

econometrika / econometrika / Модуль7
.doc
Модуль 7. Прогнозирование
Прогнозирование в регрессионном анализе – одна из важнейших задач моделирования. Прогнозирование может использоваться для предсказания состояния системы в будущем (экстраполяция) или для оценки значения зависимой переменной от некоторого набора независимых, которых нет в исходных наблюдениях (интерполяция). Различают точечное и интервальное прогнозирование. При точечном прогнозе оценкой зависимой переменной будет число, при интервальном – оценкой будет интервал, в котором истинное значение зависимой переменной находится с заданным уровнем вероятности. Для прогноза существенно, являются ли объясняющие переменные и параметры точными значениями или приближенными, имеется ли автокорреляция.
7.1. Прогнозирование в линейной классической модели
Рассмотрим классическую регрессионную модель Y=X + , M[]=0, D[]=2En. Здесь Y=(y1,y2, … , yn) – значения объясняемой переменной в n наблюдениях.
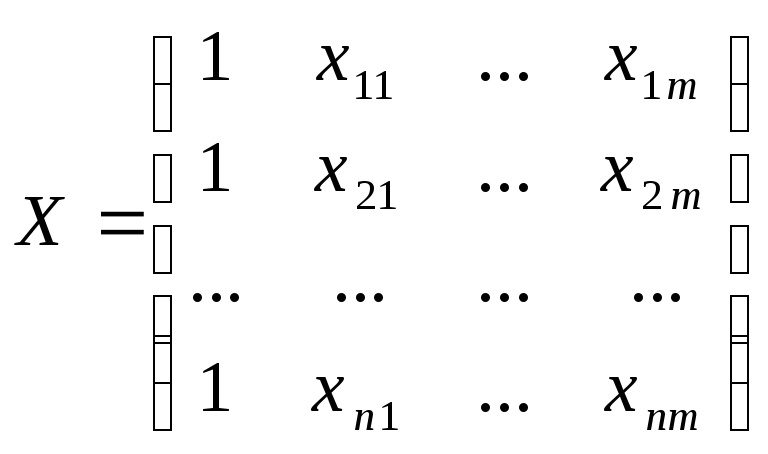 -
матрица значений m
объясняющих переменных в n
наблюдениях.
-
матрица значений m
объясняющих переменных в n
наблюдениях.
Предположим, что точке Xn+1=(xn+1(1),
xn+1(2),
… xn+1(m))
соответствует истинное значение Yn+1=X
n+1T
+ n+1,
тогда как пользуясь регрессионной
моделью, мы можем получить лишь точечный
прогноз
![]() n+1=X
n+1T.
n+1=X
n+1T.
Пусть =(0, 1, … ,m) – вектор параметров модели, значения которых точно известны, а =(1, 2, …, n) – отклонения в модели регрессии с точно известным значением дисперсии 2. В этом случае
M[Yn+1]
= M[X n+1T]
+ M[
n+1]= M[X
n+1T]
= M[![]() n+1],
мы видим что точечный прогноз
n+1],
мы видим что точечный прогноз
![]() n+1
является несмещенной оценкой Yn+1.
Необходимо оценить ошибку прогноза или
отклонение прогнозного значения от
истинного:
n+1
является несмещенной оценкой Yn+1.
Необходимо оценить ошибку прогноза или
отклонение прогнозного значения от
истинного:
D[![]() n+1]
= М[(
n+1]
= М[(![]() n+1
-Yn+1)2]=D[
n+1]=
2.
n+1
-Yn+1)2]=D[
n+1]=
2.
7.1.1. Понятие об интервальном оценивании и доверительных областях
Вычисляя на основании выборочных данных
оценку
![]() n+1=X
n+1T
мы отдаем себе отчет в том, что на
самом деле величина
n+1=X
n+1T
мы отдаем себе отчет в том, что на
самом деле величина
![]() n+1
является лишь приближенным значением
неизвестной величины Yn+1.
Возникает вопрос: как сильно может
отклоняться это приближенное значение
от истинного? В частности, нельзя ли
указать такую величину ,
которая с заранее заданной вероятностью,
близкой к единице, гарантировала бы
выполнение неравенства |
n+1
является лишь приближенным значением
неизвестной величины Yn+1.
