

Лабораторная работа 1 ed
.docЛабораторная работа №1.
Описание функциональной зависимости для данного экспериментального распределения.
Математическое понятие, отражающее связь между элементами множеств, называется функцией. Функция – это правило, по которому каждому элементу одного множества (называемого областью определений) ставится в соответствие некоторый элемент другого множества (области значений). В случае, когда можно предполагать зависимость одних данных (например, ряда Y) от других (например, от переменных X), можно говорить о существовании некоторой функциональной зависимости, которая записывается в общем виде, как Y = Y(X).
Виды функциональной зависимости: линейная, степенная, экспоненциальная, логарифмическая, гармоническая (синус, косинус) и т.д.
Обработка экспериментальных данных часто сопряжена с необходимостью построить математическую модель изучаемого процесса (явления) на основе имеющейся выборки. Под математической моделью здесь понимается построение некоторой функциональной зависимости, согласующейся с данными выборки, так чтобы можно было определить недостающие элементы, провести интерполяцию или экстраполяцию данных.
Такая модель в первом приближении называется трендом или функцией тренда. Тренд – гладкая функция, описывающая долгосрочное поведение временного ряда. Функция тренда аппроксимирует исследуемый ряд данных. Аппроксимация – приближенное решение (замена) сложной функции с помощью более простых, что резко ускоряет и упрощает процедуру обработки данных или решения задач. Аппроксимация позволяет исследовать числовые характеристики и качественные свойства объекта, сводя задачу к изучению более простых или более удобных объектов. Успешность аппроксимации (или адекватность выбранной функциональной зависимости) позволяет оценить Коэффициент достоверности аппроксимации (R2) – степень соответствия математической модели, выбранной в качестве тренда, исходным данным (выборке). Коэффициент достоверности аппроксимации определяется из соотношения:
R2 = 1 – σ/σy
где σ и σy – стандартное отклонение в исходном ряду данных и в ряду интерполированных значений. Если R2 стремится к 1, то достоверность аппроксимации высока.
1. Используйте для работы приведенную таблицу данных, либо любое альтернативное экспериментальное распределение (при работе по вариантам можно приплюсовать к значениям показателя по одной из цифр телефонного номера).
|
№ наблюдения |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
18 |
25 |
|
значение показателя |
0,21 |
0,52 |
0,59 |
0,72 |
0,88 |
1,01 |
1,04 |
0,98 |
0,95 |
1,01 |
1,11 |
1,22 |
1,26 |
1,20 |
1,14 |
1,12 |
|
|
|
Расчетные значения на основе выбранной функции |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2. Постройте точечный график данного распределения.
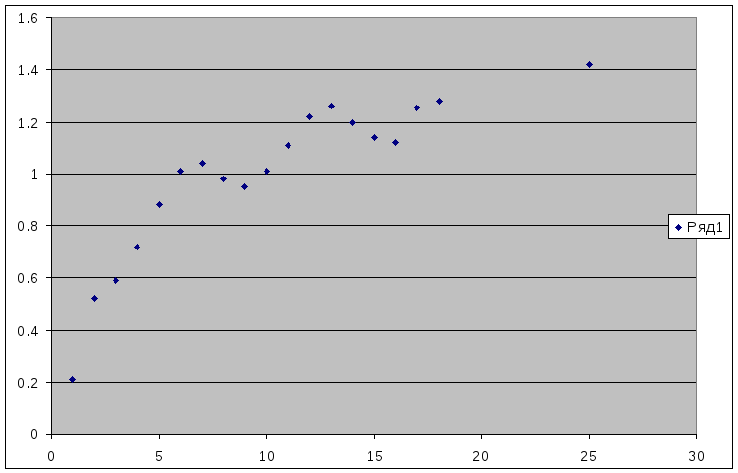
3. Дайте характеристику возможной функции, описывающей данное распределение.
4. Выберите две (или более) функций с помощью процедуры подбора тренда к графику.
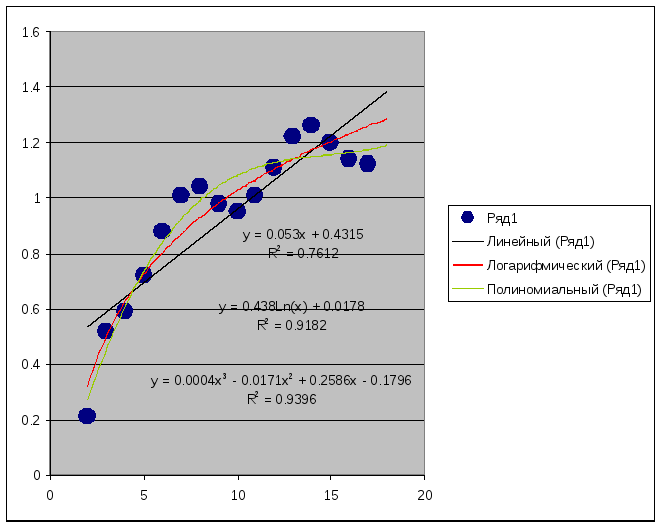
5. Оцените достоверность выбранной функциональной зависимости (R2).
Для линейного распределения R2=0.7612: Для логарифмического R2=0.9182: Для полиномиального R2=0.9396
6. Определите прогнозируемые значения для двух последних элементов заданного ряда.
|
№ наблюдения |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
25 |
|
значение показателя |
0.21 |
0.52 |
0.59 |
0.72 |
0.88 |
1.01 |
1.04 |
0.98 |
0.95 |
1.01 |
1.11 |
1.22 |
1.26 |
1.2 |
1.14 |
1.12 |
1.25 |
1.28 |
1.42 |
7. Проведите вычисления показателя для заданного ряда с помощью выбранной функции аппроксимации.
|
Расчетные значения на основе выбранной функции |
0.08 |
0.28 |
0.45 |
0.602 |
0.727 |
0.83 |
0.92 |
0.98 |
1.034 |
1.071 |
1.095 |
1.109 |
1.11 |
1.112 |
1.104 |
1.094 |
1.08 |
1.07 |
1.14 |
8. Сделайте оформление работы, пройдите процедуру защиты работы.
________________________________
Вопросы к зачету:
-
Что такое функция распределения?
-
Что такое график тренда?
-
Каким образом можно определить недостающие элементы рассматриваемой выборки?