

grishagin_v_a_svistunov_a_n_parallelnoe_programmirovanie_na
.pdf61
время выполнения
80
70
60
50
2 процессора
40

 4 процессора
4 процессора
30
20
10
0 








 1000 5000 10000 20000 50000 100000
1000 5000 10000 20000 50000 100000
длина массива данных
Рис. 6. Зависимость времени выполнения от размера массива
|
12 |
|
|
|
10 |
|
|
ускорение |
8 |
|
|
6 |
|
|
|
|
|
|
|
|
4 |
|
|
|
2 |
|
|
|
0 |
|
|
|
1000 |
5000 |
10000 20000 50000 1E+05 |
|
|
длина массива данных |
|
 2 процессора
2 процессора 
 4 процессора
4 процессора
Рис. 7. Зависимость ускорения от размера массива
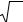
62
7.2. Умножение матриц. Параллельный алгоритм Фокса
7.2.1.Постановка задачи
Заданы две матрицы A = ||aij||n×m и B = ||bjk||m×k. Получить матрицу C = ||cik||n×k, которая является результатом перемножения матриц A и B, используя параллельный алгоритм Фокса.
7.2.2. Параллельная реализация алгоритма
При построении параллельных способов выполнения матричного умножения широко используется блочное представление матриц.
Пусть количество процессоров составляет p = k 2 , а количество строк
и столбцов |
матрицы является |
кратным |
величине |
k = |
p , т.е. |
|||||||||||||||
n = mk . Представим исходные матрицы |
A , B и результирующую |
|||||||||||||||||||
матрицу |
C в виде наборов прямоугольных блоков размера |
m ×m . |
||||||||||||||||||
Тогда операцию матричного умножения матриц |
A и |
B в блочном |
||||||||||||||||||
виде можно представить следующим образом: |
|
|
|
|
|
|
||||||||||||||
|
A A ...A |
|
B B ...B |
|
C C ...C |
|
|
|
||||||||||||
|
11 |
12 |
1k |
|
|
11 |
|
12 |
|
1k |
|
11 |
12 |
|
1k |
|
|
|||
|
|
L |
× |
|
L |
= |
|
|
L |
|
|
, |
|
|||||||
|
A |
A |
...A |
|
B |
k1 |
B |
k 2 |
...B |
|
c |
k1 |
C |
k 2 |
...C |
kk |
|
|
||
|
k1 |
k 2 |
kk |
|
|
|
|
kk |
|
|
|
|
|
|
||||||
где каждый блок Cij |
матрицы C определяется в соответствии с |
|||||||||||||||||||
выражением
Cij = ∑k Ail Blj . l =1
При анализе данного выражения можно обратить внимание на взаимную независимость вычислений блоков Cij матрицы C . Как
результат, возможный подход для параллельного выполнения вычислений может состоять в выделении для расчетов, связанных с
получением отдельных блоков Cij , разных процессоров. Применение подобного подхода позволяет получить многие эффективные
63
параллельные методы умножения блочно-представленных матриц;
один из алгоритмов данного класса рассматривается ниже.