Возникает вопрос: как сильно может
отклоняться это приближенное значение
от истинного? В частности, нельзя ли
указать такую величину ,
которая с заранее заданной вероятностью,
близкой к единице, гарантировала бы
выполнение неравенства |
![]() n+1
- Yn+1|
<? Или, что то же,
нельзя ли указать интервал вида (
n+1
- Yn+1|
<? Или, что то же,
нельзя ли указать интервал вида (![]() n+1,1
,
n+1,1
,
![]() n+1,2),
который с заранее заданной вероятностью
(близкой к единице) накрывал бы неизвестное
нам истинное значение Yn+1?
При этом заранее выбираемая исследователем
вероятность обычно называется
доверительной вероятностью, а сам
интервал (
n+1,2),
который с заранее заданной вероятностью
(близкой к единице) накрывал бы неизвестное
нам истинное значение Yn+1?
При этом заранее выбираемая исследователем
вероятность обычно называется
доверительной вероятностью, а сам
интервал (![]() n+1,1
,
n+1,1
,
![]() n+1,2)
– доверительным интервалом или
интервальной оценкой. Ширина доверительного
интервала существенно зависит от объема
выборки n (уменьшается
с ростом n) и от величины
доверительной вероятности (увеличивается
с приближением доверительной вероятности
к единице).
n+1,2)
– доверительным интервалом или
интервальной оценкой. Ширина доверительного
интервала существенно зависит от объема
выборки n (уменьшается
с ростом n) и от величины
доверительной вероятности (увеличивается
с приближением доверительной вероятности
к единице).
Пусть случайная величина Z подчинена стандартному нормальному закону распределения ZN(0,1), тогда можно записать Prob(|Z|<t/2)= 1-. Здесь 1- – доверительная вероятность, а t/2 – критическое значение ( - квантиль), соответствующий . Эта запись эквивалентна интервальной оценке Z (-t/2 , +t/2) с доверительной вероятностью 1-.
Если случайная величина X подчинена нормальному закону распределения XN(,), тогда можно записать Prob(|(X- ) / |<t/2)= 1- (см. 2.6.3), а следовательно, интервальная оценка для примет вид: X(-t/2 , +t/2).
7.1.2 Интервальная оценка в прогнозировании
Если ошибка нормально распределена, то интервальная оценка
Yn+1
(![]() n+1
-t;
n+1
-t;
![]() n+1+
t),
где t
- двусторонняя
- квантиль стандартного нормального
распределения. С вероятностью 1-
истинное значение Yn+1
окажется в данном интервале.
n+1+
t),
где t
- двусторонняя
- квантиль стандартного нормального
распределения. С вероятностью 1-
истинное значение Yn+1
окажется в данном интервале.
Пусть вектор параметров модели =(0,
1,
… ,m)
и отклонения =(1,
2,
…, n)
– неизвестны, а есть только оценки
а=(а0, а1,
… ,аm) и se2
– оценки, полученные методом наименьших
квадратов (см.4.1.2, ):
![]() и
и
![]() .
.
В этом случае как и в предыдущем точечный прогноз Ŷn+1=X n+1Tа является несмещенной оценкой истинного значения Yn+1. Действительно M[a]=, тогда
M[![]() n+1]
= M[X n+1Tа]
= X n+1T
M[а] = M[X
n+1T.]
+ M[
n+1]=
M[Yn+1].
n+1]
= M[X n+1Tа]
= X n+1T
M[а] = M[X
n+1T.]
+ M[
n+1]=
M[Yn+1].
Важно, что полученная оценка является эффективной, то есть обладает наименьшей дисперсией.
7.1.3. Дополнительно
Утверждение: Предположим, что
![]() -
некая несмещенная оценка величины Yn+1.
Тогда необходимо доказать, что
-
некая несмещенная оценка величины Yn+1.
Тогда необходимо доказать, что
![]() .
.
Доказательство:
![]() .
Здесь мы использовали тождество
.
Здесь мы использовали тождество
![]() в силу несмещенности новой оценки.
Рассмотрим дисперсию этой оценки:
в силу несмещенности новой оценки.
Рассмотрим дисперсию этой оценки:
![]()
Покажем, что
![]() .
Раскроем скобки и воспользуемся тем,
что
.
