенные для определенных приложений. Это является частью планирования сверху вниз или стратегического планирования.
86
Глава 11. Планирование распределения данных
По мере уменьшения стоимости вычислительных машин и запоминающих устройств все более распространенной становится распределенная обработка данных, а с ней - и распределение данных.
Когда данные хранятся во многих местах, необходимость в планировании и контроле сверху вниз еще большая, чем при наличии централизованных систем баз данных. При отсутствии централизованного планирования сверху вниз возрастает вероятность того, что каждый системный аналитик или каждая группа пользователей будут создавать свой собственный проект данных.
У распределенной обработки данных есть как преимущества, так и недостатки, которые могут быть различными для каждого конкретного случая.
Во многих системах имеются данные обоих типов: естественно централизованные и естественно распределенные. Большая часть информации, находящейся в филиале конторы, например адреса клиентов, не нужна нигде, кроме этого филиала. Другая же информация, получаемая в этом филиале, требуется централизованным информационно-поисковым или управляющим системам, таким, как снабжение или производственное управление.
11.1Основания для централизации данных
Данные используются централизованными приложениями, такими, как расчет заработной платы в корпорации, снабжение или общий учет.
Пользователям во всех областях требуется доступ к одним и тем же данным и притом к их текущей (на последнюю минуту) версии. Эти данные часто обновляются. Во избежании затруднений, связанных с синхронизацией в реальном времени многочисленных копий, имеющих высокий уровень обновления, данные можно хранить централизованно.
Пользователи определенных данных перемещаются с места на место, и дешевле централизовать эти данные, чем создавать мобильную распределенную систему обработки данных.
Данные будут искать как одно целое. Они составляют часть информационно-поисковой системы, дающей ответы на спонтанные запросы пользователей, на многие из которых можно ответить, только исследовав множество записей. Поиск данных, которые географически разбросаны, занимает чрезвычайно много времени. Чтобы программное и аппаратное обеспечение гарантировали эффективные поиск, надо, чтобы данные находились в одном месте.
Структуры данных проектируются таким образом, чтобы служить множеству приложений и использоваться с программным обеспечением баз данных, гарантирую получение преимуществ, предоставляемых СУБД.
Данные должны быть хорошо защищены. Процедуры защиты могут быть дорогостоящими, требующими, вероятно, тщательно охраняемого, надежного хранилища и жесткого контроля над уполномоченными пользователями. Данные легче охранять, если они находятся в одном месте, а не разбросаны (причем резервные копии будут находится в другом месте, вне этой системы).
87
Данные слишком массивны для того, чтобы их размещать на недорогих внешних устройствах памяти. Экономичнее хранить их в емкой централизованной памяти.
Для осуществление контроля за системами иногда сохраняют такие подробные сведения, как, например, какие транзакции обновляли определенные данные. Иногда дешевле и надежнее размещать их на большом централизованном устройстве архивной памяти.
11.2Основания для распределения данных
Данные используются на одном периферийном участке и редко или никогда не используются на других участках. Передача таких данных может быть неоправданно сложной и дорогой.
Точность, секретность и надежность данных являются предметом местной заботы.
Файлы являются простыми и используются одним или несколькими приложениями. Следовательно применение баз данных не даст никаких преимуществ.
Частота обновления слишком высока для единой централизованной системы хранения данных.
Поиск и манипулирование с периферийными файлами осуществляется на языке запросов, составляемых конечными пользователями. Такие запросы могут быть составлены не корректно и приведут к неоправданно большой загрузке централизованной системы обработки данных. Такие данные лучше размещать в периферийной системе, где конечные пользователи будут отвечать за их использование.
11.3Проблемы, связанные с распределенными данными
11.3.1 Помехи между двумя обновляющими транзакциями
Две транзакции могут обновлять один и тот же элемент данных на удаленном (дистанционном) устройстве памяти и мешать друг другу, давая неточные данные. Воспрепятствовать этому могут соответствующие механизмы блокировок и протоколы, заложенные в программное обеспечение операционных систем и систем управления распределенными базами данных (СУРБД).