Для организации параллельных вычислений предположим, что процессоры образуют логическую прямоугольную решетку размером
k ×k (обозначим через pij процессор, располагаемый на
пересечении i строки и j столбца решетки). Основные положения
параллельного метода, известного как алгоритм Фокса (Fox) [1], состоят в следующем:
•каждый из процессоров решетки отвечает за вычисление одного блока матрицы C ;
•в ходе вычислений на каждом из процессоров pij
располагается четыре матричных блока:
-блок Cij матрицы C , вычисляемый процессором;
-блок Aij матрицы A , размещенный в процессоре перед началом вычислений;
-блоки Aij′ , Bij′ матриц A и B , получаемые процессором в ходе выполнения вычислений;
Выполнение параллельного метода включает:
• этап инициализации, на котором на каждый
процессор |
pij передаются блоки Aij , Bij |
и обнуляются |
||||
блоки Cij |
на всех процессорах; |
|
|
|
|
|
•этап |
вычислений, |
на |
каждой |
итерации |
||
l, 1 ≤ l ≤ k , которого выполняется: |
|
|
|
|||
- для |
каждой |
строки i, |
1 ≤ i ≤ k , |
процессорной |
||
решетки блок Aij |
процессора |
pij |
пересылается на все |
|||
процессоры той же строки i ; индекс j , определяющий положение процессора pij в строке, вычисляется по
соотношению
j = (i +l −1) mod k +1 ,
( mod есть операция получения остатка от целого деления);
64
- полученные в результаты пересылок блоки Aij′ , Bij′
каждого процессора pij перемножаются и прибавляются к
блоку Cij
Cij = Cij + Aij′ ×Bij′ ;
- блоки Bij′ каждого процессора pij пересылаются процессорам pij , являющимися соседями сверху в
столбцах процессорной решетки (блоки процессоров из первой строки решетки пересылаются процессорам последней строки решетки).
-
7.2.3. Время выполнения алгоритма
Рассмотрим выполнение данного алгоритма при топологии сети в виде гиперкуба. После k ( k = p ) шагов процессор Pi,j совершил перемножение Ai,l × Bl,j для каждого l от 0 до k-1. Каждый процессор совершает вычисления за время, равное n3 / p . Время для рассылки
"один-ко-всем"блоков матрицы A преобладает над временем одношагового сдвига блока матрицы B. Если логическая решетка процессоров отображается на гиперкуб, то каждая рассылка может быть совершена за время
(tн +tкn2 / p)log 
 p ,
p ,
где tн есть время начальной подготовки и характеризует длитель-
ность подготовки сообщения для передачи, tк есть время передачи
одного слова данных по линии передачи данных (длительность подобной передачи определяется полосой пропускания коммуникационных каналов в сети). Так как эта операция повторяется k раз, общее время коммуникаций составляет
(tн +tкn2 / p) p log
p log  p .
p .
Тем самым, общее время параллельного выполнения программы составляет

65
Tp = n3 |
+(tн +tкn2 / p) p log |
|
. |
p |
|||
p |
|
|
|
7.2.4. Описание программы
Схема вызова функций программы, реализующей метод Фокса, показана на рисунке 8.
|
|
|
|
|
|
|
|
|
|
main |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
InitData |
|
|
ParallelMultiplication |
|
|
|
FreeData |
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
CreateGrid |
|
|
BcastData |
|
|
|
|
MultiplyMatrix |
|
|
GatherData |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DefineType |
|
|
|
MultiplyLocalMatrix |
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 8. Схема вызовов функций
Рассмотрим процесс работы программы.
Управляющий процессор (процессор 0) выполняет:
−ввод размерности перемножаемых матриц и ввод элементов матриц (функция InitData);
−создание топологии ″решетка″ (функция CreateGrid);
−создание производного типа - ″блок матрицы″ (функция DefineType) и пересылку блоков на соответствующие
процессоры в топологии ″решетка″ (функция BcastData);
− выполнение итераций параллельного перемножения матриц (эта часть действий является общей для всех процессоров и детально описана в разделе Параллельная реализация алгоритма);
66
−сбор результатов (перемноженных блоков) от всех процессоров (функция GatherData);
−освобождение занимаемой памяти (функция
FreeData).
Функциональные процессоры выполняют:
−создание топологии "решетка" (функция CreateGrid);
−создание производного типа "блок матрицы" (функция
DefineType);
−прием от процессора 0 соответствующих блоков матриц (функция BcastData);
−выполнение итераций параллельного перемножения матриц (функция MultiplyMatrix);
−передача результата (перемноженного блока) на управляющий процессор.