Раскроем скобки и воспользуемся тем,
что
![]() и
и
![]() n+1=X
n+1Tа,
а Yn+1=X
n+1T
+ n+1
n+1=X
n+1Tа,
а Yn+1=X
n+1T
+ n+1
![]() Рассмотрим
первое слагаемое
Рассмотрим
первое слагаемое
![]()
так как Yn+1=X
n+1T
+ n+1,
то
![]() .
Окончательно для первого слагаемого
получаем:
.
Окончательно для первого слагаемого
получаем:
![]()
Рассмотрим второе слагаемое
![]()
Третье слагаемое
![]()
Четвертое слагаемое
![]()
Таким образом, утверждение доказано.
Найдем дисперсию
![]() n+1:
n+1:
![]()
Заменим 2
на se2
, и введем обозначение
![]() .
Если ошибки (,n+1)
имеют совместное нормальное распределение,
то случайная величина (
.
Если ошибки (,n+1)
имеют совместное нормальное распределение,
то случайная величина (![]() n+1
- Yn+1)/
имеет распределение Стьюдента с n-m-1
степенями свободы. Поэтому доверительным
интервалом для Yn+1
с уровнем значимости
будет интервал (
n+1
- Yn+1)/
имеет распределение Стьюдента с n-m-1
степенями свободы. Поэтому доверительным
интервалом для Yn+1
с уровнем значимости
будет интервал (![]() n+1
– t
,
n+1
– t
,
![]() n+1
+ t),
где где t
- двусторонняя
- квантиль распределения Стьюдента
с n-m-1
степенями свободы.
n+1
+ t),
где где t
- двусторонняя
- квантиль распределения Стьюдента
с n-m-1
степенями свободы.
7.2. Прогнозирование при наличии авторегрессии ошибок
Рассмотрим задачу прогнозирования, когда ошибки в исходной модели коррелированы по времени, а именно, образуют авторегрессионный процесс первого порядка. В этом случае связь ошибки в моменты времени i и i-1 выглядит следующим образом:
![]()
Здесь i, i= 1, … , n - последовательность независимых нормально распределенных случайных величин с нулевым средним и постоянной дисперсией 2, а ||<1 – коэффициент авторегрессии.
Предположим, что параметры и известны.
Истинное значение
Yn+1=X n+1T + n+1= X n+1T + n+ n+1 = X n+1T + (Yn-XnT )+ n+1
В качестве оценки Yn+1
возьмем не
![]() n+1=X
n+1T
как раньше, а
n+1=X
n+1T
как раньше, а
![]() n+1=X
n+1T+
n=
X n+1T
+ (Yn-XnT
).
n+1=X
n+1T+
n=
X n+1T
+ (Yn-XnT
).
Очевидно е = Yn+1
-
![]() n+1=
n+1,
следовательно M[e]=0,
D[e]=
2
n+1=
n+1,
следовательно M[e]=0,
D[e]=
2
Сравним дисперсии ошибок для обычной
оценки
![]() n+1=X
n+1T:
D[
n+1]=
2 , и для оценки
n+1=X
n+1T:
D[
n+1]=
2 , и для оценки
![]() n+1=X
n+1T+
n:
D[e]=
2.
n+1=X
n+1T+
n:
D[e]=
2.
2 = D[ n+1]= D[ n + n+1]=M[( n + n+1)2] =
= M[( n)2] + M[ n+12] + 2M[ n n+1] =2 2+2 > 2
Последнее слагаемое равно нулю в силу независимости n и n+1. Таким образом, удается уменьшить ошибку прогноза по сравнению со случаем некоррелированных ошибок 2 =2/( 1- 2).
Реально значения и неизвестны, поэтому при прогнозировании величины Yn+1 их заменяют оценками a и r:
![]() n+1=
= X n+1Ta+
r(Yn-XnT
a).
n+1=
= X n+1Ta+
r(Yn-XnT
a).
7. Вопросы
-
Какие виды прогноза вы знаете?
-
В чем отличие точной и интервальной оценки?
-
Какими характеристиками случайной величины определяется интервальная оценка?
-
В каких моделях подстановка значения х в уравнение регрессии дает смещенную оценку прогнозного значения у?
-
Что такое доверительный интервал?