11.3.2 Противоречие считывания
Когда имеется более чем одна копия данных, а иногда и одна копия распределенных данных, при чтении данных можно получить противоречивую информацию. Считанные данные могут быть недействительными в связи с проблемами синхронизации. Это так же можно предотвратить с помощью соответствующих программных средств репликации данных.
88
11.3.3 «Мертвые объятия»
Блокировка распределенных данных с целью предотвращения помех в связи с обновлением может привести к тупиковым ситуациям, если не будут использованы соответствующие (довольно сложные) протоколы.
11.3.4 Протокольные перегрузки
Могут возникать чрезмерные перегрузки, особенно при использовании многократных копий, связанные с протоколами, предотвращающими недействительные обновления, противоречивые считывания и ситуации с «мертвыми объятиями», если эти протоколы не будут тщательно продуманы.
11.3.5 Восстановление
Следует контролировать восстановление после отказа, чтобы обновления не были случайно потеряны или не обрабатывались дважды.
11.3.6 Восстановление многократных копий
После отказа множество копий данных могут находиться в разных состояниях. Их нужно свести снова к одному и тому же состоянию - но это бывает сложно осуществить во время обработки транзакций в реальном времени.
11.3.7 Различное представление данных
Из-за отсутствия администрирования данных или строгого контроля со стороны руководства одни и те же данные в разных местах представлены поразному.
11.3.8 Ревизия данных
В некоторых распределенных системах трудно выявить, кто что сделал с данными. Для проведения ревизии требуется соответствующий проект.
11.3.9 Защита и обеспечение секретности
В распределенных системах контроль защиты и обеспечения секретности иногда бывает слабый и его нужно включать в базовый проект.
11.4Шесть форм распределенных данных
Распределенные данные могут существовать в шести различных формах:
копируемые данные;
подмножество данных;
реорганизованные данные;
секционированные данные;
данные с отдельной схемой;
несовместимые данные.
89
11.4.1 Копируемые данные
Копирование данных связано с хранением идентичных копий в различных местах.
Основной причиной для копирования служит тот факт, что при дублируемом хранении отпадает необходимость передачи данных между системами и что первое дешевле второго.
Такая организация оправдана только в том случае, если частота обращений к данным гораздо меньше частоты обновлений.
Копируемые данные в большинстве своем являются неизменяемыми (или редко изменяемыми, потому что нет полностью статичных данных).
11.4.2 Подмножество данных
На периферийных компьютерах хранятся данные, являющиеся подмножеством данных, которые находятся на центральном компьютере. Это делается по двум основным причинам. Первая: данные используются часто на этом периферийном участке. Вторая: данные создаются на этом участке.
Подмножество данных представляет собой один из видов копируемых данных. Такие данные обычно не имеют полной схемы или полного набора ключей и атрибутов «родительских» данных.
После обновления подмножество данных передается с периферийного компьютера в центральный - иногда мгновенно, иногда позднее, в цикле обновления.
Кроме подмножества данных на локальной машине могут существовать другие данные, которые никогда не передаются в центральный компьютер.
11.4.3 Реорганизованные данные
В информационно-поисковых системах или системах поддержки принятия решений обычно содержится некоторая часть тех же данных, что и в рутинной производственной системе, но они реорганизованы для использования механизмов, облегчающих поиск и выборку информации.
Такие данные могут быть отобраны из баз данных и файлов, размещенных в других машинах (или на той же самой машине), сгруппированы,
просуммированы, отредактированы и реорганизованы. Для успешного выполнения такой работы оба типа баз данных должны иметь одинаковое представление полей; они должны выводиться на основании одной и той же модели данных и словарного представления.
11.4.4 Секционированные данные
Секционирование данных подразумевает, что одна и та же схема применяется в двух или более машинах, но в каждой машине хранятся различные данные. В каждой машине размешены разные записи, имеющие одинаковую структуру.
90