7.2.5.Текст программы
Файл Fox.h
#ifndef __FOX_H #define __FOX_H
#include <mpi.h> #include <stdlib.h> #include <stdio.h> #include <math.h>
struct PROCESS { |
// данные процесса |
int ProcRank; |
// ранг процесса |
int CommSize; |
// общее количество процессов |
int *pProcMatrixA; |
// подматрица A |
int *pProcMatrixB; |
// подматрица B |
int *pProcMatrixC; |
// подматрица C |
int BlockSize; |
// длина подматрицы |
}; |
|
struct GRIDINFO { |
// параметры решетки |
int DimGrid ; |
// порядок решетки |
int NumRow; |
// номер строки |
int NumCol; |
// номер столбца |
int RankGrid; |
// ранг процесса в коммуникаторе решетки |
67
MPI_Comm CommGrid; // коммуникатор решетки MPI_Comm RowComm; // коммуникатор строки MPI_Comm ColComm; // коммуникатор столбца
};
// генерация исходных данных
void InitData ( int **pMatrixA, int **pMatrixB, int *pDataSize, PROCESS *pProcs, int *argc, char **argv[] );
// параллельное умножение матриц
void ParallelMultiplication ( int *pMatrixA, int *pMatrixB, int **pMatrixC, int DataSize, PROCESS *pProcs, GRIDINFO *Grid );
// завершение работы
void FreeData ( int *pMatrixA, int *pMatrixB, int DataSize, PROCESS *pProcs );
// установка параметров решетки
void CreateGrid ( PROCESS *pProcs, GRIDINFO *Grid );
// рассылка и прием блоков данных
void BcastData ( int *pMatrixA, int *pMatrixB, int DataSize, PROCESS *pProcs, MPI_Datatype *MatrixBlock );
// перемножение матриц
void MultiplyMatrix ( int DataSize, PROCESS *pProcs, GRIDINFO *Grid, MPI_Datatype MatrixBlock);
// сбор данных
void GatherData ( PROCESS *pProcs, GRIDINFO *Grid, int *pMatrixC, int DataSize, MPI_Datatype MatrixBlock );
// определить тип данных - блок матрицы
void DefineType ( PROCESS *pProcs, int DataSize, MPI_Datatype *MatrixBlock );
// локальное умножение матриц
void MultiplyLocalMatrix ( int *pMatrixA, int *pMatrixB, int *pMatrixC, int Size, int Stride );
#endif
Файл Fox.cpp
#include "Fox.h"
int main(int argc, char *argv[]) { PROCESS Procs;
GRIDINFO Grid;
int *pMatrixA, *pMatrixB, *pMatrixC; int DataSize;
68
// генерация исходных данных
InitData ( &pMatrixA, &pMatrixB, &DataSize, &Procs, &argc, &argv );
// параллельное умножение матриц
ParallelMultiplication ( pMatrixA, pMatrixB, &pMatrixC, DataSize, &Procs, &Grid);
// завершение работы
FreeData ( pMatrixA, pMatrixB, DataSize, &Procs );
return 0;
}
// генерация исходных данных
void InitData ( int **pMatrixA, int **pMatrixB, int *pDataSize, PROCESS *pProcs, int *argc, char **argv[] )
{
MPI_Init ( argc, argv );
MPI_Comm_rank ( MPI_COMM_WORLD, &pProcs->ProcRank
);
MPI_Comm_size ( MPI_COMM_WORLD, &pProcs->CommSize
);
if ( pProcs->ProcRank == 0 ) { sscanf((*argv)[1], "%d", pDataSize);
if ( *pDataSize % (int)sqrt(pProcs->CommSize) !=
0 )
*pDataSize += (int)sqrt(pProcs->CommSize) - ( *pDataSize % (int)sqrt(pProcs->CommSize) );
*pMatrixA = new int[(*pDataSize)*(*pDataSize)]; *pMatrixB = new int[(*pDataSize)*(*pDataSize)];
srand(100);
for( int i = 0; i < (*pDataSize)*(*pDataSize);
i++ ) {
(*pMatrixA)[i] = (int) rand()/1000; (*pMatrixB)[i] = (int) rand()/1000;
}
}
}
// параллельное умножение матриц
void ParallelMultiplication ( int *pMatrixA, int *pMatrixB, int **pMatrixC, int DataSize, PROCESS *pProcs, GRIDINFO *Grid ) {
69
// установить параметры решетки
CreateGrid ( pProcs, Grid ); MPI_Datatype MatrixBlock;
// разослать данные
BcastData ( pMatrixA, pMatrixB, DataSize, pProcs, &MatrixBlock );
// перемножить матрицы
MultiplyMatrix ( DataSize,pProcs, Grid, MatrixBlock
);
// собрать данные
GatherData ( pProcs, Grid, *pMatrixC, DataSize, MatrixBlock );
}
// завершение работы
void FreeData ( int *pMatrixA, int *pMatrixB, int DataSize, PROCESS *pProcs ) {
if ( pProcs->ProcRank == 0 ) { delete [] pMatrixA, pMatrixB; }
MPI_Finalize();
}
// установка параметров решетки
void CreateGrid ( PROCESS *pProcs, GRIDINFO *Grid ) { int Dimensions [2];
int WrapAround [2]; int Coordinates[2]; int FreeCoords [2];
Grid->DimGrid = (int)sqrt(pProcs->CommSize); //
порядок решетки
Dimensions [0] = Dimensions [1] = Grid->DimGrid; WrapAround [0] = WrapAround [1] = 1;
// создать решетку
MPI_Cart_create ( MPI_COMM_WORLD, 2, Dimensions, WrapAround , 1, &(Grid->CommGrid));
MPI_Comm_rank ( Grid->CommGrid, &(Grid->RankGrid)
);
MPI_Cart_coords ( Grid->CommGrid, Grid->RankGrid,
2, Coordinates ); |
Grid->NumCol = |
Grid->NumRow = Coordinates[0]; |
|
Coordinates[1]; |
FreeCoords[1] = 1; |
FreeCoords[0] = 0; |
|
// коммуникатор для строк |
|
70
MPI_Cart_sub ( Grid->CommGrid, FreeCoords, &(Grid-
>RowComm) ); |
FreeCoords[1] = 0; |
FreeCoords[0] = 1; |
// коммуникатор для столбцов
MPI_Cart_sub ( Grid->CommGrid, FreeCoords, &(Grid- >ColComm) );
}
// рассылка и прием блоков данных
void BcastData ( int *pMatrixA, int *pMatrixB, int DataSize, PROCESS *pProcs, MPI_Datatype *MatrixBlock ) {
if ( pProcs->ProcRank == 0 ) { // разослать размерность подматриц и сами подматрицы
pProcs->BlockSize = DataSize / (int)sqrt(pProcs- >CommSize);
MPI_Bcast ( &pProcs->BlockSize, 1, MPI_INT, 0, MPI_COMM_WORLD );
// определить тип - блок матрицы
DefineType ( pProcs, (pProcs->BlockSize) * (int)sqrt(pProcs->CommSize), MatrixBlock );
pProcs->pProcMatrixA = pMatrixA; pProcs->pProcMatrixB = pMatrixB;
for ( int NumProc = 1; NumProc < pProcs- >CommSize; NumProc++ ) {
MPI_Send ( &pMatrixA[( NumProc / (int)sqrt(pProcs->CommSize) ) * DataSize * pProcs- >BlockSize + pProcs->BlockSize * ( NumProc % (int) sqrt(pProcs->CommSize) )], 1, *MatrixBlock, NumProc, 1, MPI_COMM_WORLD);
MPI_Send ( &pMatrixB[( NumProc / (int)sqrt(pProcs->CommSize) ) * DataSize * pProcs- >BlockSize + pProcs->BlockSize * ( NumProc % (int) sqrt(pProcs->CommSize) )], 1, *MatrixBlock, NumProc, 1, MPI_COMM_WORLD);
}
}
else { // принять порядок подматриц и сами подматрицы
MPI_Status status;
MPI_Bcast ( &pProcs->BlockSize, 1, MPI_INT, 0, MPI_COMM_WORLD );
// определить тип - блок матрицы